 srcmini
srcmini本文概述
星型模式是维模型的基本形式, 其中数据被组织为事实和维。事实是指经过计数或衡量的事件, 例如销售或登录。维度包括有关该事实的参考数据, 例如日期, 项目或客户。
星型模式是一种关系模式, 其中其设计表示多维数据模型的关系模式。星型模式是显式数据仓库模式。之所以称为星型模式, 是因为这种模式的实体关系图模拟了一个星形, 其点与中心表的位置不同。模式的中心由一个较大的事实表组成, 星形点是维度表。
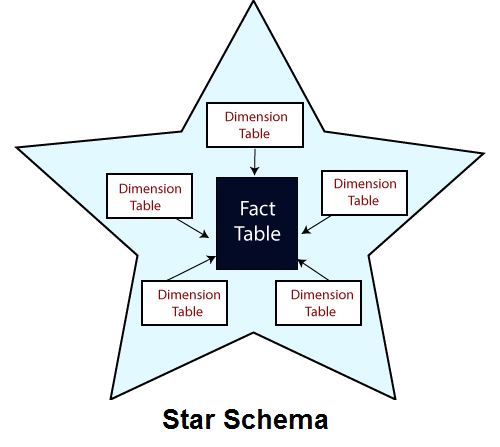
事实表
星型模式中的表格, 其中包含事实并与维相关。事实表具有两种类型的列:包含事实的列和作为维表的外键的列。事实表的主键通常是由其所有外键组成的组合键。
事实表可能涉及详细级别事实或已汇总的事实(通常将包含汇总事实的事实表称为汇总表)。事实表通常包含具有相同聚合级别的事实。
尺寸表
维度是通常由一个或多个对数据进行分类的层次结构组成的体系结构。如果维度没有层次结构和级别, 则称为平面维度或列表。每个维度表的主键都是事实表的组合主键的一部分。尺寸属性有助于定义尺寸值。它们通常是描述性的文本值。尺寸表通常比事实表小。
事实表存储有关销售的数据, 而维度表数据存储有关地理区域(市场, 城市), 客户, 产品, 时间, 渠道的数据。
星型图的特征
由于具有以下功能, 星型模式非常适合数据仓库数据库设计:
- 它创建了一个DE规范化的数据库, 可以快速提供查询响应。
- 它提供了一种灵活的设计, 可以随数据库的增长轻松地更改或添加到整个开发周期中。
- 它为最终用户通常如何考虑和使用数据提供了并行的设计。
- 它为开发人员和最终用户降低了元数据的复杂性。
星型架构的优点
最终用户和应用程序易于理解和浏览星型架构。通过精心设计的架构, 客户可以立即分析大型的多维数据集。
决策支持环境中星形模式的主要优点是:
查询效果
星型模式数据库的表和清晰的连接路径数量有限, 查询运行的速度比对OLTP系统的查询速度快。小型单表查询(通常是维表)几乎是瞬时的。包含多个表的大型联接查询只需要几秒钟或几分钟即可运行。
在星型数据库设计中, 维仅通过中央事实表连接。在查询中使用二维表时, 在这两个表之间仅存在一个与事实表相交的连接路径。此设计功能可强制执行可靠且一致的查询结果。
负载性能和管理
结构简单性还减少了将大量记录加载到星型模式数据库中所需的时间。通过描述事实和维度并将它们分为不同的表格, 可以减少负载结构的影响。维度表可以填充一次, 偶尔刷新。我们可以通过将记录追加到事实表中来定期有选择地添加新事实。
内置参照完整性
加载信息时, 星型架构具有内置的参照完整性。由于维表中的每个数据都有唯一的主键, 并且事实表中的所有键都是从维表中提取的合法外键, 因此强制执行引用完整性。事实表中与维度没有正确关联的记录无法获得要检索的正确键值。
容易理解
星型模式易于理解和浏览, 其维度仅通过事实表进行连接。这些联接对于最终用户而言更为重要, 因为它们代表了基础业务各部分之间的基本关系。客户还可以在构造查询之前浏览维度表属性。
星图的缺点
星型模式无法满足某些条件, 例如用户之间的关系, 并且银行帐户无法描述为星型模式, 因为它们之间的关系是多对多的。
示例:假设星型架构由事实表, 销售和与之连接的多个维度表组成, 这些表涉及时间, 分支, 项目和地理位置。
TIME表的每一天, 每月, 每季度和每年都有一列。 ITEM表具有每个item_Key, item_name, 品牌, 类型, supplier_type的列。 BRANCH表具有每个branch_key, branch_name, branch_type的列。 LOCATION表包含地理数据列, 包括街道, 城市, 州和国家。
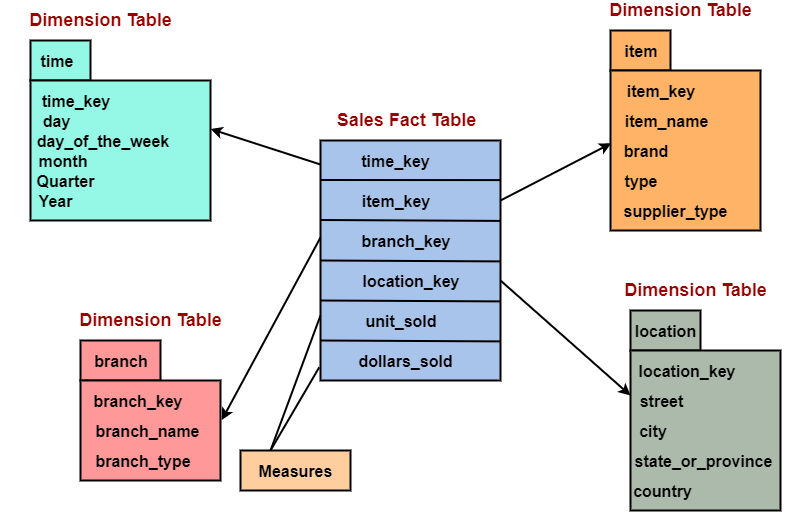
在这种情况下, SALES表仅包含来自维表TIME, ITEM, BRANCH和LOCATION的ID的四列, 而不是用于时间数据的四列, 用于ITEM数据的四列, 用于BRANCH数据的三列和四列用于LOCATION数据。因此, 事实表的大小显着减小。当我们需要更改项目时, 只需要在维度表中进行一次更改, 而无需在事实表中进行许多更改。
通过将维度表标准化为几个表, 我们可以创建甚至更复杂的星形模式。标准化尺寸表称为雪花。
评论前必须登录!
注册