 srcmini
srcmini先前我们讨论了mongodb的进阶查询:投影查询、分页查询以及对查询结果进行排序,从本节起我们开始学习mongodb相关的高级技术,首先我们会讨论mongodb如何创建索引,索引是数据库中最重要的东西!(为什么呢?对数据库感兴趣的朋友可以参考这里:二叉树、B-树和B+树实现原理,另外一种索引为散列,可参考:散列表的实现原理),然后讨论聚合查询、mongodb的复制集、分配、创建备份和部署。
一、创建索引
索引支持查询的有效解析。没有索引的话MongoDB需要查询每个文档,这种查询非常低效,需要MongoDB处理大量数据。
索引是特殊存储数据集的一小部分,索引存储特定字段或一组字段的值,按索引中指定的字段值排序。
要创建索引,需要使用MongoDB的ensureIndex()方法,ensureIndex()方法的基本语法如下:
db.collection_name.ensureIndex({KEY: 1})KEY是创建索引的目标字段的名称,1升序,-1降序,例如:
db.post.ensureIndex({"title": 1})使用ensureIndex()方法在多个字段上创建索引的例子如下
db.post.ensureIndex({"title": 1, "description": -1})ensureIndex()方法也接受选项列表(可选)作为第二个参数:
| 参数 | 类型 | 描述 |
| background | Boolean | true后台构建索引,默认值为false。 |
| unique | Boolean | 创建唯一索引,在索引键与索引中值匹配时,集合不会接受文档插入,默认false |
| name | string | 索引名称,为空ngoDB通过连接索引字段的名称和排序顺序来生成索引名。 |
| dropDups | Boolean | 在可能有重复项的字段上创建唯一索引。MongoDB只索引一个键的第一次出现,并从集合中删除所有包含该键的后续出现的文档,默认值为false。 |
| sparse | Boolean | true仅引用具有指定字段的记录,默认false。 |
| expireAfterSeconds | integer | 文档的过期时间 |
| v | index version | 索引版本号。默认索引版本取决于创建索引时运行的MongoDB版本。 |
| weights | document | 权重是一个从1到99999的数字,表示该字段相对于其他索引字段的重要性。 |
| default_language | string | 全文索引使用的语言,默认值是英文。 |
| language_override | string | 覆盖上面的default_language。 |
二、聚合查询
聚合查询处理数据记录并返回计算结果,使用aggregate()方法将来自多个文档的操作组值聚合在一起,并可以对分组的数据执行各种操作以返回单个结果。在SQL count(*)和with group by中,它相当于mongodb的聚合查询。
aggregate()方法的基本语法如下:
db.collection_name.aggregate(聚合操作)假设在一个集合中有以下数据:
{
_id: ObjectId(a)
title: 'AA',
by_user: 'oo',
likes: 5
},
{
_id: ObjectId(b)
title: 'BB',
by_user: 'oo',
likes: 3
},
{
_id: ObjectId(c)
title: 'CC',
by_user: 'nn',
likes: 1
},
如果你想显示每个用户的post数量,那么你可以使用下面的查询例子:
> db.post.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])
{
"result" : [
{
"_id" : "oo",
"num_tutorial" : 2
},
{
"_id" : "nn",
"num_tutorial" : 1
}
],
"ok" : 1
}
>
下表是可用的聚合表达式。
| 表达式 | 说明 | 例子 |
| $sum | 对所有文档的一个汇总。 | db.post.aggregate([{$group : {_id : “$by_user”, num_tutorial : {$sum : “$likes”}}}]) |
| $avg | 计算集合中所有文档中对应平均值。 | db.post.aggregate([{$group : {_id : “$by_user”, num_tutorial : {$avg : “$likes”}}}]) |
| $min | 文档对应值的最小值。 | db.post.aggregate([{$group : {_id : “$by_user”, num_tutorial : {$min : “$likes”}}}]) |
| $max | 文档对应值的最大值。 | db.post.aggregate([{$group : {_id : “$by_user”, num_tutorial : {$max : “$likes”}}}]) |
| $push | 将值插入结果文档中的数组 | db.post.aggregate([{$group : {_id : “$by_user”, url : {$push: “$url”}}}]) |
| $addToSet | 将值插入结果文档中的数组,但不创建副本。 | db.post.aggregate([{$group : {_id : “$by_user”, url : {$addToSet : “$url”}}}]) |
| $first | 根据分组从源文档获取第一个文档。通常和“$sort”阶段结合使用。 | db.post.aggregate([{$group : {_id : “$by_user”, first_url : {$first : “$url”}}}]) |
| $last | 根据分组从源文档获取最后一个文档。通常和“$sort”阶段一起使用。 | db.post.aggregate([{$group : {_id : “$by_user”, last_url : {$last : “$url”}}}]) |
管道的概念
在UNIX命令中,shell管道某些输入执行操作,输出作为下一个命令的输入。MongoDB在聚合框架中也支持相同的概念。有一组可能的阶段,每个阶段都作为一组文档作为输入并生成一组文档(或最终生成的JSON文档),然后这可以依次用于下一阶段。
下面是聚合框架的可能阶段:
1、$project—用于从集合中选择某些特定字段。
2、$match—这是一个过滤操作,因此可以减少作为下一阶段输入的文档数量。3、$group—这就是上面讨论的实际聚合。
4、$sort—排序数据。
5、$skip——在给定数量的文档的文档列表中向前跳转。
6、$limit—来限制要查看的文档数量。
7、$unwind——用于展开使用数组的文档。
三、复制集
复制可以在不同的数据库服务器上复制多个数据副本,跨多个服务器同步数据。复制提供了冗余并提高了数据可用性。
1、为什么使用复制集?
- 数据的高可用性(24*7)。
- 保障你的数据安全。
- 读取缩放。
- 无需停机进行维护(如备份、索引重建、压缩)。
- 灾难性数据恢复。
2、mongodb中的复制如何工作?
复制集是一组有相同的数据集的mongod实例,通过使用复制集来实现复制。主节点接收所有写操作,而其它为次节点,从主节点应用操作,这样它们就有相同的数据集,复制集只能有一个主节点。
- 复制集是一组两个或多个节点(通常至少需要3个节点)。
- 在一个复制集中,一个节点是主节点,其余节点是次要节点。
- 次节点的数据都是来自于主节点。
- 在自动故障转移或维护时,将为主节点建立选举,并选举一个新的主节点。
- 故障节点恢复后,它再次加入复制集,作为辅助节点工作。
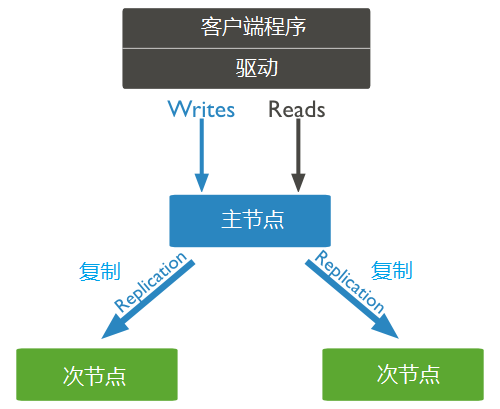
3、复制集的特性
(1)N个节点的集群
(2)任何一个节点都可以是主节点
(3)所有的写操作都是主操作
(4)自动故障转移
(5)自动恢复
(6)一致的主节点选举
4、创建一个复制集
在本教程中,我们根据以下步骤把独立的MongoDB实例转换成一个复制集:
(1)关闭已经运行的MongoDB服务器。
(2)通过指定–replSet选项来启动MongoDB服务器,下面是replSet的基本语法和用法:
mongod --port "端口" --dbpath "你的数据库路径" --replSet "复制集实例名"
mongod --port 27017 --dbpath "D:\mongodb\data" --replSet rs0
(3)它将在端口27017上启动一个名为rs0的mongod实例。
(4)现在启动命令提示符并连接到这个mongod实例。
(5)执行命令rs.initiate()启动新的复制集。
(6)执行命令rs.conf()检查复制集配置,rs.status()检查复制集的状态。
5、向复制集添加成员
首先在多台机器上启动mongod实例并执行命令rs.add()。
add()命令的基本语法如下所示:
rs.add(主机名:端口)
假设你的mongod实例名是monh.net,它在端口27017上运行。要将此实例添加到复制集,请在Mongo客户端中执行命令rs.add(),如:rs.add(“monh.net:27017”)。
连接到主节点时才会被添加到复制集,是否连接到主服务器了?在客户端执行db.isMaster()命令。
四、分片
分片是跨多台机器存储数据记录的过程,它是MongoDB满足数据增长需求的方法。随着数据大小的增加,单台计算机可能不足以存储数据,也无法提供可接受的读写吞吐量。
1、为什么使用分片?
(1)每个复制集只能为12个节点
(2)对延迟敏感的查询仍然归主节点
(3)在复制过程中,所有的写操作都转移到主节点
(4)当前活动的数据集太大的话,提供不了充足的内存
(5)本地磁盘不够大
(6)垂直扩展太贵了
2、mongodb中的分片
下图显示了MongoDB中使用分片集群的分片。
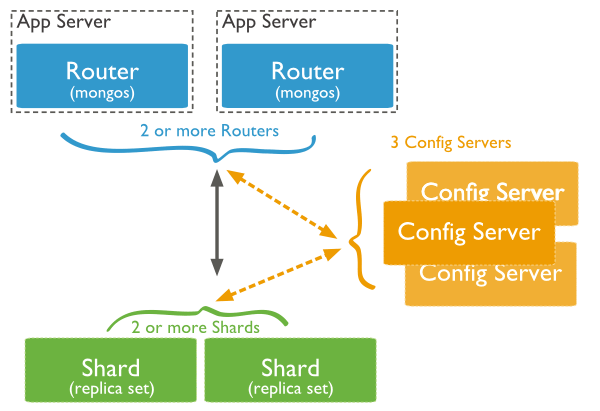
在上面的图中,有三个主要组件:
- 分片shard——分片用于存储数据,具有高可用性和数据一致性,每个分片都是一个单独的副本集。
- 配置服务器config server——这些服务器存储集群的元数据,该数据包含集群数据集到分片的映射。查询路由器使用此元数据将操作定向到特定的分片,分片集群正好有3个配置服务器。
- 查询路由器router——查询路由器基本上是mongo实例,与客户端应用程序接口,并直接操作到适当的分片。查询路由器处理并将操作定向到分片,然后将结果返回给客户端。
五、创建备份
1、mongodb中的数据备份
mongodump命令备份数据。该命令将把服务器的全部数据转储到转储目录中,可以通过许多选项限制数据量或创建远程服务器的备份。
mongodump命令的基本语法为:mongodump。
启动mongod服务器,假设你的mongod服务器运行在本地主机和端口27017上,打开一个命令提示符,转到你的mongodb实例的bin目录,输入命令mongodump。
该命令将连接到运行在127.0.0.1和端口27017的服务器,并将服务器的所有数据备份到目录/bin/dump/。
以下是mongodump命令的可用选项列表。
| Syntax | Description | Example |
| mongodump –host HOST_NAME –port PORT_NUMBER | 备份目标主机的数据 | mongodump –host srcmini02.com –port 27017 |
| mongodump –dbpath DB_PATH –out BACKUP_DIRECTORY | 仅备份指定路径上的指定数据库。 | mongodump –dbpath /data/db/ –out /data/backup/ |
| mongodump –collection COLLECTION –db DB_NAME | 此命令只备份指定数据库的指定集合。 | mongodump –collection post –db test |
2、恢复数据
直接使用MongoDB的mongorestore命令即可,此命令从备份目录中还原所有数据。
六、mongodb部署
当你准备部署MongoDB时,应该尝试了解应用程序在生产环境中是如何运行的,这样在投入生产后就可以最小化任何意外。
最好的方法包括对你的设置进行原型化、进行负载测试、监视关键指标,并使用这些信息来扩展你的设置。
为了监视部署,MongoDB提供了以下一些命令(这些命令都在mongodb安装的bin目录下)。
1、mongostat
检查运行的mongod实例的状态,返回数据库操作的计数器,包括插入、查询、更新、删除和游标。
2、mongotop
该命令在集合的基础上跟踪并报告MongoDB实例的读写活动。mongotop每秒返回信息,你可以相应地进行更改。可以检查读和写活动是否符合要求,确定没有从磁盘上读取太频繁,也没有超过你的工作集大小。
评论前必须登录!
注册