 srcmini
srcmini本文概述
- 索引用于通过最小化查询处理时所需的磁盘访问次数来优化数据库的性能。
- 索引是一种数据结构。它用于快速查找和访问数据库表中的数据。
索引结构
可以使用一些数据库列来创建索引。

- 数据库的第一列是搜索键, 其中包含表的主键或候选键的副本。主键的值按排序顺序存储, 以便可以轻松访问相应的数据。
- 数据库的第二列是数据引用。它包含一组指针, 这些指针保存磁盘块的地址, 可以在其中找到特定键的值。
索引方法
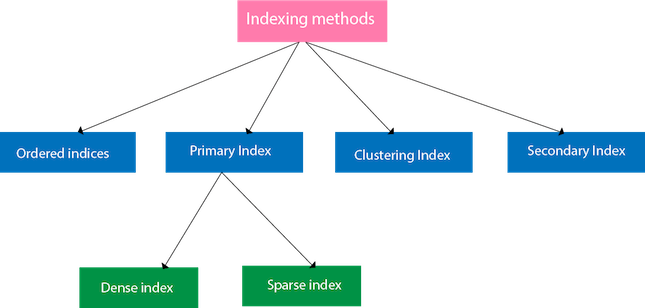
有序索引
通常对索引进行排序以使搜索更快。被排序的索引称为有序索引。
示例:假设我们有一个雇员表, 其中包含数千条记录, 每个记录的长度为10个字节。如果他们的ID以1、2、3 …开头, 依此类推, 我们必须搜索ID-543的学生。
- 对于没有索引的数据库, 我们必须搜索从开始到到达543的磁盘块。DBMS将在读取543 * 10 = 5430字节后读取记录。
- 在使用索引的情况下, 我们将使用索引进行搜索, 并且DBMS将在读取542 * 2 = 1084字节后读取记录, 这与前一种情况相比要少得多。
主要指标
- 如果索引是基于表的主键创建的, 则称为主索引。这些主键对于每个记录都是唯一的, 并且在记录之间包含1:1的关系。
- 由于主键是按排序顺序存储的, 因此搜索操作的性能非常有效。
- 主索引可以分为两种类型:密集索引和稀疏索引。
致密指数
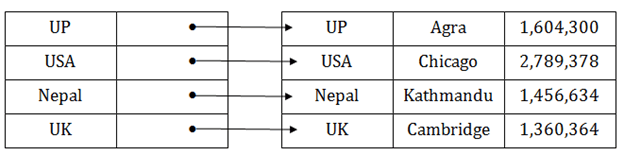
- 密集索引包含数据文件中每个搜索关键字值的索引记录。它使搜索速度更快。
- 在这种情况下, 索引表中的记录数与主表中的记录数相同。
- 它需要更多空间来存储索引记录本身。索引记录具有搜索键和指向磁盘上实际记录的指针。
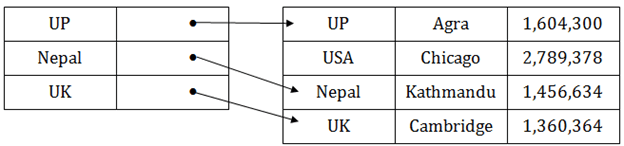
稀疏指数
- 在数据文件中, 索引记录仅显示几个项目。每个项目都指向一个块。
- 在这种情况下, 索引不是指向主表中的每个记录, 而是指向空白的主表中的记录。
聚类指数
- 聚簇索引可以定义为有序数据文件。有时, 索引是在非主键列上创建的, 该列可能对于每个记录而言都不唯一。
- 在这种情况下, 为了更快地识别记录, 我们将对两个或更多列进行分组以获得唯一值并从中创建索引。此方法称为聚簇索引。
- 将具有相似特征的记录分组, 并为这些组创建索引。
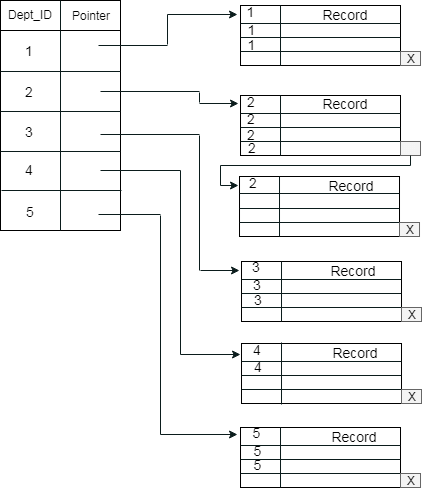
示例:假设一家公司在每个部门中都包含数名员工。假设我们使用聚簇索引, 其中将属于同一Dept_ID的所有雇员视为一个聚类, 并且索引指针指向整个聚类。这里的Dept_Id是非唯一键。
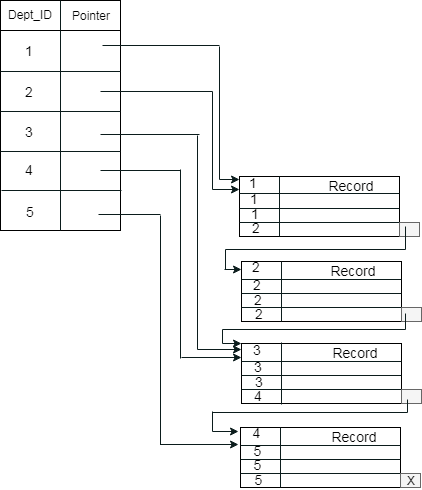
先前的架构几乎不会造成混淆, 因为一个磁盘块由属于不同群集的记录共享。如果我们对单独的群集使用单独的磁盘块, 则称为更好的技术。
次要指标
在稀疏索引中, 随着表大小的增长, 映射的大小也会增长。这些映射通常保存在主存储器中, 以便地址提取应更快。然后, 辅助存储器根据从映射获得的地址搜索实际数据。如果映射大小增加, 则获取地址本身会变慢。在这种情况下, 稀疏索引将无效。为了克服这个问题, 引入了二级索引。
在二级索引中, 为了减小映射的大小, 引入了另一级索引。在这种方法中, 最初选择了巨大的列范围, 以使第一级的映射大小变小。然后, 将每个范围进一步划分为较小的范围。第一级的映射存储在主存储器中, 因此地址提取速度更快。第二级和实际数据的映射存储在辅助存储器(硬盘)中。
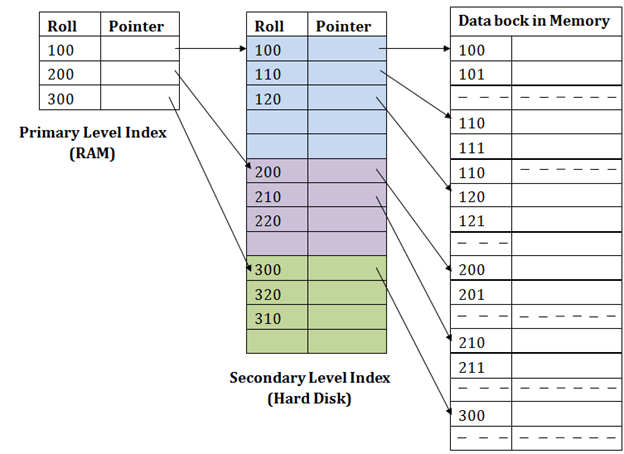
例如:
- 如果要在图中找到卷111的记录, 则它将在第一级索引中搜索小于或等于111的最高条目。它将在此级别获得100。
- 然后在第二个索引级别中, 它再次执行max(111)<= 111并得到110。现在使用地址110, 它转到数据块并开始搜索每个记录, 直到得到111。
- 这就是在这种方法中执行搜索的方式。插入, 更新或删除也以相同的方式进行。
评论前必须登录!
注册