 srcmini
srcmini本文概述
数据挖掘使用诸如统计模型, 机器学习和可视化之类的工具从大数据中“挖掘”(提取)有用的数据和模式, 而大数据则处理高容量和高速度的数据, 而在这种情况下很难做到这一点。较旧的数据库和分析程序。
大数据
大数据是指可以以TB字节为单位的大量结构化, 半结构化和非结构化数据集。在单个系统上处理大量数据具有挑战性, 这就是为什么我们的计算机的RAM在处理和分析过程中存储临时计算的原因。当我们尝试处理如此大量的数据时, 需要花费大量时间在单个系统上执行这些处理步骤。另外, 由于过载, 我们的计算机系统无法正常工作。
在这里, 我们将通过一个实例来了解概念(产生多少数据)。我们都知道大市集。作为客户, 我们每月至少去一次大市集。这些商店监视着客户从他们那里购买的每种产品, 以及在世界上哪个商店的位置。他们有一个实时的信息提供系统, 可以将所有数据存储在大型中央服务器中。想象一下, 仅在印度, 大型集市商店的数量就约为250家。监视每位客户购买的每件商品以及商品说明, 可使数据在一个月内达到1 TB左右。

大市集如何处理这些数据
我们知道一些商品正在大巴扎(Big Bazaar)进行促销。我们是否真的相信Big Bazaar会在没有任何充分支持的情况下运行这些产品, 以发现这些促销活动会增加其销售并产生盈余?那就是大数据分析起着至关重要的作用。 Big Bazaar使用数据分析技术, 针对其新客户和现有客户, 从其商店购买更多商品。
大数据由5V组成, 即体积, 多样性, 速度, 准确性和价值。
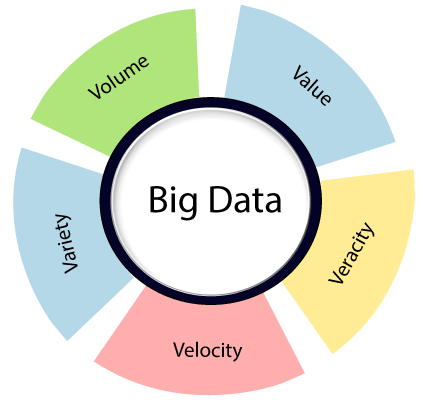
容量:在大数据中, 容量是指涉及大数据的大量数据。
多样性:在大数据中, 多样性是指各种类型的数据, 例如Web服务器日志, 社交媒体数据, 公司数据。
速度:在大数据中, 速度是指数据随时间增长的方式。通常, 数据以非常快的速度呈指数增长。
准确性:大数据准确性是指数据的不确定性。
价值:在大数据中, 价值指的是我们正在存储的数据, 而处理是否有价值, 以及我们如何利用这些巨大的数据集。
如何处理大数据
一种非常有效的方法, 称为Hadoop, 主要用于大数据处理。它是一种开源软件, 适用于分布式并行处理方法。
Apache Hadoop方法由给定的模块组成
Hadoop常见:
它包含其他Hadoop模块所需的字典和实用程序。
Hadoop分布式文件系统(HDFS):
一种将文件存储在商用机器上的分布式文件系统, 在群集上支持很高的总带宽。
Hadoop纱:
它是一个资源管理平台, 负责管理集群中的各种资源并将其用于调度用户的应用程序。
Hadoop MapReduce:
它是用于大规模数据处理的编程模型。
数据挖掘
顾名思义, 数据挖掘是指挖掘大型数据集以识别趋势, 模式并提取有用信息的过程, 即数据挖掘。
在数据挖掘中, 我们正在寻找隐藏的数据, 但对寻找的确切数据类型以及一旦找到数据我们打算使用什么数据一无所知。当发现有趣的信息时, 我们开始考虑如何利用它来促进业务发展。
我们将通过一个示例来理解数据挖掘的概念:
数据挖掘者开始发现移动网络运营商的呼叫记录, 而他的经理没有任何特定目标。经理可能给他一个重要的目标, 以便在一个月内发现至少一些新模式。当他开始提取数据时, 发现一种模式, 与其他所有几天相比, 在星期五(例如)有一些国际电话。现在, 他与管理层分享了这些数据, 他们提出了一项在周五降低国际通话费率并开始竞选的计划。呼叫持续时间变长, 客户对低呼叫率感到满意, 更多的客户加入, 随着利用率的提高, 组织获得了更多的利润。
数据挖掘涉及多个步骤:

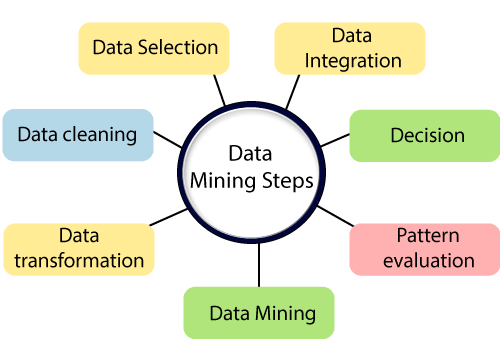
数据整合:
在第一步中, 将数据集成并从各种来源收集数据。
数据选择:
第一步, 我们可能不会同时收集所有数据, 因此, 在这一步中, 我们仅选择剩余的数据, 我们认为这对数据挖掘很有用。
数据清理:
在此步骤中, 我们收集的信息不是干净的, 可能包含错误, 嘈杂或不一致的数据, 缺少值。因此, 我们需要实施各种策略来消除此类问题。
数据转换:
即使清理后的数据也没有准备好进行挖掘, 因此我们需要将其转换为挖掘结构。实现此目的的方法是聚合, 规范化, 平滑等。
数据挖掘:
数据转换后, 我们准备对数据实施数据挖掘方法, 以从数据集中提取有用的数据和模式。诸如群集关联规则之类的技术是用于数据挖掘的多种技术中的一种。
模式评估:
Patten评估包含可视化, 从我们生成的模式中删除随机模式, 转换等。
决定:
这是数据挖掘的最后一步。它可以帮助用户利用所获取的用户数据来做出更好的数据驱动决策。
数据挖掘与大数据之间的区别

| 数据挖掘 | 大数据 |
|---|---|
| 它主要针对数据分析以提取有用的信息。 | 它主要针对数据关系。 |
| 它可以用于大容量和小容量数据。 | 它包含大量数据。 |
| 这是一种主要用于数据分析的方法。 | 这是一个整体概念, 而不是一个简短的术语。 |
| 它主要基于统计分析, 通常以目标预测为基础, 并以小规模发现业务因素。 | 它主要基于数据分析, 通常基于目标预测, 并大规模发现业务因素。 |
| 它使用以下数据类型, 例如结构化数据, 关系数据库和维度数据库。 | 它使用以下数据类型, 例如结构化, 半结构化和非结构化数据。 |
| 它表示有关数据的内容。 | 它指的是数据的原因。 |
| 它是数据的最接近视图。 | 它是数据的广阔视野。 |
| 它主要用于战略决策目的。 | 它主要用于仪表板和预测性措施。 |
评论前必须登录!
注册