 srcmini
srcmini本文概述
决策树是一种监督学习方法, 用于数据挖掘中的分类和回归方法。它是一棵帮助我们决策的树。决策树将分类或回归模型创建为树结构。它将数据集分成较小的子集, 同时稳定地开发了决策树。最终的树是具有决策节点和叶节点的树。决策节点至少具有两个分支。叶节点显示分类或决策。我们无法在叶节点上完成更多拆分-树中与最佳预测变量(称为根节点)相关的最高决策节点。决策树可以处理分类数据和数字数据。
关键因素
熵:
熵是指测量杂质的常用方法。在决策树中, 它测量数据集中的随机性或杂质。
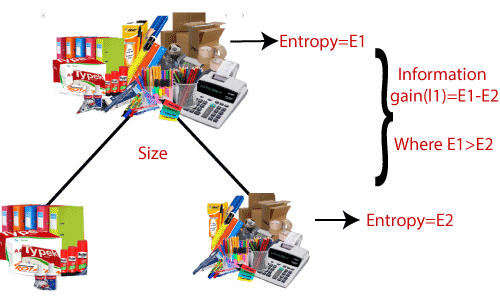
信息增益:
信息增益是指数据集拆分后熵的下降。也称为熵降低。建立决策树就是要发现返回最高数据增益的属性。
简而言之, 决策树就像流程图, 终端节点显示决策。从数据集开始, 我们可以测量熵, 以找到一种分割集合的方法, 直到数据属于同一类。
为什么决策树有用?
它使我们能够全面分析决策的可能后果。
它为我们提供了一个衡量成果价值及其实现可能性的框架。
它可以帮助我们根据现有数据和最佳推测做出最佳决策。
换句话说, 我们可以说决策树是一种层次树结构, 可通过实现一系列简单的决策规则来将记录的广泛集合拆分为较小的类集。决策树模型包含一组规则, 用于将庞大的异类总体划分为更小, 更同质或互斥的类。类的属性可以是标称, 有序, 二进制和定量值中的任何变量, 相反, 这些类必须是定性类型, 例如分类或有序或二进制。简而言之, 在给定的属性数据及其类的基础上, 决策树创建了一组可用于识别类的规则。一个规则接一个地执行, 从而导致了一个段内段的层次结构。层次结构称为树, 每个段称为节点。随着每个渐进式划分, 后续集合中的成员变得越来越相似。因此, 用于构建决策树的算法称为递归分区。该算法称为CART(分类树和回归树)
考虑给定的工厂示例
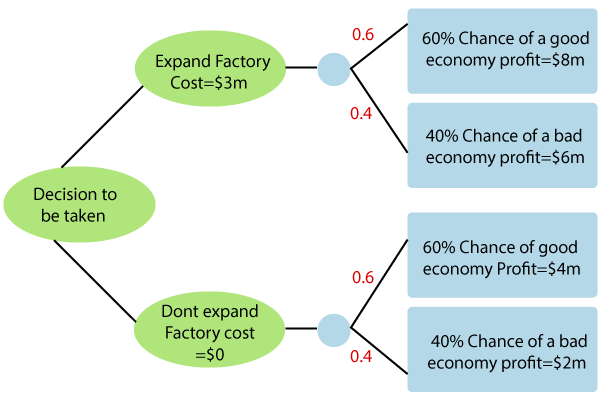
扩展因子的成本为300万美元, 良好经济的可能性为0.6(60%), 这将带来800万美元的利润, 而不良经济的可能性为0.4(40%), 这将导致600万美元的利润。
如果不使用成本0来扩展因子, 则良好经济的概率为0.6(60%), 这将导致400万美元的利润, 而糟糕经济的概率为0.4, 这将导致200万美元的利润。
管理团队需要根据给定的数据做出数据驱动的决定来扩展或不扩展。
净扩展=(0.6 * 8 + 0.4 * 6)-3 = $ 4.2M净未扩展=(0.6 * 4 + 0.4 * 2)-0 = $ 3M $ 4.2M> $ 3M, 因此应该扩展工厂。
决策树算法
决策树算法可能看起来很长, 但是很简单, 其基础算法技术如下:
该算法基于三个参数:D, attribute_list和Attribute_selection_method。
通常, 我们将D称为数据分区。
最初, D是整个训练元组及其相关班级级别(输入训练数据)的集合。
参数attribute_list是定义元组的一组属性。
Attribute_selection_method指定一种启发式过程, 用于选择“最佳”根据类别区分给定元组的属性。
Attribute_selection_method进程应用属性选择度量。
使用决策树的优势
决策树不需要信息缩放。
数据中的缺失值也不会在很大程度上影响构建选择树的过程。
决策树模型是自动的, 易于向技术团队和利益相关者解释。
与其他算法相比, 决策树在预处理期间需要较少的精力进行数据准备。
决策树不需要数据标准化。
评论前必须登录!
注册