 srcmini
srcmini为了指定自定义处理, Pig提供了对用户定义函数(UDF)的支持。因此, Pig允许我们创建自己的功能。当前, 可以使用以下编程语言来实现Pig UDF:-
- Java
- Python
- Jython
- JavaScript
- Ruby
- Groovy
在所有语言中, Pig为Java函数提供了最广泛的支持。但是, 仅对Python, Jython, JavaScript, Ruby和Groovy等语言提供有限的支持。
Apache PigUDF的示例
在Apache Pig里
- 所有UDF必须扩展“ org.apache.pig.EvalFunc”
- 所有功能都必须覆盖“ exec”方法。
让我们看一个简单的EVAL函数示例, 该函数将提供的字符串转换为大写。
UPPER.java
package com.hadoop;
import java.io.IOException;
import org.apache.pig.EvalFunc;
import org.apache.pig.data.Tuple;
public class TestUpper extends EvalFunc<String> {
public String exec(Tuple input) throws IOException {
if (input == null || input.size() == 0)
return null;
try{
String str = (String)input.get(0);
return str.toUpperCase();
}catch(Exception e){
throw new IOException("Caught exception processing input row ", e);
}
}
}- 创建jar文件并将其导出到特定目录。为此, 右键单击项目-导出-Java-JAR文件-下一步。
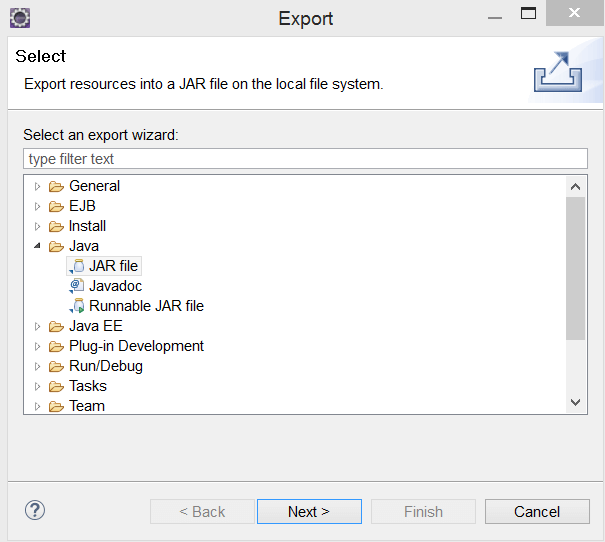
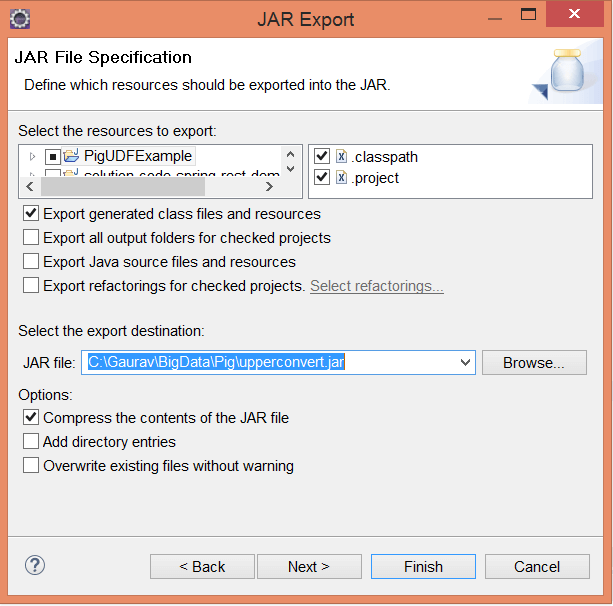
- 现在, 为jar文件提供一个特定的名称, 并将其保存在本地系统目录中。
- 在本地计算机上创建一个文本文件, 然后插入元组列表。
$ nano pigsample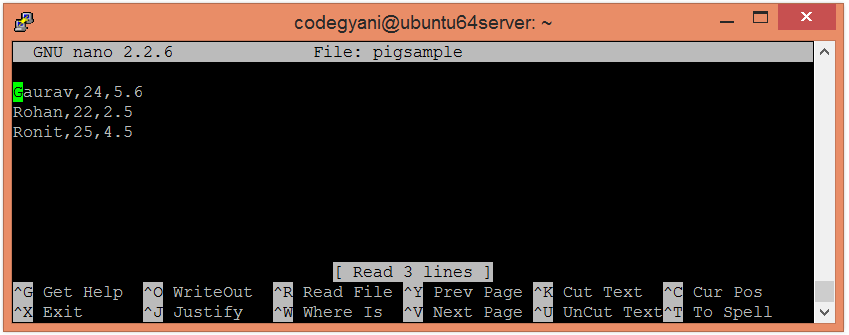
- 将文本文件上载到HDFS的特定目录中。
$ hdfs dfs -put pigexample /pigexample- 在本地计算机上创建一个Pig文件并编写脚本。
$ nano pscript.pig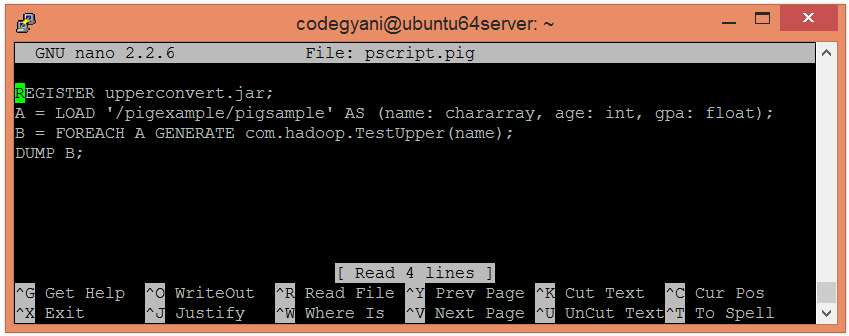
- 现在, 在终端中运行脚本以获取输出。
$pig pscript.pig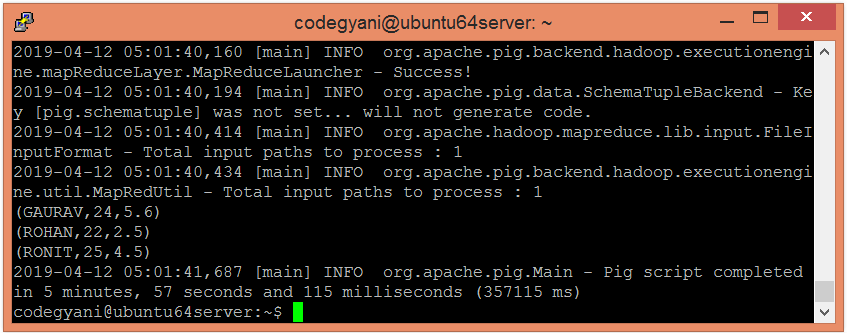
在这里, 我们得到了期望的输出。
评论前必须登录!
注册