 srcmini
srcmini本文概述
NoSQL数据库在Node开发人员中相当受欢迎, 其中MongoDB(MEAN堆栈中的“ M”)领先。但是, 在开始新的Node项目时, 你不应该只接受Mongo作为默认选择。相反, 你选择的数据库类型应取决于项目的要求。例如, 如果需要动态表创建或实时插入, 则可以采用NoSQL解决方案。另一方面, 如果你的项目处理复杂的查询和事务, 则SQL数据库更有意义。
在本教程中, 我们将介绍mysql模块的入门-mysql的Node.js客户端, 使用JavaScript编写。在查看存储过程和转义用户输入之前, 我将说明如何使用该模块连接到MySQL数据库并执行常规的CRUD操作。
这篇热门文章于2020年更新, 以反映将MySQL与Node.js结合使用的当前做法。有关MySQL的更多信息, 请阅读Jump Start MySQL。
快速入门:如何在Node.js中使用MySQL
如果你已经到达这里, 正在寻找一种快速的方法来在Node中启动并运行MySQL, 我们将为你服务!
只需五个简单的步骤, 即可了解如何在Node中使用MySQL:
- 创建一个新项目:mkdir mysql-test && cd mysql-test。
- 创建一个package.json文件:npm init -y。
- 安装mysql模块:npm install mysql。
- 创建一个app.js文件, 并在下面的代码段中进行复制(适当地编辑占位符)。
- 运行文件:nodeapp.js。观察“已连接!”信息。
const mysql = require('mysql');
const connection = mysql.createConnection({
host: 'localhost', user: 'user', password: 'password', database: 'database name'
});
connection.connect((err) => {
if (err) throw err;
console.log('Connected!');
});
安装mysql模块
现在, 让我们仔细看看每个步骤。
mkdir mysql-test
cd mysql-test
npm init -y
npm install mysql
首先, 我们使用命令行创建一个新目录并导航到该目录。然后, 我们使用命令npm init -y创建package.json文件。 -y标志意味着npm将使用默认值而无需经过交互过程。
此步骤还假定你在系统上安装了Node和npm。如果不是这种情况, 请查看此SitePoint文章以了解操作方法:使用nvm安装多个版本的Node.js。
之后, 我们从npm安装mysql模块, 并将其另存为项目依赖项。项目依赖关系(与devDependencies相反)是应用程序运行所必需的那些软件包。你可以在此处详细了解两者之间的区别。
如果你需要使用npm的进一步帮助, 请务必查看本指南或在我们的论坛中提问。
入门
在开始连接数据库之前, 请务必在计算机上安装并配置MySQL, 这一点很重要。如果不是这种情况, 请查阅其主页上的安装说明。
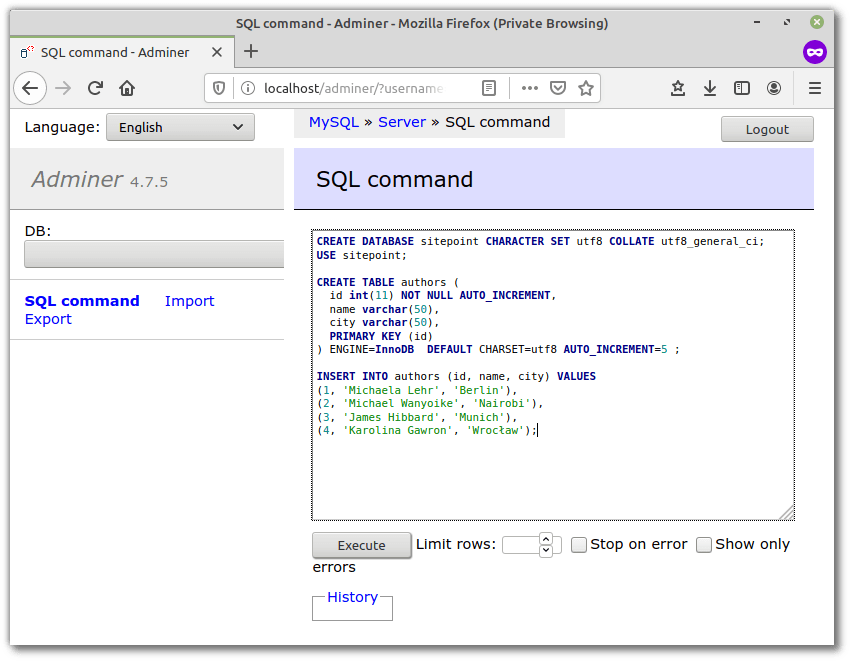
我们需要做的下一件事是创建一个数据库和一个要使用的数据库表。你可以使用图形界面(例如Adminer)或使用命令行来执行此操作。在本文中, 我将使用一个名为sitepoint的数据库和一个名为authors的表。这是数据库的转储文件, 以便你可以按照以下步骤快速启动并运行:
CREATE DATABASE sitepoint CHARACTER SET utf8 COLLATE utf8_general_ci;
USE sitepoint;
CREATE TABLE authors (
id int(11) NOT NULL AUTO_INCREMENT, name varchar(50), city varchar(50), PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=5 ;
INSERT INTO authors (id, name, city) VALUES
(1, 'Michaela Lehr', 'Berlin'), (2, 'Michael Wanyoike', 'Nairobi'), (3, 'James Hibbard', 'Munich'), (4, 'Karolina Gawron', 'Wrocław');
连接到数据库
现在, 让我们在mysql-test目录中创建一个名为app.js的文件, 并查看如何从Node.js连接到MySQL。
const mysql = require('mysql');
// First you need to create a connection to the database
// Be sure to replace 'user' and 'password' with the correct values
const con = mysql.createConnection({
host: 'localhost', user: 'user', password: 'password', });
con.connect((err) => {
if(err){
console.log('Error connecting to Db');
return;
}
console.log('Connection established');
});
con.end((err) => {
// The connection is terminated gracefully
// Ensures all remaining queries are executed
// Then sends a quit packet to the MySQL server.
});
现在打开一个终端并输入Node.jsapp.js。成功建立连接后, 你应该能够在控制台中看到“ Connection created”消息。如果出现问题(例如, 输入错误的密码), 则会触发回调, 并向该回调传递JavaScript错误对象(err)的实例。尝试将其记录到控制台以查看其包含的其他有用信息。
使用nodemon监视文件中的更改
每当我们对代码进行更改时, 手动运行node app.js将会变得有些乏味, 因此让我们使其自动化。这部分与本教程的其余部分无关, 但一定会节省一些击键。
首先, 我们安装一个nodemon软件包。当检测到目录中的文件更改时, 此工具可自动重新启动Node应用程序:
npm install --save-dev nodemon
现在运行./node_modules/.bin/nodemon app.js并更改为app.js。 nodemon应该检测到更改并重新启动应用程序。
注意:我们直接从node_modules文件夹运行nodemon。你也可以在全局安装它, 或创建一个npm脚本来启动它。
执行查询
读取数据
现在你已经知道如何从Node.js建立与MySQL数据库的连接, 接下来让我们看看如何执行SQL查询。首先, 在createConnection命令中指定数据库名称(站点点):
const con = mysql.createConnection({
host: 'localhost', user: 'user', password: 'password', database: 'sitepoint'
});
建立连接后, 我们将使用con变量对数据库表作者执行查询:
con.query('SELECT * FROM authors', (err, rows) => {
if(err) throw err;
console.log('Data received from Db:');
console.log(rows);
});
在运行app.js时(使用nodemon或在终端中键入node app.js), 你应该能够看到从数据库返回的数据记录到终端:
[ RowDataPacket { id: 1, name: 'Michaela Lehr', city: 'Berlin' }, RowDataPacket { id: 2, name: 'Michael Wanyoike', city: 'Nairobi' }, RowDataPacket { id: 3, name: 'James Hibbard', city: 'Munich' }, RowDataPacket { id: 4, name: 'Karolina Gawron', city: 'Wrocław' } ]
从MySQL数据库返回的数据可以通过简单地循环行对象来解析。
rows.forEach( (row) => {
console.log(`${row.name} lives in ${row.city}`);
});
这为你提供以下内容:
Michaela Lehr lives in Berlin
Michael Wanyoike lives in Nairobi
James Hibbard lives in Munich
Karolina Gawron lives in Wrocław
插入查询
你可以对数据库执行插入查询, 如下所示:
const author = { name: 'Craig Buckler', city: 'Exmouth' };
con.query('INSERT INTO authors SET ?', author, (err, res) => {
if(err) throw err;
console.log('Last insert ID:', res.insertId);
});
请注意, 我们如何使用callback参数获取插入记录的ID。
更新查询
同样, 在执行更新查询时, 可以使用result.affectedRows检索受影响的行数:
con.query(
'UPDATE authors SET city = ? Where ID = ?', ['Leipzig', 3], (err, result) => {
if (err) throw err;
console.log(`Changed ${result.changedRows} row(s)`);
}
);
删除查询
删除查询也是如此:
con.query(
'DELETE FROM authors WHERE id = ?', [5], (err, result) => {
if (err) throw err;
console.log(`Deleted ${result.affectedRows} row(s)`);
}
);
进阶使用
最后, 我想看看mysql模块如何处理存储过程以及用户输入的转义。
存储过程
简而言之, 存储过程是准备好的SQL代码, 你可以将其保存到数据库中, 以便可以轻松地重用它。如果你需要有关存储过程的复习, 请查看本教程。
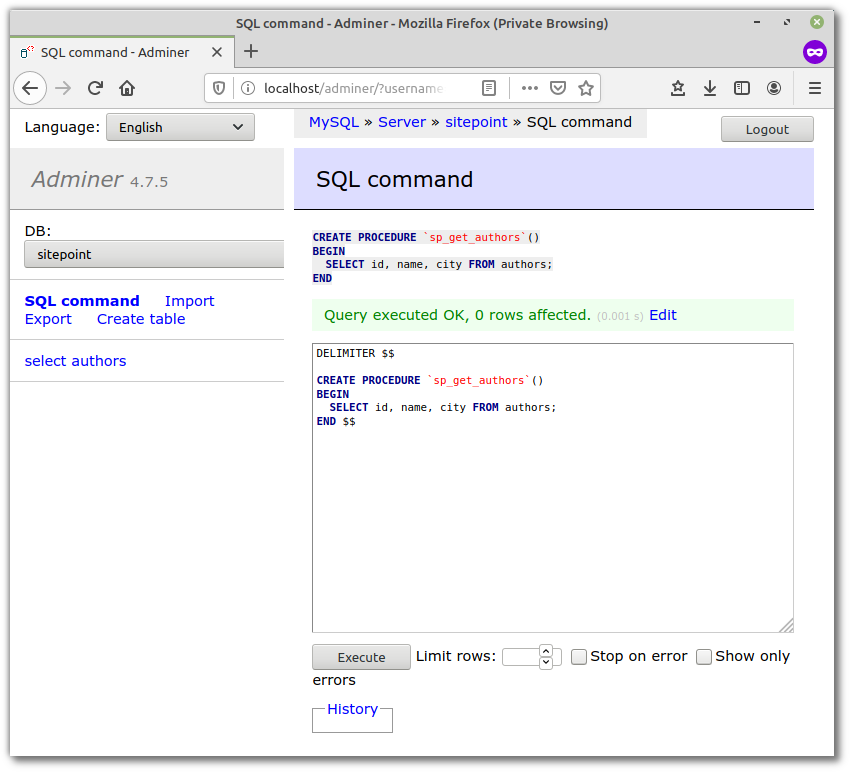
让我们为我们的站点数据库创建一个存储过程, 以获取所有作者详细信息。我们将其称为sp_get_authors。为此, 你需要某种数据库接口。我正在使用管理员。针对站点数据库运行以下查询, 确保你的用户在MySQL服务器上具有管理员权限:
DELIMITER $$
CREATE PROCEDURE `sp_get_authors`()
BEGIN
SELECT id, name, city FROM authors;
END $$
这将在ROUTINES表的information_schema数据库中创建并存储该过程。
注意:如果定界符语法对你来说很奇怪, 请在此处进行解释。
接下来, 建立连接并使用连接对象来调用存储过程, 如下所示:
con.query('CALL sp_get_authors()', function(err, rows){
if (err) throw err;
console.log('Data received from Db:');
console.log(rows);
});
保存更改并运行文件。执行后, 你应该能够查看从数据库返回的数据:
[ [ RowDataPacket { id: 1, name: 'Michaela Lehr', city: 'Berlin' }, RowDataPacket { id: 2, name: 'Michael Wanyoike', city: 'Nairobi' }, RowDataPacket { id: 3, name: 'James Hibbard', city: 'Leipzig' }, RowDataPacket { id: 4, name: 'Karolina Gawron', city: 'Wrocław' }, OkPacket {
fieldCount: 0, affectedRows: 0, insertId: 0, serverStatus: 34, warningCount: 0, message: '', protocol41: true, changedRows: 0 } ]
它与数据一起返回一些其他信息, 例如受影响的行数, insertId等。你需要遍历返回数据的第0个索引, 以使员工详细信息与其余信息分开:
rows[0].forEach( (row) => {
console.log(`${row.name} lives in ${row.city}`);
});
这为你提供以下内容:
Michaela Lehr lives in Berlin
Michael Wanyoike lives in Nairobi
James Hibbard lives in Leipzig
Karolina Gawron lives in Wrocław
现在, 考虑一个需要输入参数的存储过程:
DELIMITER $$
CREATE PROCEDURE `sp_get_author_details`(
in author_id int
)
BEGIN
SELECT name, city FROM authors where id = author_id;
END $$
我们可以在调用存储过程时传递输入参数:
con.query('CALL sp_get_author_details(1)', (err, rows) => {
if(err) throw err;
console.log('Data received from Db:\n');
console.log(rows[0]);
});
这为你提供以下内容:
[ RowDataPacket { name: 'Michaela Lehr', city: 'Berlin' } ]
在大多数情况下, 当我们尝试将记录插入数据库时, 我们需要最后插入的ID作为out参数返回。考虑以下带有out参数的insert存储过程:
DELIMITER $$
CREATE PROCEDURE `sp_insert_author`(
out author_id int, in author_name varchar(25), in author_city varchar(25)
)
BEGIN
insert into authors(name, city)
values(author_name, author_city);
set author_id = LAST_INSERT_ID();
END $$
要使用out参数进行过程调用, 我们首先需要在创建连接时启用多个调用。因此, 通过将多语句执行设置为true来修改连接:
const con = mysql.createConnection({
host: 'localhost', user: 'user', password: 'password', database: 'sitepoint', multipleStatements: true
});
接下来, 在调用该过程时, 设置out参数并将其传入:
con.query(
"SET @author_id = 0; CALL sp_insert_author(@author_id, 'Craig Buckler', 'Exmouth'); SELECT @author_id", (err, rows) => {
if (err) throw err;
console.log('Data received from Db:\n');
console.log(rows);
}
);
如上面的代码所示, 我们已经设置了@author_id out参数, 并在调用存储过程时传递了该参数。拨打电话后, 我们需要选择out参数来访问返回的ID。
运行app.js。成功执行后, 你应该能够看到所选的out参数以及其他各种信息。 rows [2]应该可以让你访问所选的out参数:
[ RowDataPacket { '@author_id': 6 } ] ]
注意:要删除存储过程, 你需要运行命令DROP PROCEDURE <procedure-name>;。针对你为其创建数据库的数据库。
转义用户输入
为了避免SQL注入攻击, 在SQL查询中使用它之前, 应始终转义从用户收到的所有数据。让我们演示一下原因:
const userSubmittedVariable = '1';
con.query(
`SELECT * FROM authors WHERE id = ${userSubmittedVariable}`, (err, rows) => {
if(err) throw err;
console.log(rows);
}
);
这似乎无害, 甚至返回正确的结果:
{ id: 1, name: 'Michaela Lehr', city: 'Berlin' }
但是, 尝试将userSubmittedVariable更改为此:
const userSubmittedVariable = '1 OR 1=1';
我们突然可以访问整个数据集。现在将其更改为:
const userSubmittedVariable = '1; DROP TABLE authors';
我们现在遇到了麻烦!
好消息是, 帮助随时可用。你只需要使用mysql.escape方法:
con.query(
`SELECT * FROM authors WHERE id = ${mysql.escape(userSubmittedVariable)}`, (err, rows) => {
if(err) throw err;
console.log(rows);
}
);
你也可以使用问号占位符, 就像我们在本文开头的示例中所做的那样:
con.query(
'SELECT * FROM authors WHERE id = ?', [userSubmittedVariable], (err, rows) => {
if(err) throw err;
console.log(rows);
}
);
为什么不仅仅使用ORM?
在探讨这种方法的利弊之前, 让我们花点时间看一下什么是ORM。以下是堆栈溢出的答案:
对象关系映射(ORM)是一种技术, 使你可以使用面向对象的范例查询和操作数据库中的数据。在谈论ORM时, 大多数人指的是实现对象关系映射技术的库, 因此使用了“ ORM”一词。
因此, 这意味着你使用ORM的特定于域的语言编写数据库逻辑, 而不是到目前为止我们所采用的常规方法。为了让你大致了解它的外观, 下面是一个使用Sequelize的示例, 该示例在数据库中查询所有作者并将他们记录到控制台:
const sequelize = new Sequelize('sitepoint', 'user', 'password', {
host: 'localhost', dialect: 'mysql'
});
const Author = sequelize.define('author', {
name: {
type: Sequelize.STRING, }, city: {
type: Sequelize.STRING
}, }, {
timestamps: false
});
Author.findAll().then(authors => {
console.log("All authors:", JSON.stringify(authors, null, 4));
});
是否使用ORM对你而言是否有意义, 将在很大程度上取决于你所从事的工作以及与谁合作。一方面, ORMS往往会提高开发人员的工作效率, 部分原因是要抽象掉大部分SQL, 以便并非团队中的每个人都需要知道如何编写超高效的数据库特定查询。迁移到其他数据库软件也很容易, 因为你正在开发抽象。
但是, 另一方面, 由于不了解ORM的工作方式, 因此可能会编写一些非常混乱且效率低下的SQL。性能也是一个问题, 因为优化不必通过ORM的查询要容易得多。
无论你采用哪种方式都取决于你, 但是, 如果你要在此过程中做出决定, 请查看以下堆栈溢出线程:为什么要使用ORM?还可以在SitePoint上查看此帖子:你可能不知道的3个JavaScript ORM。
结论
在本教程中, 我们为Node.js安装了mysql客户端, 并将其配置为连接到数据库。我们还了解了如何执行CRUD操作, 如何使用准备好的语句以及如何转义用户输入以减轻SQL注入攻击。但是, 我们仅涉及mysql客户端提供的内容。有关更多详细信息, 我建议阅读官方文档。
并且请记住, mysql模块并不是唯一的展示。还有其他选项, 例如流行的node-mysql2。
评论前必须登录!
注册