 srcmini
srcmini接上一节:预处理指令和C函数库
数据结构和算法是C语言的主要内容,更特别在于C语言的数据结构和算法一般需要自己实现,与OOP语言不同,C标准库中没有提供相关的数据结构。Linux C标准库原为Linux Libc,现在常用的是GLibc,即GNU C Library,另外可用的库还有GTK的库Glib,POSIX标准库Gnulib,其中Glib中提供有完整的数据结构和相关算法操作。本文详细讨论C数据结构的标准定义及其算法实现,自定义实现的一个好处是时数据表示更加灵活,前提是数据结构和算法的设计要标准,通常自定义结合其它库开发会更有效率。
一、抽象数据类型(ADT)
抽象数据类型是基本数据类型复合而来的类型,基本数据类型包括数据的存储方式以及操作方式(运算符),抽象数据类型同样也有,而且这是抽象数据类型的最基本表示形式,这里先讨论ADT的数据结构和算法操作的标准定义形式,其它例如链表、队列、二叉树、栈等都可以使用这些标准形式。
抽象数据类型在外部应以容器看待,所以核心的问题就变成容器的设计了。
1、基本信息
抽象数据类型一般使用一个结构体表示,最基本需要有数据属性,即结构体成员数据。
算法操作类似运算符,算法操作是数据自身的运算规则,操作对象包括:成员数据和结构体对象本身。常见的操作有两种,一种是很直接的从需求中抽象而来,这种需要按情况而定。
另一种则是标准操作,详细有一般数据操作:增加、删除、修改、查找和排序;生命周期操作:初始化、释放(清空);高级操作:在任意位置插入项、移除任意位置的项、替换项、容器的项个数、判断容器是否为空、判断容器是否已满(或判断空间是否足够)。
2、创建接口(.h)
(1)数据存储方式
在这里我们的目的是设计一个容器,如果你用过OOP中的容器那会容易理解一些,主要包括容器本身以及一般的业务数据对象,首先是一般的业务数据,这种数据对象是直接的需求数据,也就是不是固定的,不同需求有不同的表现形式,一般都是使用结构体定义,如下代码:
// 一般数据[自定义]:一般的业务数据,不同需求定义不同的数据形式
struct food{ // 食品
char name[256]; // 名称
float price; // 价格
};
typedef struct food Item;
以上定义是一般性的,不是固定的定义,下面介绍的具有普遍性,面向容器设计,首先需要定义容器中的数据单元,在C语言中这个数据单元又可称为抽象结点Node,使用一个结构体定义,这个抽象结点用于保存上面的业务数据Item,特定数据结构的主要表示工具(例如链表和二叉树在这里会有不同的形式),下面以链表举例,如下代码:
// 抽象结点:数据的基本单元
struct node{
Item *item; // 可用void *表示存储任意类型的数据对象
struct node *next; // 下一个数据单元的地址
};
typedef struct node Node;
可能会有人将Node和Item合并来写,也是可以的,或者会有人写到这步就要开始创建接口并实现了,然后将头指针和容器大小变量直接写在外部了,麻烦有很多,这里采取一种简单的方式,使用一个结构体封装头指针等这些必要信息,这样我们只需要这个结构体就可以操作容器中的所有元素了,可以说这个结构体表示了整个抽象数据类型(如链表)的接口了,类似于OOP中的类,数据成员主要是特定数据结构必要的一些全局信息,比如链表需要的头指针、尾指针和项数,定义形式如下:
// 标准数据类型接口:代表特定数据结构的所有数据,一种抽象数据类型模板
struct linkedlist{
Node *head;
Node *tail;
unsigned int size;
};
typedef struct linkedlist LinkedList;
一般数据、数据单元和标准接口,以上的表示形式是数据结构和算法的一个重点内容,特别是标准接口,如果没有这个那么操作就不会那么理想了。另外一个难点内容就是算法实现,可能会用到解决方式是while循环和递归调用,其中递归调用不推荐使用,一来是理解困难,二来内存使用过大,而while循环也容易看明白,而且执行完一次循环后会释放掉空间。
(2)算法操作
下面是算法操作函数的定义,其中要注意const和restrict关键字的使用,const表示传入的数据不允许修改,而restrict表示该指针是访问数据对象唯一且最初的方式。另外函数声明时推荐写好函数注释,注释至少包括:函数功能说明、函数参数说明和函数返回值说明。首先说明,有一个初始化的函数接口一般都是有的,完整声明如下:
/**
* @description 初始化链表为空
* @param linkedList 链表指针,需要已分配内存空间
* @return 返回空
* */
extern void list_init(LinkedList * restrict list);
/**
* @description 添加一个元素到链表中
* @param list 链表指针
* @param item 数据单元Food
* @return true:添加成功,false: 添加失败
* */
extern bool list_add(LinkedList *list, Item *item);
/**
* @description 获取链表中指定名称的第一个元素
* @param list 链表指针
* @param name Food的名称
* @return 获取到的Food,找不到返回NULL
* */
extern Item* list_get_by_name(const LinkedList *list, char *name);
/**
* @description 清空链表
* @param list 链表指针
* @return 返回空
* */
extern void list_clear(LinkedList * list);
(3)实现接口(.c)
在实现文件中如果还需要额外的函数支持,可使用static声明,类似于OOP中的private,完整实现代码如下:
void list_init(LinkedList *list){
list->size = 0;
list->head = NULL;
list->tail = NULL;
}
bool list_add(LinkedList *list, Item *item){
Node *node = (Node *)malloc(sizeof(Node));
Item *new_item = (Item *)malloc(sizeof(Item));
strcpy(new_item->name, item->name);
new_item->price = item->price;
if(!node)
return -1;
node->item = new_item;
node->next = NULL;
if(list->head == NULL){
list->head = node;
list->tail = node;
list->size++;
}
else{
list->tail->next = node;
list->tail = node;
list->size++;
}
return 1;
}
Item* list_get_by_name(const LinkedList *list, char *name){
Node *node = list->head;
while (node != NULL){
if(strcmp(name, node->item->name) == 0)
return node->item;
node = node->next;
}
return NULL;
}
void list_clear(LinkedList * list){
Node *node = list->head;
while (node != NULL){
Node *temp = node->next;
free(node);
node = temp;
}
list->size = 0;
list->head = NULL;
list->tail = NULL;
free(list);
}
(4)使用接口
对于接口设计得好不好,主要体现在使用上,最好的方式莫过于OOP那样的调用了,在这里list_init这个函数可以改进,可以增加让该函数负责创建list,这样就不用再外部malloc了,然后让list_init函数返回相应的指针,下面是接口使用的代码:
// 初始化容器
LinkedList *list = (LinkedList *)malloc(sizeof(LinkedList));
list_init(list);
Item item1;
strcpy(item1.name, "Apple");
item1.price = 12.6;
Item item2;
strcpy(item2.name, "Pear");
item2.price = 30.94;
Item item3;
strcpy(item3.name, "Meat");
item3.price = 28.39;
// 添加数据到容器中
list_add(list, &item1);
list_add(list, &item2);
list_add(list, &item3);
// 在容器中查找数据
Item *pitem = list_get_by_name(list, "Meat");
if(pitem){
printf("name: %s\n", pitem->name);
printf("price: %.2f\n", pitem->price);
}
// 记得释放容器中的数据
list_clear(list);
二、数组和动态数组
数组一般是一次性分配足够的空间,连续存储数据,可以随机访问数据,最大的确定就是插入和删除元素费时,需要频繁地移动其它数据项,但数组适用于经常性查找的场景中。对于数组查找,一般来说有两种方式,顺序查找,可先排序再查找,另一种是二分法查找,同样需要结合排序,快速排序可使用qsort。
一般的数组是存储在栈内存中,这类数组长度固定,而且内存自由度不大。动态数组则是在堆中储存,同时长度可变长,这里以动态数组为主,数组的一般内存结构如下图:
1、数据接口表示
数据接口表示包括数据表示、算法操作,在实际使用中即使是动态数组仍然不能简单地使用malloc进行实现,仍然需要按照标准形式,一般数据、数据单元和抽象接口,完整代码如下:
// 一般数据类型:日志信息
typedef struct log{
char *date;
char message[256];
} Log;
// 数据单元:已分配内存数组的一个单元,因没有额外的信息,可直接写在标准接口中
// 标准接口
typedef struct arraylist{
unsigned int dfsize; // 数组默认初始化大小,若不指定默认为10
unsigned int size; // 数组长度
Log *array; // 数组指针
} ArrayList;
/**
* @description 创建并初始化数组容器
* @param dfsize 默认数组初始化大小
* @return 新创建的数组容器
* */
extern ArrayList* alist_init(unsigned int dfsize);
/**
* @description 添加元素到数组中
* @param list 数组指针
* @param log 数据元素指针
* @return 添加成功返回true,失败返回false
* */
extern bool alist_add(ArrayList *list, Log *log);
/**
* @description 将数组的每个元素都执行同一个函数plog
* @param list 数组指针
* @param plog 函数指针
* @return 返回空
* */
extern void alist_logs(const ArrayList *list, void (*plog)(Log *));
/**
* @description 清空数组,不能再使用list访问数据
* @param list 数组指针
* @return 返回空
* */
extern void alist_clear(ArrayList *list);
2、接口实现
ArrayList* alist_init(unsigned int dfsize){
if(dfsize < 1)
dfsize = 2;
ArrayList *list = (ArrayList*)malloc(sizeof(ArrayList));
list->dfsize = dfsize;
list->size = 0;
Log *array = (Log*)malloc(dfsize * sizeof(Log));
list->array = array;
return list;
}
bool alist_add(ArrayList *list, Log *log){
if(list->size >= list->dfsize){
list->dfsize += 2;
list->array = (Log*)realloc(list->array, list->dfsize * sizeof(Log));
}
Log *ele = list->array + list->size;
ele->date = log->date;
strcpy(ele->message, log->message);
list->size++;
return true;
}
void alist_logs(const ArrayList *list, void (*plog)(Log *)){
for (int i = 0; i < list->size; ++i) {
plog(list->array + i);
}
}
void alist_clear(ArrayList *list){
free(list->array);
list->array = NULL;
list->size = 0;
list->dfsize = 10;
free(list);
}
3、使用接口
ArrayList *arrayList = alist_init(0);
Log log1;
log1.date = local_date();
strcpy(log1.message, "AppleWebkit Chrome Mac");
Log log2;
log2.date = local_date();
strcpy(log2.message, "Ubuntu Linux Safari");
Log log3;
log3.date = local_date();
strcpy(log3.message, "Webkit Windows Chrome");
alist_add(arrayList, &log1);
alist_add(arrayList, &log2);
alist_add(arrayList, &log3);
alist_logs(arrayList, logs);
alist_clear(arrayList);
三、链表
链表的具体示例在上面介绍抽象数据类型(ADT)中,其主要特点是,一次分配一个数据空间,在堆中分散存储数据,只能进行顺序访问,不能随机访问,而且也不方便查找,只能使用顺序查找,所以链表不适用于经常性查找的场景,但是使用链表可以快速插入和删除数据,所以如果不是经常性遍历的情况都可以使用链表,链表的一般形式如下图:
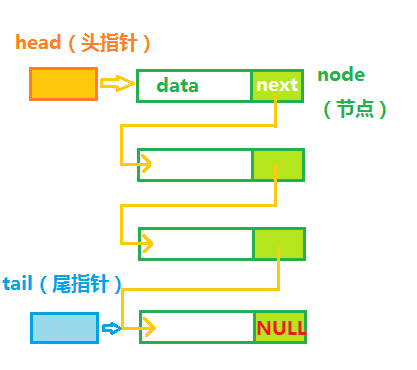
四、队列
队列抽象数据结构来自排队,排队的人先入队先出队,队列同样是先进先出(FIFO),队列的主要特点是从尾部添加数据,从头部移除数据。实现方式可以使用数组和链表,但是使用数组有一个问题,例如移除头部元素需要移动其它所有元素,效率不高,这里使用链表实现,队列的一般形式如下:
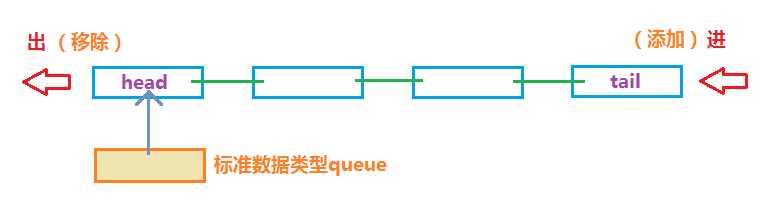
实现队列抽象类型同样只需三个:一般数据、队列数据单元、队列抽象标准数据类型接口,至于队列的应用要看情况,队列一般不会去直接操作中间的元素,而只操作前后的元素。
1、数据表示和算法操作
// 一般数据表示:饮料
typedef struct drink{
char name[128];
float price;
} Drink;
// 队列基本数据单元
typedef struct element{
Drink *drink;
struct element *next;
} Element;
// 抽象接口
typedef struct queue{
Element *head;
Element *tail;
unsigned int size;
} Queue;
extern Queue* queue_init();
extern bool queue_push(Queue *queue, Drink *drink);
extern Drink* queue_pop(Queue *queue);
extern void queue_print(Queue *queue);
extern void queue_clear(Queue *queue);
2、接口实现
Queue* queue_init(){
Queue *queue = (Queue*)malloc(sizeof(Queue));
queue->size = 0;
queue->head = NULL;
queue->tail = NULL;
return queue;
}
bool queue_push(Queue *queue, Drink *drink){
Element *element = (Element*)malloc(sizeof(Element));
Drink *dk = (Drink*)malloc(sizeof(Drink));
if(!element || !dk)
return false;
dk->price = drink->price;
strcpy(dk->name, drink->name);
element->drink = dk;
element->next = NULL;
if(!queue->head){
queue->head = element;
queue->tail = element;
queue->size++;
}
else{
queue->tail->next = element;
queue->tail = element;
queue->size++;
}
return true;
}
Drink* queue_pop(Queue *queue){
Element *element = queue->head;
if(!element)
return NULL;
queue->head = element->next;
return element->drink;
}
void queue_print(Queue *queue){
Element *element = queue->head;
while (element){
printf("%8s %.3f\n", element->drink->name, element->drink->price);
element = element->next;
}
}
void queue_clear(Queue *queue){
Element *element = queue->head;
while (element){
Element *temp = element->next;
free(element);
element = temp;
}
}
3、队列接口使用
Queue *queue = queue_init();
Drink d1;
strcpy(d1.name, "Red Wine");
d1.price = 687.99;
Drink d2;
strcpy(d2.name, "Cola");
d2.price = 18.55;
Drink d3;
strcpy(d3.name, "Water");
d3.price = 2.0;
queue_push(queue, &d1);
queue_push(queue, &d2);
queue_push(queue, &d3);
queue_print(queue);
queue_clear(queue);
五、二叉树
二叉树比以上介绍过的难好多,二叉树的基本形式是:数据项、左结点和右结点指针,每个根结点都有两个子结点,第一个根结点没有父结点,如下图:
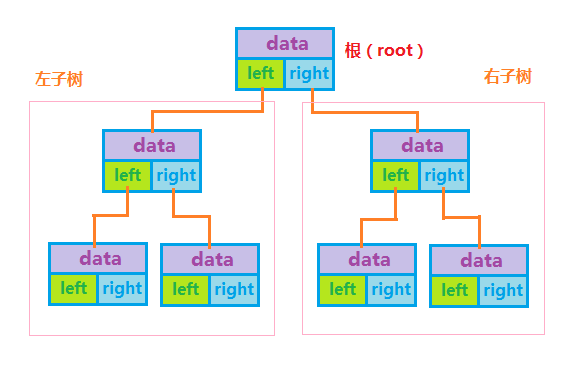
每个根结点的左右结点又可称为左右儿子,要表示二叉树数据结构并不困难,困难的地方在于如何添加和遍历数据,有两种方式:while循环和递归调用,这两种都是基于根结点的概念,我们可以将一个根结点以及两个子结点看作一个单元。
另外,二叉树的实现原理是基于二分查找进行排序,例如将新添加的项和根结点的数据项作对比,小于在左结点大于在右结点。
二叉树相比数组和链表,同时适用经常性查找,以及频繁插入和删除,二叉树的数据表示形式同样是围绕一般数据、单元数据项和抽象数据接口。
1、数据结构和算法声明
// 一般数据:商品
typedef struct good{
unsigned int id;
char title[256];
float price;
} Good;
// 数据单元结点
typedef struct cell{
Good *good;
struct cell *left;
struct cell *right;
} Cell;
// 二叉树主要接口
typedef struct tree{
Cell *root;
unsigned int size;
} Tree;
extern Tree* tree_init();
extern bool tree_add(Tree *tree, Good *good);
extern bool tree_delete_by_id(Tree *tree, unsigned int id);
extern Good* tree_get_by_id(Tree *tree, unsigned int id);
extern void tree_clear(Tree *tree);
2、接口实现
在这里暂且不实现删除元素的操作,下次详细讨论数据结构和算法的时候再介绍清楚,因为涉及的算法比较复杂,下面是部分实现代码:
#include "tree.h"
#include <stdlib.h>
#include <string.h>
Tree* tree_init(){
Tree *tree = (Tree*)malloc(sizeof(Tree));
tree->size = 0;
tree->root = NULL;
return tree;
}
bool tree_add(Tree *tree, Good *good){
Cell *cell = (Cell*)malloc(sizeof(Cell));
Good *gd = (Good*)malloc(sizeof(Good));
if(!cell || !gd)
return false;
gd->id = good->id;
strcpy(gd->title, good->title);
gd->price = good->price;
cell->good = gd;
cell->left = NULL;
cell->right = NULL;
if(!tree->root){
tree->root = cell;
tree->size++;
return true;
}
Cell *root = tree->root;
while (root != NULL){
if(root->good->id >= good->id){ // 先确定前后(左子树在根结点的前面,右子树在根结点的后面)
if(root->left == NULL){ // 再确定左右
root->left = cell;
break;
}
else{
root = root->left;
}
}
else{
if(root->right == NULL){
root->right = cell;
break;
}
else{
root = root->right;
}
}
}
return true;
}
bool tree_delete_by_id(Tree *tree, unsigned int id){
return false;
}
Good* tree_get_by_id(Tree *tree, unsigned int id){
Cell *root = tree->root;
while(root != NULL){
if(root->good->id == id){
return root->good;
}
else{
if(root->good->id > id){
root = root->left;
}
else{
root = root->right;
}
}
}
return NULL;
}
void tree_clear(Tree *tree){
}
3、二叉树接口使用
Tree *tree = tree_init();
Good g1;
g1.id = 8;
strcpy(g1.title, "Apple");
g1.price = 19.99;
Good g2;
g2.id = 18;
strcpy(g2.title, "Pure");
g2.price = 20.79;
Good g3;
g3.id = 7;
strcpy(g3.title, "Mapple");
g3.price = 60.37;
tree_add(tree, &g1);
tree_add(tree, &g2);
tree_add(tree, &g3);
Good *gp = tree_get_by_id(tree, 7);
printf("%d\n%s\n%.2f\n", gp->id, gp->title, gp->price);
评论前必须登录!
注册