 srcmini
srcmini本文概述
- 目标
- 先决条件
- 注意事项
- 脚步
- 库和功能
- 只是为了好玩
- 获取数据
- 检查数据
- 特征工程
- 机器学习过程
- 分类器任务
- 规范化数据
- 创建学习者列表
- 重采样
- 绩效考核
- 火车模型/基准
- 调整模型-xgBoost
- 真实测试:新数据
- 获取数据
- 特征工程
- 设置和训练
- 分类错误
- 测试在哪里?
- 进一步分析的主题!
如果你需要机器学习入门, 请参加srcmini的机器学习入门课程。
使用各种机器学习(ML)分类算法逐步构建模型, 以预测歌曲的类型以及在Billboard图表上是否成功-完全基于歌词!
这是一个由三部分组成的教程系列的第三部分, 你将继续使用R来执行传奇艺术家Prince以及其他艺术家和作者的音乐歌词案例研究中的各种分析任务。这三个教程涵盖以下内容:
- 第一部分:使用NLP进行歌词分析和使用R进行机器学习
- 第二部分-A:R中的整洁情绪分析
- 第二部分B:使用R的机器学习和NLP-主题建模和音乐分类
- 第三部分:歌词分析:使用带有R的机器学习进行预测分析
作为数据科学家, 你将需要了解监督学习和无监督学习。本教程以各种艺术家(和几本书作者)的歌词为基础, 说明并提供了一种音乐学习用例, 用于某种形式的监督学习, 尤其是分类。你将学习如何建立模型以将歌曲分类为相关流派, 并研究使用歌词确定商业成功的可能性。
目标
你是否曾经使用过音乐流和自动推荐的互联网广播服务, 例如Pandora, iHeart Radio, Spotify等?如果你设置了硬石站, 则可能不会期望听到有关牛仔靴和小镇的乡村歌曲。典型的音乐推荐系统注重音质, 而抒情分析刚刚出现在研究论文中。借助本教程中的技术, 你可以利用当今科学家正在研究的前沿方法来提出构想, 以推动这一新兴领域的发展。
先决条件
本教程假定你对使用tidytext进行文本挖掘有基本的了解。它是使用几种流行的分类算法的机器学习技术的中级介绍。建议你具有R编程方面的丰富经验, 最好是具有一些机器学习知识, 并希望通过动手使用案例来了解有关其应用和实现的更多信息。每种算法仅作简要说明, 但始终提供链接以进行更深入的分析。
在整篇文章中, 你将使用名为mlr的R语言进行机器学习实验的框架。尽管本教程不在mlr上, 但是你将广泛地将其用作机器学习过程的一种界面。目的是使用它来简化对使用不同算法构建模型的各个步骤的解释。我强烈建议你在包装盒中使用该综合教程。
注意事项
ML有很多组件, 你只会在本教程中摸索表面。与本系列的第一部分和第二部分不同, 旁白可能会给你带来更多的问题而不是答案。如果你插入自己的数据和代码, 并按照自己的节奏研究不同的算法, 那么你将获得最大的体验。
脚步
这是构建模型的步骤的简要概述:
第一节:了解如何根据抒情特征预测类型。
- 朗读10位不同艺术家/作者的歌词/文字(每种类型两种, 五种类型)
- 创建训练并测试整洁的数据框
- 执行特征工程以为模型创建预测变量
- 确定用于分类的算法
- 训练模型并确定最佳选择基准
- 选择一个模型并进行调整
- 在新的数据集上测试模型
第二部分:使用标志性艺术家Prince的歌词来开发模型来预测歌曲的成功。
你将需要查看以前的教程, 以真正理解数据及其细微差别。请记住, 与非小说相比, 对歌词的挖掘和预测分析非常复杂, 因为上下文, 含义和微妙的信息通常隐藏在歌曲作者所隐含的创造性细微差别之下。与关于主题建模的第二部分B一样, 你将继续与不同类型的艺术家合作, 并继续研究两本有关机器学习的书籍(具有数据科学类型-目的是介绍另一种形式的文本)。
库和功能
首先加载库, 然后查看数据的整体结构。
library(tidyverse) #tidyr, #dplyr, #magrittr, #ggplot2
library(tidytext) #unnesting text into single words
library(mlr) #machine learning framework for R
library(kableExtra) #create attractive tables
library(circlize) #cool circle plots
library(jpeg) #read in jpg files for the circle plots
#define some colors to use throughout
my_colors <- c("#E69F00", "#56B4E9", "#009E73", "#CC79A7", "#D55E00", "#D65E00")
#customize the text tables for consistency using HTML formatting
my_kable_styling <- function(dat, caption) {
kable(dat, "html", escape = FALSE, caption = caption) %>%
kable_styling(bootstrap_options = c( "condensed", "bordered"), full_width = FALSE)
}
只是为了好玩
与以前的教程一样, 下面此圆形图的代码可能看起来很复杂, 但我永远无法忍受出色的图形。这会为你显示数据中每个艺术家/作者的专辑/书籍封面。这涵盖了测试和培训数据集。有关循环包装的更多详细信息, 请查看Zuguang Gu的这本书。
#read in the list of jpg files of album/book covers
files = list.files("jpg\\", full.names = TRUE)
#clean up the file names so we can use them in the diagram
removeSpecialChars <- function(x) gsub("[^a-zA-Z]", " ", x)
names <- lapply(files, removeSpecialChars)
names <- gsub("jpg", "", names )
#check out the circlize package for details!
circos.clear() #very important!
circos.par("points.overflow.warning" = FALSE)
circos.initialize(names, xlim = c(0, 2))
circos.track(ylim = c(0, 1), panel.fun = function(x, y) {
image = as.raster(readJPEG(files[CELL_META$sector.numeric.index]))
circos.text(CELL_META$xcenter, CELL_META$cell.ylim[1] - uy(1.5, "mm"), CELL_META$sector.index, CELL_META$sector.index, facing = "clockwise", niceFacing = TRUE, adj = c(1, 0.5), cex = 0.9)
circos.raster(image, CELL_META$xcenter, CELL_META$ycenter, width = "1.5cm", facing = "downward")
}, bg.border = 1, track.height = .4)
获取数据
为了专注于建模, 我在本教程之外进行了数据条件处理, 并为你提供了分析所需的所有数据。以下是预处理的摘要:
- 在网上刮掉了八位歌手的歌词
- 使用pdftools包中的pdf_text()函数收集两本书的内容(每个页面代表一个不同的文档)
- 如第一部分所述, 通过删除不需要的字符来清除所有数据并转换为小写
- 合并并平衡数据, 以便每个作者(源)具有相同数量的歌曲/文档
你将在下面阅读培训和测试数据, 这些数据已经拆分, 可以单独加载。然后使用tidytext中的unnest()创建一个整齐的版本, 每条记录一个单词。
five_sources_data <- read.csv("five_sources_data_balanced.csv", stringsAsFactors = FALSE)
five_sources_tidy <- five_sources_data %>%
unnest_tokens(word, text) %>%
anti_join(stop_words)
five_sources_data_test <- read.csv("five_sources_data_test.csv", stringsAsFactors = FALSE)
five_sources_test_tidy <- five_sources_data_test %>%
unnest_tokens(word, text) %>%
anti_join(stop_words)
#very small file that has a couple of words that help to identify certain genres
explicit_words <- read.csv("explicit_words.csv", stringsAsFactors = FALSE)
检查数据
现在, 你已经加载并整理了训练和测试数据, 你可以看到每个艺术家/作者有多少首歌曲。由于数据集包含歌曲和书页, 因此将它们分别称为文档。你将创建的功能基于文档及其关联的元数据, 因此理解此概念很重要。另外, 由于有艺术家和作家, 因此我将其作为每个文档的来源。
five_sources_data %>%
group_by(genre, source) %>%
summarise(doc_count = n()) %>%
my_kable_styling("Training Dataset")

five_sources_data_test %>%
group_by(genre, source) %>%
summarise(doc_count = n()) %>%
my_kable_styling("Test Dataset")
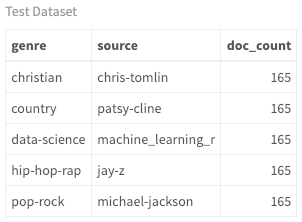
尽管你可以看到类型, 来源和文档数量, 但是下面的和弦图是查看这些关系的更好方法。在整个教程中, 你可以看到这些关系如何随着新模型的变化而发展。当前, 由于艺术家是通过这种方式分类的, 因此在来源和类型之间存在一对一的关系。但是, 跨界艺术家很常见, 当你查看此图的更高版本时, 你会看到证据。
#get SONG count per genre/source. Order determines top or bottom.
genre_chart <- five_sources_data %>%
count(genre, source)
circos.clear() #very important! Reset the circular layout parameters
#assign chord colors
grid.col = c("christian" = my_colors[1], "pop-rock" = my_colors[2], "hip-hop-rap" = my_colors[3], "data-science" = my_colors[4], "country" = my_colors[5], "amy-grant" = "grey", "eminem" = "grey", "johnny-cash" = "grey", "machine_learning" = "grey", "prince" = "grey")
# set the global parameters for the circular layout. Specifically the gap size
circos.par(gap.after = c(rep(5, length(unique(genre_chart[[1]])) - 1), 15, rep(5, length(unique(genre_chart[[2]])) - 1), 15))
chordDiagram(genre_chart, grid.col = grid.col, transparency = .2)
title("Relationship Between Genre and Source")
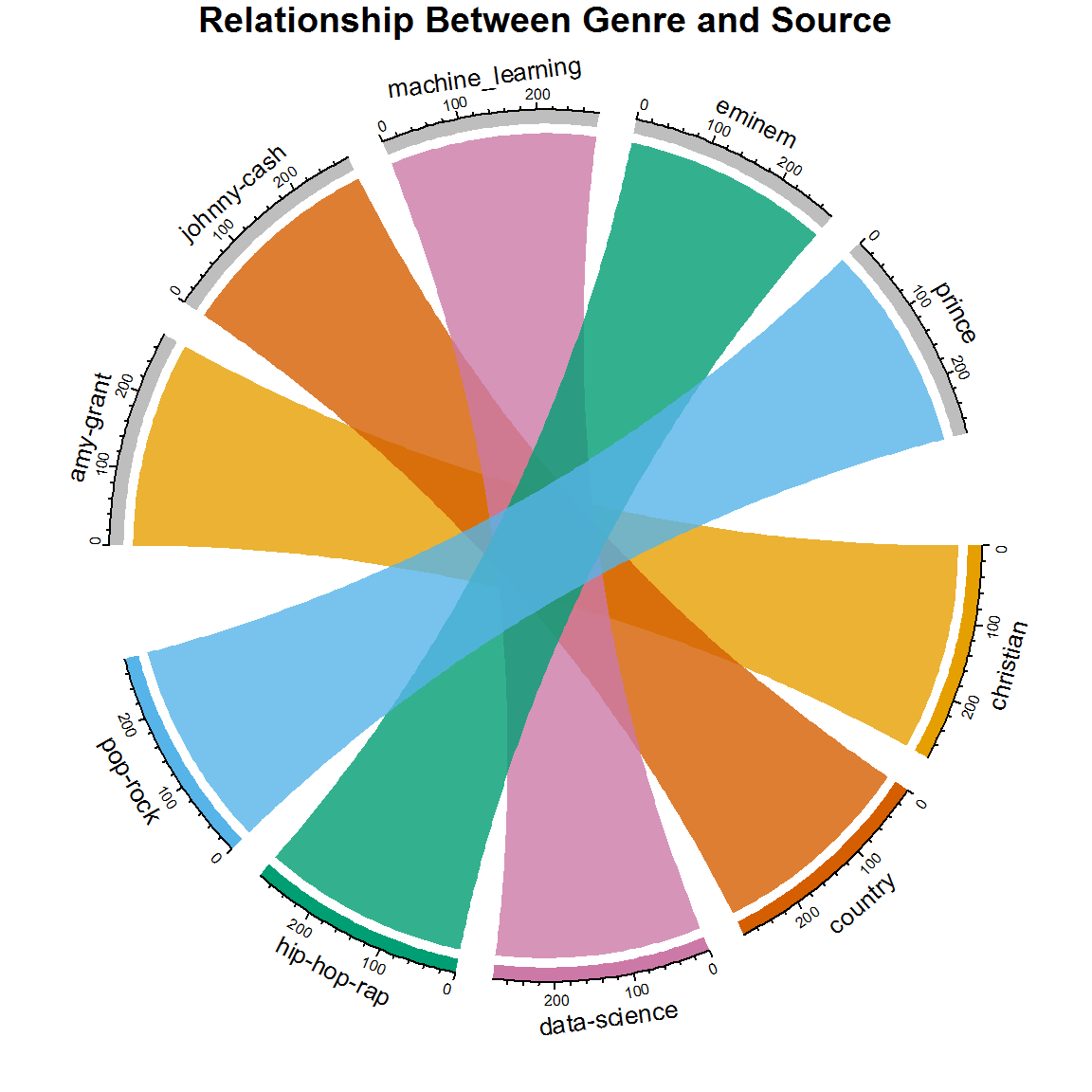
考虑一下如果没有一对一的关系, 此图将是什么样。如果仅根据歌词来预测类型, 你认为会发生什么?
如果为了对歌曲进行分类而只需要处理歌词, 那么你将如何生成预测变量?首先, 想一想这首歌, 以及在歌词上有什么不同之处。所有音乐的共同主题是重复。有些类型的重复使用次数比其他类型多吗?字长呢?有些人会更频繁地使用更大或更小的单词吗?你还能想到什么其他因素来描述歌词?如果你获得每首歌曲的这些计数, 则你将拥有第一组预测变量!
请注意, 上面列出的所有变量都是基于每首歌的单词的定量特征(数量, 长度等)。但是, 特定于类型的单个单词呢?在以前的教程中, 你从事了情感分析和主题建模。这些活动的重点是特定于某些艺术家或体裁的单词。因此, 如果你进一步迈出这一步, 则可以基于内容(或上下文)创建一些最重要的预测性组件。这是特定于文本分析的创造性步骤, 可为你的模型提供重要的预测指标。
特征工程
首先, 你想获得每种类型最常见(常用)的单词。这是在第一部分教程中完成的。首先获取每种类型的单词总数。然后按类型将单词分组, 并获得每个单词使用频率的计数。现在, 选择由number_of_words变量定义的前n个最常见的单词。这是棘手的部分:你应该选择多少个单词?如果选择不充分, 将不会优化模型, 但是如果选择过多, 则会过度拟合并扭曲结果。描述起来相对复杂, 但是真正的解决方案是反复试验。我想出了5500个词的最佳数量。试一试这个价值, 看看它如何影响你的结果。你可能会发现更好的结果!如果此步骤尚不完全清楚, 请与我呆在一起, 它将变得更加有意义。
许多单词对于一种以上的流派非常常见(例如时间, 生活等), 我在下面的multi_genre变量中删除了这些单词。这样可以使不同单词的列表更清晰, 从而更好地区分来源。
#play with this number until you get the best results for your model.
number_of_words = 5500
top_words_per_genre <- five_sources_tidy %>%
group_by(genre) %>%
mutate(genre_word_count = n()) %>%
group_by(genre, word) %>%
#note that the percentage is also collected, when really you
#could have just used the count, but it's good practice to use a %
mutate(word_count = n(), word_pct = word_count / genre_word_count * 100) %>%
select(word, genre, genre_word_count, word_count, word_pct) %>%
distinct() %>%
ungroup() %>%
arrange(desc(word_pct)) %>%
top_n(number_of_words) %>%
select(genre, word, word_pct)
#remove words that are in more than one genre
top_words <- top_words_per_genre %>%
ungroup() %>%
group_by(word) %>%
mutate(multi_genre = n()) %>%
filter(multi_genre < 2) %>%
select(genre, top_word = word)
#create lists of the top words per genre
book_words <- lapply(top_words[top_words$genre == "data-science", ], as.character)
country_words <- lapply(top_words[top_words$genre == "country", ], as.character)
hip_hop_words <- lapply(top_words[top_words$genre == "hip-hop-rap", ], as.character)
pop_rock_words <- lapply(top_words[top_words$genre == "pop-rock", ], as.character)
christian_words <- lapply(top_words[top_words$genre == "christian", ], as.character)
现在, 将特定于类型的单词用作数据集中的特征。由于你将为多个数据集创建要素, 因此创建一个函数, 使你只需要写一次即可。在此功能中, 你会看到有关词汇多样性和密度的参考。查阅第一部分, 对这些概念进行解释。
考虑下面的每个功能, 以及它如何根据流派而变化。我将不着重解释每个功能, 而是着重于后续的机器学习步骤, 因此请花一点时间查看代码并了解其功能。并且不要忘记关键类型特定的预测变量。例如, country_word_count只是每首歌曲中出现的热门国家/地区字的计数。请注意, 我为显式单词和书本单词分配了更多的权重(请参见sum()函数中使用的10和20)。我这样做是因为它们非常有特色, 并且有助于对文档进行分类。同样, 这是一个反复试验的过程!
features_func_genre <- function(data) {
features <- data %>%
group_by(document) %>%
mutate(word_frequency = n(), lexical_diversity = n_distinct(word), lexical_density = lexical_diversity/word_frequency, repetition = word_frequency/lexical_diversity, document_avg_word_length = mean(nchar(word)), title_word_count = lengths(gregexpr("[A-z]\\W+", document)) + 1L, title_length = nchar(document), large_word_count =
sum(ifelse((nchar(word) > 7), 1, 0)), small_word_count =
sum(ifelse((nchar(word) < 3), 1, 0)), #assign more weight to these words using "10" below
explicit_word_count =
sum(ifelse(word %in% explicit_words$explicit_word, 10, 0)), #assign more weight to these words using "20" below
book_word_count =
sum(ifelse(word %in% book_words$top_word, 20, 0)), christian_word_count =
sum(ifelse(word %in% christian_words$top_word, 1, 0)), country_word_count =
sum(ifelse(word %in% country_words$top_word, 1, 0)), hip_hop_word_count =
sum(ifelse(word %in% hip_hop_words$top_word, 1, 0)), pop_rock_word_count =
sum(ifelse(word %in% pop_rock_words$top_word, 1, 0))
) %>%
select(-word) %>%
distinct() %>% #to obtain one record per document
ungroup()
features$genre <- as.factor(features$genre)
return(features)
}
现在, 为你的训练和测试数据集调用features()函数。
train <- features_func_genre(five_sources_tidy)
test <- features_func_genre(five_sources_test_tidy)
机器学习过程
如果你以前没有使用过mlr软件包, 那没关系。你将逐步进行它, 并看到它实际上是一个简单的过程。再次, 我强烈建议你阅读本教程, 因为它是你可以在此软件包中找到的最全面的文档。你也可以访问mlr.org。
mlr(R机器学习)是一个框架, 其中包含所有常用的机器学习算法。与其解释每种算法背后的理论, 不如着重于它们的实现。在本教程结束时, 你将使用许多分类工具, 并且如果与此处介绍的代码一起练习, 将可以最大程度地利用它。
一旦完成了功能工程, 机器学习的过程就很简单:创建任务, 学习, 培训, 测试。你将执行以下步骤:
- 创建分类器任务:声明数据集和结果(目标)变量
- 标准化数据:预处理(比例尺和中心距)
- 创建学习者列表:选择学习算法
- 选择一种重采样方法:选择一种在培训期间使用验证集评估绩效的方法
- 选择度量:创建度量列表, 例如准确性或错误率
- 进行培训/基准测试:根据任务和学习者比较模型的结果
- 调整最佳模型:选择表现最佳的学习者并调整超参数
- 测试新数据:针对从未见过的数据运行模型
分类器任务
任务仅仅是学习者在其上学习的数据集。由于这是分类问题, 因此你将使用makeClassifTask()创建分类任务。你需要通过将分类结果变量genre作为目标参数传递来指定它。
我在下面创建了三个任务, 每个任务都有不同的用途。测试和训练是显而易见的, 但是也有一个数据集仅使用由文档摘要和计数组成的基本定量特征。创建此任务task_train_subset时没有类型词计数功能(即country_word_count, pop_rock_word_count等), 以说明这些上下文预测变量在最终模型中的重要性。因此, 使用数据集train [3:13]删除这些变量。另外, 创建分类器任务时, 你始终要删除文本列。在这种情况下, 它们位于数据框中的位置1和2。
#create classification tasks to use for modeling
#this dataset does not include genre specific words
task_train_subset <- makeClassifTask(id = "Five Sources Feature Subset", data = train[3:13], target = "genre")
#create the training dataset task
task_train <- makeClassifTask(id = "Five Sources", data = train[-c(1:2)], target = "genre")
#create the testing dataset task
task_test <- makeClassifTask(id = "New Data Test", data = test[-c(1:2)], target = "genre")
规范化数据
规范化数据是一个需要稍作研究的主题, 并不总是必需的, 并且取决于数据集。但是, 在这种情况下, 这是有益的。这只是一种缩放数据的方法, 以使所有值在零和一(或你传递的任何值)之间归一化。如果某些变量的值比其他变量大得多, 并且比例不同, 则它们将通过赋予这些变量更多的权重而偏离你的模型。规范化解决了这个问题。这是该主题的一个好话题。由于这是预处理的重要步骤, 因此绝对值得进一步研究。 mlr为此步骤提供了一个简单的函数, 称为normalizeFeatures()。
#scale and center the training and test datasets
task_train_subset <- normalizeFeatures(task_train_subset, method = "standardize", cols = NULL, range = c(0, 1), on.constant = "quiet")
task_train <- normalizeFeatures(task_train, method = "standardize", cols = NULL, range = c(0, 1), on.constant = "quiet")
task_test <- normalizeFeatures(task_test, method = "standardize", cols = NULL, range = c(0, 1), on.constant = "quiet")
创建学习者列表
通过调用makeLearner()来生成mlr中的学习者。在构造函数中, 你需要指定要使用的学习方法。你可以通过调用listLearners(” classif”)[c(” class”, ” package”)]获得可能的分类算法的列表。这将向你显示你必须选择的算法及其依赖的程序包(可能需要单独安装)。
在本练习中, 我选择了一个列表, 该列表可以处理两个以上的类, 并且将为你提供广泛的技术, 从决策树到随机森林, 支持向量机, 梯度提升和神经网络。有许多学习者可供选择(目前, 在mlr中有80多个分类学习者), 我鼓励你与他们一起玩耍!
#create a list of learners using algorithms you'd like to try out
lrns = list(
makeLearner("classif.randomForest", id = "Random Forest", predict.type = "prob"), makeLearner("classif.rpart", id = "RPART", predict.type = "prob"), makeLearner("classif.xgboost", id = "xgBoost", predict.type = "prob"), makeLearner("classif.kknn", id = "KNN"), makeLearner("classif.lda", id = "LDA"), makeLearner("classif.ksvm", id = "SVM"), makeLearner("classif.PART", id = "PART"), makeLearner("classif.naiveBayes", id = "Naive Bayes"), makeLearner("classif.nnet", id = "Neural Net", predict.type = "prob")
)
重采样
重采样是机器学习中必不可少的工具, 值得一本完全独立的教程。目前, 对它的基本了解可以帮助你完成此步骤。它涉及从训练集中重复抽取样本, 并在每个样本上重新拟合模型。这可能使你只能使用原始训练数据获得一次模型拟合所无法获得的信息。
重采样有几种方法, 但是在这里, 你将在调用makeResampleDesc()的调用中使用由” CV”表示的所谓的k倍交叉验证, 该返回返回重采样描述对象(rdesc)。此方法将数据集随机分为相等大小的k组(折叠)。第一个折叠用作验证集, 其余的折叠用于训练。在每个折叠上重复k次。捕获每次迭代的错误率, 并在最后平均。
如果这是你第一次处理重采样, 可能听起来像是希腊文, 但这是熟悉该概念的必不可少的第一步!在下面的示例中, 你将使用10倍交叉验证。 “对于分类, 通常希望在每一折中具有相同比例的分类。” (源)使用stratify = TRUE来确保发生这种情况。
有关在mlr中进行重采样的更多信息, 请参见本文。
# n-fold cross-validation
#use stratify for categorical outcome variables
rdesc = makeResampleDesc("CV", iters = 10, stratify = TRUE)
绩效考核
分类的典型目标是获得较高的预测精度并最大程度减少错误数量。从这个意义上讲, 所有类型的误分类错误都被认为具有相同的权重。但是, 在许多应用程序中, 不同类型的错误比其他错误具有更大的影响。例如, 如果你要对患者是否患有某种疾病进行分类, 那么实际上无法识别出疾病的错误分类可能会危及生命。不同的绩效指标解决了这些细微差别。但是, 对于歌词分析, 你将主要关注准确性和错误的基本度量。请记住, 准确性和错误率并不总是评估模型稳健性的最佳选择。这是一个重要的主题, 在本教程之外也应进行更多讨论。
准确度是所有做出的预测中正确预测的数量。为了检查模型的错误分类, 你还将查看一个混淆矩阵, 以查看事物的分类方式(预测与实际)。只需一分钟即可获得更多信息。现在, 只需设置感兴趣的度量列表即可。我在这里添加了三个度量, 但是你只需要查看acc。该链接将为你提供更多信息并说明性能指标。
#let the benchmark function know which measures to obtain
#accuracy, time to train
meas = list(acc, timetrain)
火车模型/基准
在mlr中, 你可以进行基准测试, 在该基准测试中将不同的算法(学习方法)应用于数据集。这使你可以根据感兴趣的特定度量(即准确性)比较算法。你将运行Benchmark()训练模型并生成BenchmarkResult对象, 你可以从该对象访问模型和结果。
功能子集
最后, 是时候建立模型了。从你创建的不包括特定类型词数的任务开始。通过基准测试你的学习者列表, 子任务, 重采样策略(rdesc)以及你想查看的度量列表。
#it would be best to loop through this multiple times to get better results
#so consider adding a for loop here!
set.seed(123)
bmr <- benchmark(lrns, task_train_subset, rdesc, meas, show.info = FALSE)
#I'm just accessing an aggregated result directly so you can see
#the object structure and so I can use the result in markdown narrative
rf_perf <- round(bmr$results$`Five Sources Feature Subset`$`Random Forest`$aggr[[1]], 2) * 100
## [1] "BenchmarkResult"
class(bmr)
bmr
## task.id learner.id acc.test.mean
## 1 Five Sources Feature Subset Random Forest 0.7282895
## 2 Five Sources Feature Subset RPART 0.6516754
## 3 Five Sources Feature Subset xgBoost 0.6871616
## 4 Five Sources Feature Subset KNN 0.6676070
## 5 Five Sources Feature Subset LDA 0.6632281
## 6 Five Sources Feature Subset SVM 0.6965042
## 7 Five Sources Feature Subset PART 0.6561634
## 8 Five Sources Feature Subset Naive Bayes 0.6184923
## 9 Five Sources Feature Subset Neural Net 0.7073271
## timetrain.test.mean
## 1 0.892
## 2 0.013
## 3 0.062
## 4 0.000
## 5 0.007
## 6 0.222
## 7 0.218
## 8 0.012
## 9 0.252
如果查看BenchmarkResult对象, 则可以看到所传递的每种算法的acc.test.mean。请注意, 这专门指测试。这是训练模型时在交叉验证中使用的验证数据集的所有样本的平均准确性。这与稍后将使用的测试数据集不同。这是另一个主题, 需要大量解释, 但请记住, 在交叉验证过程中会保留一系列验证数据集, 并在确定之后使用一个测试数据集。算法并调整模型。
在此基准实验中, 你可以看到随机森林在r rf_perf百分比上表现最佳(并且花费了最长的训练时间)。牢记这一价值, 请在完整功能集上重新运行此实验。
完整功能集
这次通过的任务包括每个文档的特定类型的字数统计。这会添加一些功能, 以指示一首歌曲是否包含更多的乡村单词或流行摇滚单词等。请记住, 使用标记的数据集, 你选择了最常见的嘻哈单词, 并将它们放在称为hip_hop_words的列表中。这有暴徒, 婴儿床和毒品之类的词。国家/地区字词清单包含寂寞, 煤炭, 醉酒和牲畜之类的东西。你明白了。
mlr提供了几种访问基准测试结果的方法。我将只使用其中一些, 但是为了使基准对象满意, 我建议使用getBMR * getter函数。如果你在BenchMark对象上调用str(), 则将等待相当长的一段时间, 以便它返回详细信息!
在详细查看完整功能集之前, 花一点时间对多个任务进行基准测试, 然后使用plotBMRSummary()getter函数将完整功能集与上述功能子集进行比较。为此, 创建一个任务列表以传递给Benchmark()。
#always set.seed to make sure you can replicate your results
set.seed(123)
task_list <- list(task_train, task_train_subset)
bmr_multi_task <- benchmark(lrns, task_list, rdesc, meas, show.info = FALSE)
plotBMRSummary(bmr_multi_task)
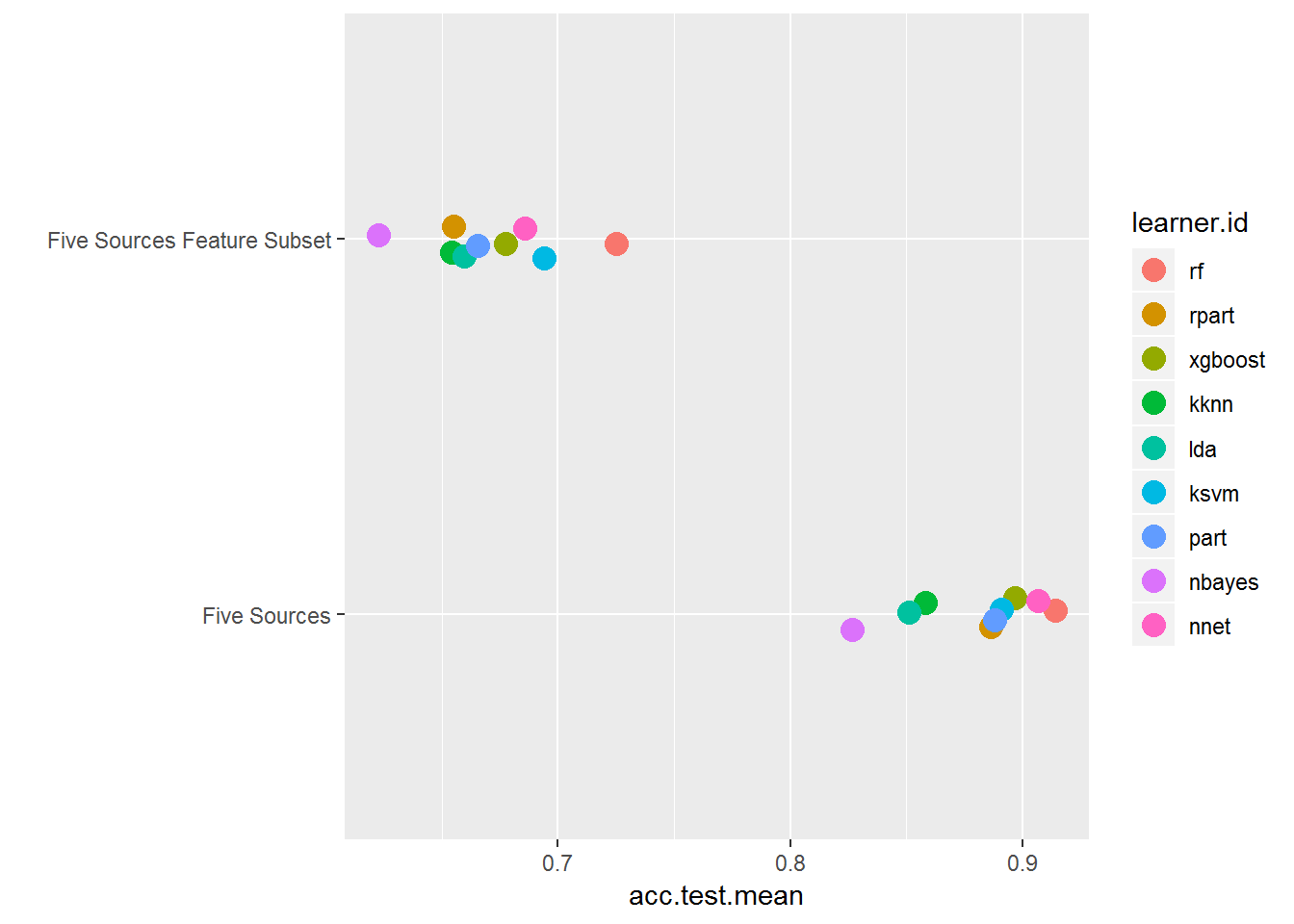
在这里, 你可以看到训练子集的acc.test.mean, 而每个文档的流派特定字数均低于完整功能数据集。这表明这些功能有很大的不同!仅在使用文本进行机器学习时, 你才能看到执行这一创造性的小步骤。可以将其放在你自己的项目的后兜里, 这是很好的。
尽管你只能从bmr_multi_task中访问训练结果, 但仅通过训练任务再次进行基准测试, 然后使用getBMRAggrPerformances()和plotBMRBoxplots()仔细查看结果。
set.seed(123)
bmr = benchmark(lrns, task_train, rdesc, meas, show.info = FALSE)
plotBMRSummary(bmr)
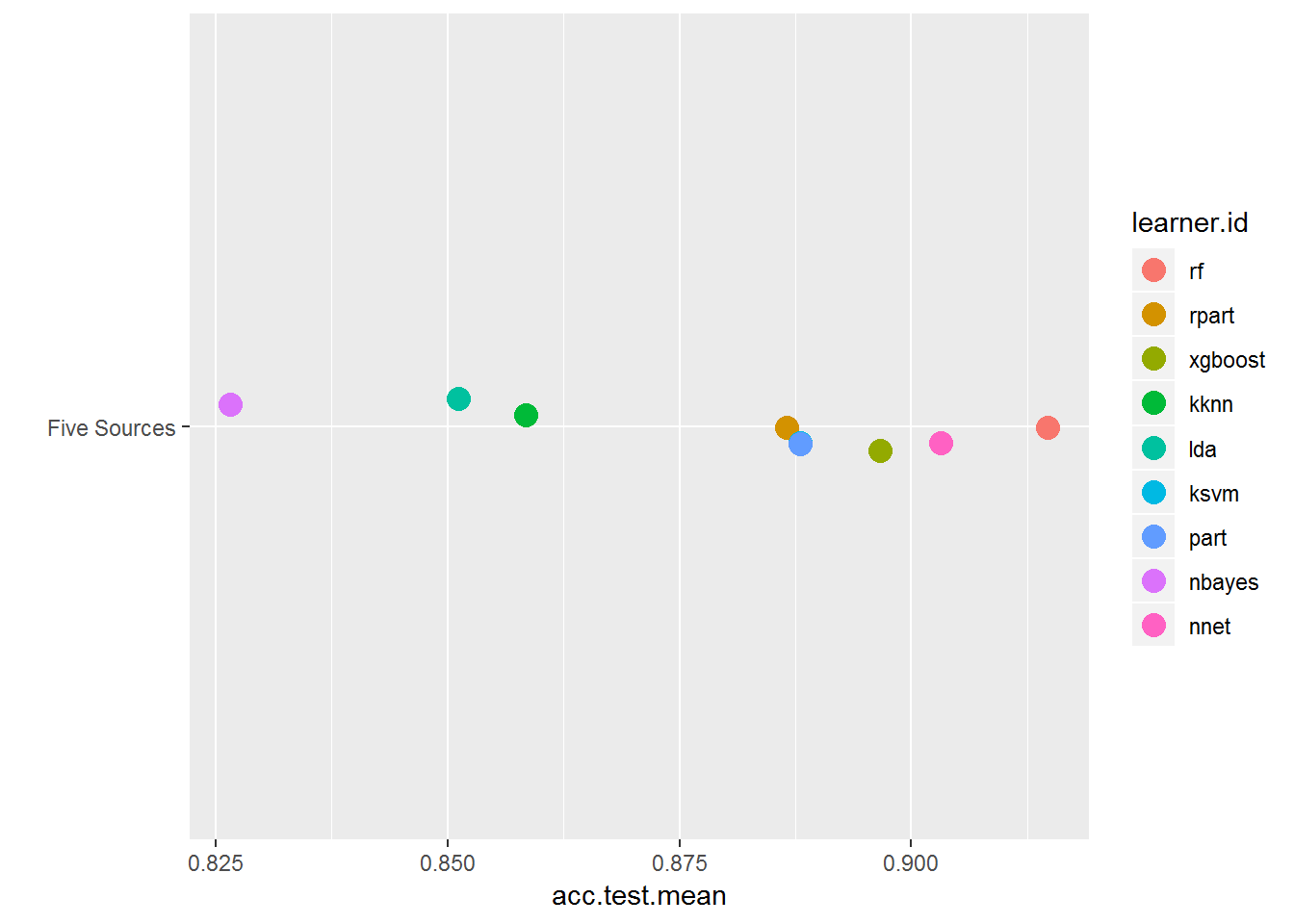
这仅允许你放大功能齐全的数据集结果的结果。现在, 你可以更清楚地看到算法之间的差异以及随机森林如何胜过其他算法。
plotBMRBoxplots(bmr, measure = acc, style = "violin", pretty.names = FALSE) +
aes(color = learner.id) +
ylab("Accuracy") +
theme(strip.text.x = element_text(size = 8))
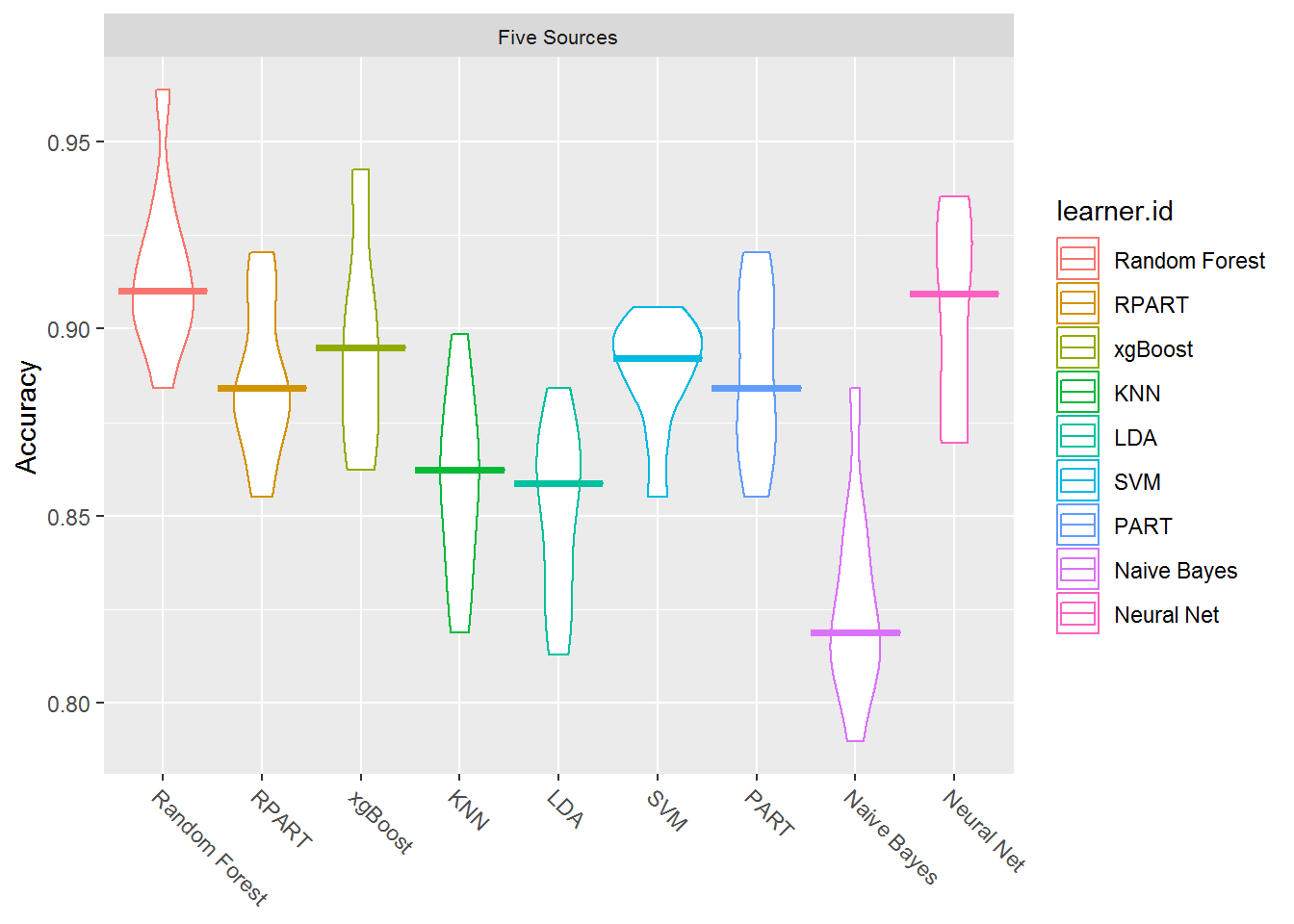
这些箱线图显示了基准测试执行的多次迭代中每种方法的结果。
performances <- getBMRAggrPerformances(bmr, as.df = TRUE) %>%
select(ModelType = learner.id, Accuracy = acc.test.mean) %>%
mutate(Accuracy = round(Accuracy, 4)) %>%
arrange(desc(Accuracy))
#just for use in markdown narrative
first_three <- round(performances$Accuracy[1:3], 2) * 100
performances %>%
my_kable_styling("Validation Set Model Comparison")
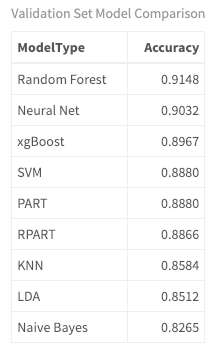
在这里, 你可以看到随机森林, 神经网络和xgBoost的精度最高, 分别为r first_th三个百分比。那么, 该模型真正发生了什么?这些文件/歌曲实际上是如何分类的?根据歌词分类最困难的类型是什么?要获得更多见解, 请查看预测的混淆矩阵。在此矩阵中, 正确分类的文档数出现在对角线上。分类错误的文档位于对角线上。错误观察计数在边缘。列代表预测值, 行代表真实值。使用getBMRPredictions()访问训练/验证集预测。然后查看随机森林模型的混淆矩阵的结果, 你可以使用之前标记为训练任务的五个来源ID来访问该矩阵。 (请注意, 你可以对基准测试结果中的任何模型执行此操作。)
predictions <- getBMRPredictions(bmr)
calculateConfusionMatrix(predictions$`Five Sources`$`Random Forest`)$result %>%
my_kable_styling("Random Forest Confusion Matrix: Rows are True, Columns are Predictions")
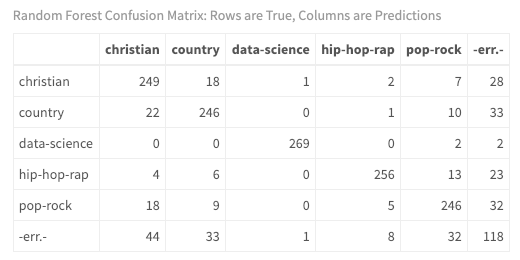
你终于对模型有了一些了解!如你所料, 仅使用一种错误分类, 使用你设计的文本元数据功能相对容易地将数据科学文档与歌曲歌词区分开。此外, 嘻哈说唱乐与其他音乐流派非常不同, 只有八种错误分类。然而, 尽管演奏令人印象深刻, 但乡村, 基督教和流行摇滚音乐歌词之间的区别却很小。
本教程的重点不仅是要接触预测性机器学习技术, 而且还要进行歌词分析, 作为本系列以前教程的延续。因此, 请考虑一下这些结果的含义。如果你正在开发一个建议系统, 并带有抒情见解, 那么你应该考虑哪些方面?你的系统是否有可能向基督教音乐听众或乡村音乐迷推荐带有明确歌词的嘻哈艺术家?
还记得教程开始时的和弦图吗?重新看一下, 这次是预测而不是真实的标签。
train$id <- seq_len(nrow(train))
df <- predictions$`Five Sources`$`Random Forest`$data
chart <- train %>%
inner_join(predictions$`Five Sources`$`Random Forest`$data) %>%
group_by(source, response) %>%
summarise(n())
circos.clear() #very important! Reset the circular layout parameters
#assign chord colors
grid.col = c("christian" = my_colors[1], "pop-rock" = my_colors[2], "hip-hop-rap" = my_colors[3], "data-science" = my_colors[4], "country" = my_colors[5], "amy-grant" = my_colors[1], "prince" = my_colors[2], "eminem" = my_colors[3], "machine_learning" = my_colors[4], "johnny-cash" = my_colors[5])
# set the global parameters for the circular layout. Specifically the gap size
circos.par(gap.after = c(rep(5, length(unique(chart[[1]])) - 1), 15, rep(5, length(unique(chart[[2]])) - 1), 15))
chordDiagram(chart, grid.col = grid.col, transparency = .2)
title("Predicted Relationship Between Genre and Source - Train")
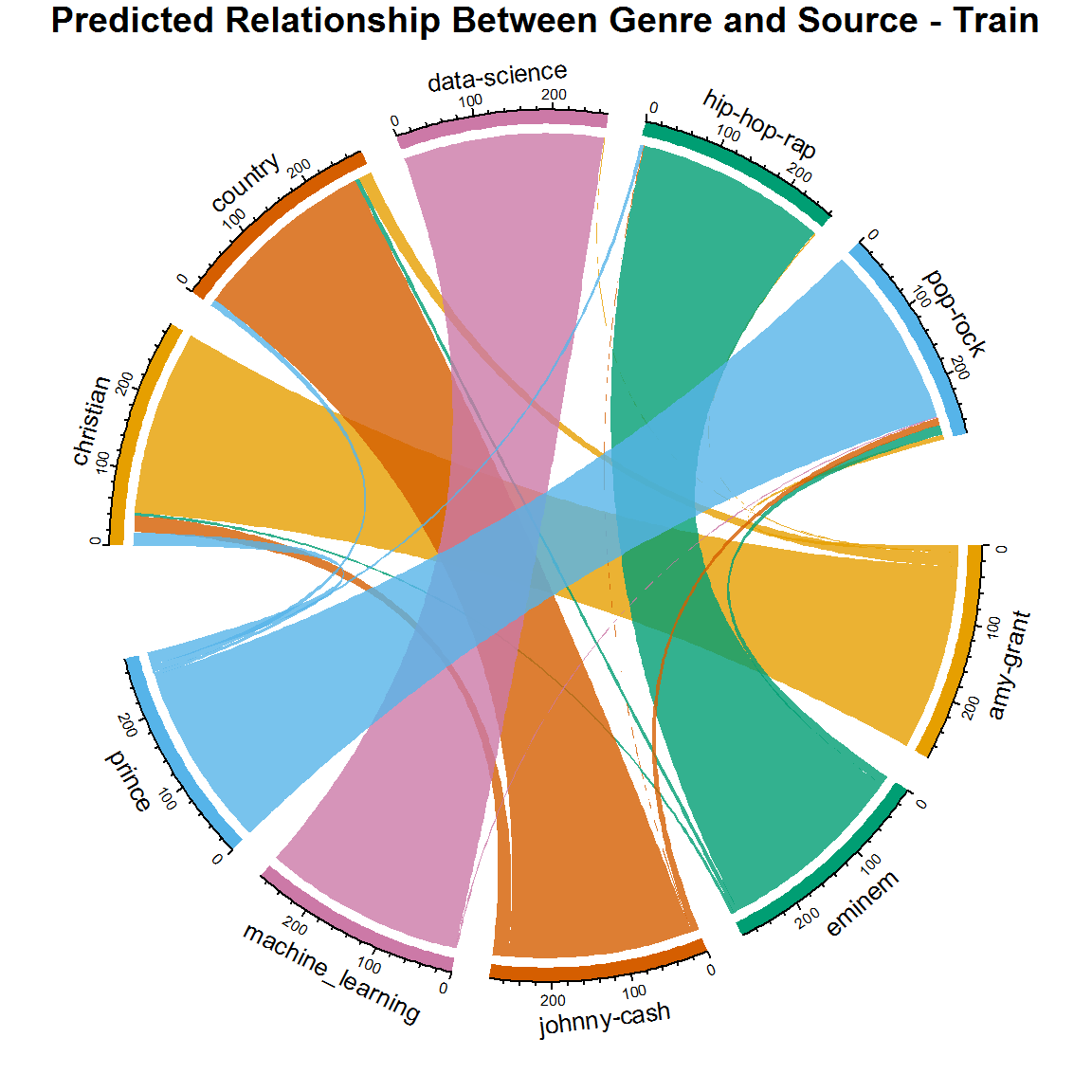
很酷现在你可以看到你在训练数据上的表现如何。结果再一次令人印象深刻。较小的线表示错误分类。但是, 这可能是你可以从本教程中学到的最重要的概念:即使这是验证集准确性结果, 它仍然基于标记的训练数据集!如果不小心, 可能会过度拟合模型并引入高方差。高方差意味着你的学习算法会根据你提供的数据而有很大差异。这可能意味着你的算法可能无法抵抗可能因以前从未见过的新数据引入的噪声。当你输入模型全新的数据时, 你将在短时间内对模型进行真实的测试。
在测试新数据之前, 你需要选择一种模型并对其进行调整。你可以通过调整其超参数来实现。这只是个花哨的词, 意思是配置模型的参数以提高其性能。如果你最近访问过Kaggle, 你会注意到一种称为极限梯度提升的流行算法, 该算法主导了比赛。即使它不是我们基准测试中性能最高的模型, 我仍然会选择它来调整和运行我们的测试数据集。如果你是这种算法的新手, 那么调整可能会很困难。在本教程的范围内, 我无法介绍极端梯度增强甚至超参数背后的概念, 但是下面的代码将为你提供一个起点。我强烈建议你在深入调整参数之前先回顾一下梯度增强的概念。该链接提供了Grover王子的精彩文章, 可以帮助你入门。正如他所描述的, 这是经典渐变增强的一般摘要:
首先使用简单模型对数据进行建模, 然后分析数据是否存在错误。这些错误表示难以通过简单模型拟合的数据点。然后, 对于以后的模型, 尤其要关注那些难以拟合的数据以使其正确。最后, 通过为每个预测变量赋予一些权重来合并所有预测变量。
(请注意:下面的makeTuneControlRandom()中的maxit值150需要花费一些时间才能运行。你可能希望以较小的东西开始。)
调整模型-xgBoost
#experiment here!! this is where you can really improve your model
xgb_params <- makeParamSet(
makeDiscreteParam("booster", values = c("gbtree")), makeIntegerParam("nrounds", lower=10, upper=20), makeIntegerParam("max_depth", lower = 4, upper = 6), makeNumericParam("min_child_weight", lower = 1L, upper = 10L), makeNumericParam("subsample", lower = 0.5, upper = 1), makeNumericParam("colsample_bytree", lower = 0.5, upper = 1), makeNumericParam("eta", lower = .01, upper = .2)
)
control <- makeTuneControlRandom(maxit = 150L)
xglearn <- makeLearner("classif.xgboost", predict.type = "prob", id="tuned xgboost")
library(parallelMap)
parallelStartSocket(2)
set.seed(123)
tuned_params <- tuneParams(
learner = xglearn, task = task_train, resampling = rdesc, par.set = xgb_params, control = control, measures = acc, show.info = TRUE
)
xgb_tuned_learner <- setHyperPars(
learner = xglearn, par.vals = tuned_params$x
)
tuned_params$x
## $booster
## [1] "gbtree"
##
## $nrounds
## [1] 16
##
## $max_depth
## [1] 5
##
## $min_child_weight
## [1] 1.395328
##
## $subsample
## [1] 0.6397534
##
## $colsample_bytree
## [1] 0.7986664
##
## $eta
## [1] 0.1917797
你可以通过查看tuneParams()的输出来检查优化的参数。现在, 你要使用调整后的超参数创建一个新模型, 然后在训练数据集上进行重新训练。
lrns = list(makeLearner("classif.nnet", predict.type = "prob"), makeLearner("classif.PART", predict.type = "prob"), makeLearner("classif.randomForest", predict.type = "prob"), makeLearner("classif.xgboost", id="untunedxgboost" , predict.type = "prob"), xgb_tuned_learner)
set.seed(123)
bmr = benchmark(lrns, task_train, rdesc, meas)
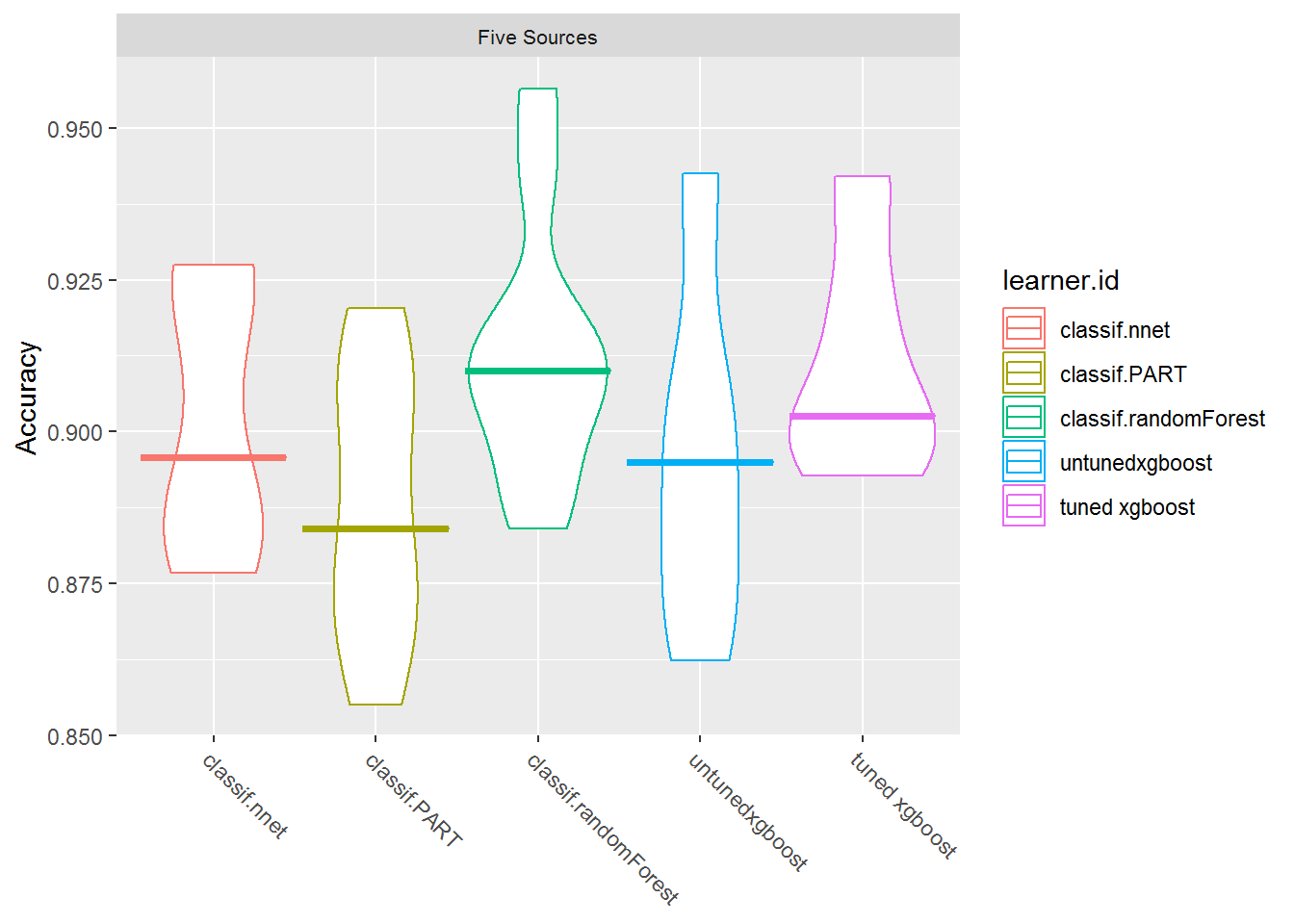
plotBMRBoxplots(bmr, measure = acc, style = "violin", pretty.names = FALSE) +
aes(color = learner.id) +
ylab("Accuracy") +
theme(strip.text.x = element_text(size = 8))
performances <- getBMRAggrPerformances(bmr, as.df = TRUE) %>%
select(ModelType = learner.id, Accuracy = acc.test.mean) %>%
mutate(Accuracy = round(Accuracy, 4)) %>%
arrange(desc(Accuracy))
# #used in markdown
# first_three <- round(performances$Accuracy[1:3], 2) * 100
performances %>%
my_kable_styling("Validation Set Model Comparison")

调整好的xgBoost模型仅比未调整的模型高一点, 并且仍然不如随机森林准确。但是它们如何对测试数据执行?
真实测试:新数据
现在你已经有了调整后的模型和基准, 你可以为测试数据集上从未见过的前三个模型调用predict()。如前所述, 这包括五个完全不同的来源。看一下它的性能和实际分类。
set.seed(12)
rf_model = train("classif.randomForest", task_train)
result_rf <- predict(rf_model, task_test)
performance(result_rf, measures = acc)
## acc
## 0.6541262
set.seed(12)
nnet_model = train("classif.nnet", task_train)
## # weights: 68
## initial value 2500.439406
## iter 10 value 876.420114
## iter 20 value 531.977942
## iter 30 value 412.756436
## iter 40 value 334.449379
## iter 50 value 304.202353
## iter 60 value 295.229853
## iter 70 value 286.347519
## iter 80 value 282.524065
## iter 90 value 280.438058
## iter 100 value 278.713625
## final value 278.713625
## stopped after 100 iterations
result_nnet <- predict(nnet_model, task_test)
performance(result_nnet, measures = acc)
## acc
## 0.631068
set.seed(12)
xgb_model = train(xgb_tuned_learner, task_train)
result_xgb <- predict(xgb_model, task_test)
test_perf <- performance(result_xgb, measures = acc)
test_perf
## acc
## 0.6492718
这些是非常有趣的结果。即使随机森林在训练数据上的准确性比调整后的xgBoost更高, 但在测试数据集上的准确性却稍差一些。神经网络的测试准确性也远低于训练。神经网络可能是非常灵活的模型, 因此可能会过度拟合训练集。
调整后的xgBoost的准确度为r round(test_perf, 2)* 100%, 与训练和调整相比, 测试数据的性能仍然显着下降(使用此最小配置!)。训练和测试之间的准确性下降是普遍存在的, 这正是为什么你应该在新数据上测试模型的原因。
现在, 看看实际的分类。
calculateConfusionMatrix(result_xgb)$result %>%
my_kable_styling("TEST: xgBoost Confusion Matrix: Rows are True, Columns are Predictions")
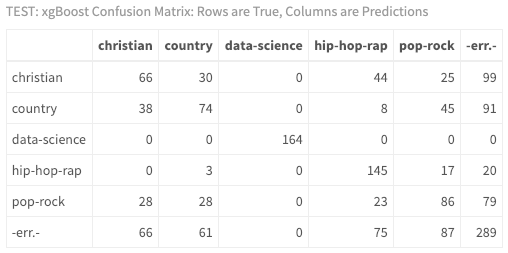
通过查看混淆矩阵, 你现在可以看出, 对这位嘻哈歌手Jay-Z进行分类要困难得多。如果你不懂音乐, 那没关系, 结果表明用来训练模型Eminem的艺术家与测试数据中使用的Jay-Z之间可能存在差异。理想情况下, 你将拥有更多的数据, 更多的艺术家, 更多的调音, 并且你将多次运行模型!
但是, 请考虑一下这可能会告诉你什么。再次查看和弦图:
test$id <- seq_len(nrow(test))
chart <- test %>%
inner_join(result_xgb$data) %>%
group_by(source, response) %>%
summarise(n())
circos.clear() #very important! Reset the circular layout parameters
#assign chord colors
grid.col = c("christian" = my_colors[1], "pop-rock" = my_colors[2], "hip-hop-rap" = my_colors[3], "data-science" = my_colors[4], "country" = my_colors[5], "chris-tomlin" = my_colors[1], "michael-jackson" = my_colors[2], "jay-z" = my_colors[3], "machine_learning_r" = my_colors[4], "patsy-cline" = my_colors[5])
# set the global parameters for the circular layout. Specifically the gap size
circos.par(gap.after = c(rep(5, length(unique(chart[[1]])) - 1), 15, rep(5, length(unique(chart[[2]])) - 1), 15))
chordDiagram(chart, grid.col = grid.col, transparency = .2)
title("Predicted Relationship Between Genre and Source - Test")
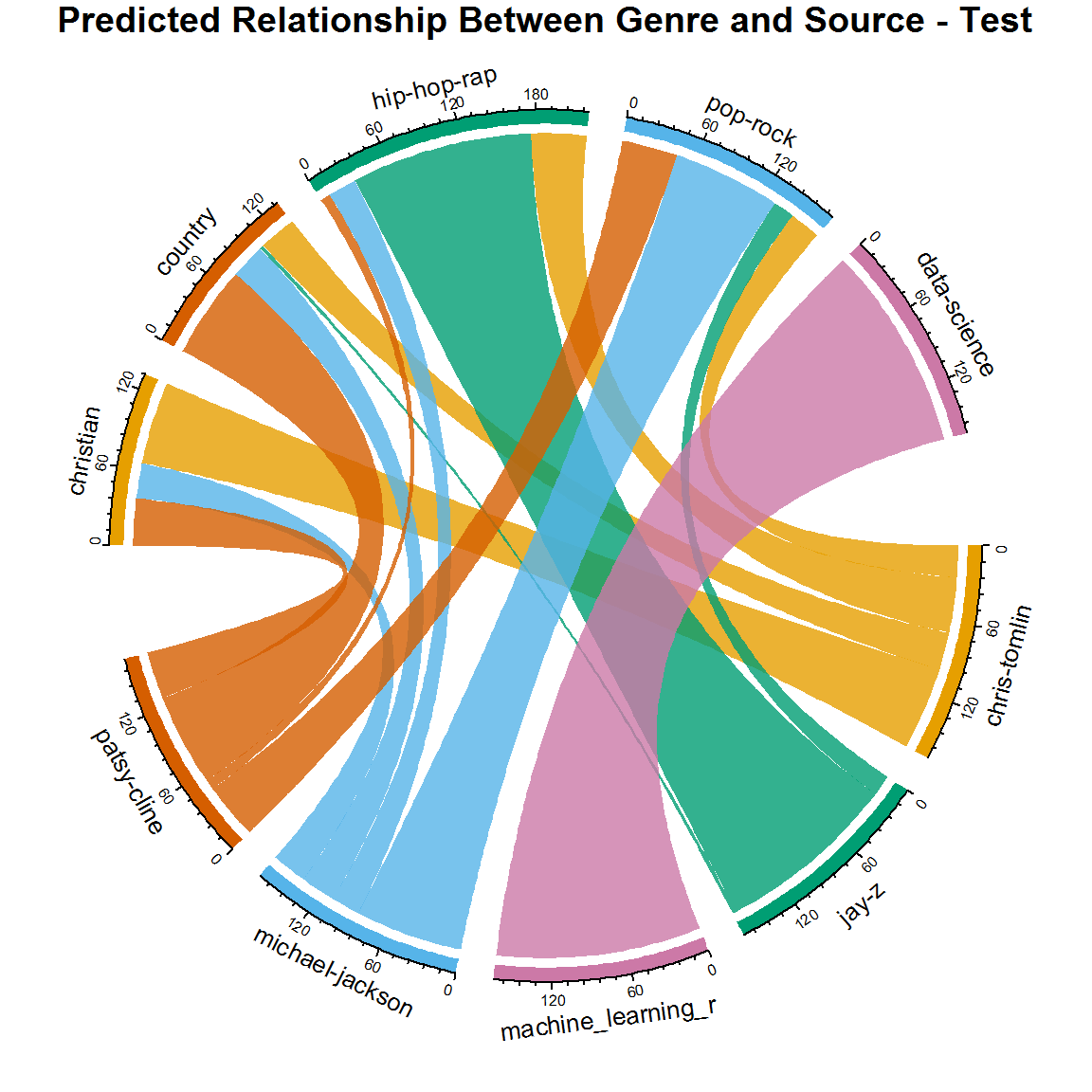
这是错的吗?它不准确吗?有见识吗?我认为你可以真正了解音乐世界。想一想:迈克尔·杰克逊(Michael Jackson)是否曾与说唱艺术家合作?他曾经唱歌过宗教话题吗?乡村艺术家曾经跨过流行摇滚吗?实际上, 你的新和弦图提供的歌词分类比原始数据集中显示的更为逼真的版本!实际上, 艺术家与现实生活中的流派之间并不存在一对一的关系, 而灵活性是内置于模型中的。
对于本教程的下一部分, 你将看到一个可以应用于市场营销, 销售, 科学, 经济学等领域的想法, 但是在这里, 你将把它应用于音乐。一首歌的成功是非常主观的。商业成功的概念更为清晰, 因为可以通过行业标准进行定义。广告牌图表(以及许多其他图表)是衡量这种成功的示例。如果你要为唱片公司工作, 并试图确定要签约的艺术家或要晋升的签约艺术家, 那么你是否可以使用科学的方法预测他们是否会根据其歌词在排行榜上排名, 这不会很有趣方法?你将需要大量当前数据和大量元数据来描述每首歌曲。由于你的资源有限, 因此请充分利用已有的数据, 并使用带有标签的图表数据在Prince的歌词中进行测试。
获取数据
在以前的教程中, 你创建了Prince歌曲的数据集, 其中大多数歌曲都是未知的。你将使用平衡的歌词集, 其中包含相同数量的图表歌曲和未知歌曲。这些是数字:
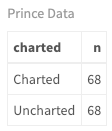
prince_charted_data <- read.csv("prince_data_balanced.csv", stringsAsFactors = FALSE)
prince_charted_data %>%
count(charted) %>%
my_kable_styling("Prince Data")
prince_tidy <- prince_charted_data %>%
unnest_tokens(word, lyrics) %>%
anti_join(stop_words)
特征工程
使用与上述相同的过程, 使用两步过程创建要素。这次, 你将按图表级别对单词进行计数, 而不是对歌曲中每种流派的单词进行计数。换句话说, 获取已绘制图表的歌曲的最常用单词, 以及未绘制图表并将其存储在列表中的歌曲的最常用单词。我选择使用1000个单词, 并且用这个数字似乎得到了最好的答复。发挥自己的价值观。然后, 在创建歌曲功能时, 请确保添加这两个功能, 以计算每首歌曲每个列表中的单词数(与上述流派相同的过程)。
再次注意, 我删除了出现在排行榜首位和未公开的歌曲中的所有单词。我还在原始输入的平方上添加了一些其他的多项式特征。机器学习方法的基础不是通过调整算法而是通过转换输入来改进模型。
number_of_words <- 1000
top_words_per_chart <- prince_tidy %>%
group_by(charted) %>%
mutate(chart_word_count = n()) %>%
group_by(charted, word) %>%
mutate(word_count = n(), word_pct = word_count / chart_word_count * 100) %>%
select(word, charted, chart_word_count, word_count, word_pct) %>%
distinct() %>%
ungroup() %>%
arrange(word_pct) %>%
top_n(number_of_words) %>%
select(charted, word, word_pct)
top_words <- top_words_per_chart %>%
ungroup() %>%
group_by(word) %>%
mutate(multi_chart = n()) %>%
filter(multi_chart < 2) %>%
select(charted, top_word = word)
charted_words <- lapply(top_words[top_words$charted == "Charted", ], as.character)
uncharted_words <- lapply(top_words[top_words$charted == "Uncharted", ], as.character)
features_func_chart <- function(data, remove) {
features <- data %>%
group_by(song) %>%
mutate(word_frequency = n(), lexical_diversity = n_distinct(word), lexical_density = lexical_diversity/word_frequency, repetition = word_frequency/lexical_diversity, document_avg_word_length = mean(nchar(word)), title_word_count = lengths(gregexpr("[A-z]\\W+", song)) + 1L, title_length = nchar(song), large_word_count =
sum(ifelse((nchar(word) > 7), 1, 0)), small_word_count =
sum(ifelse((nchar(word) < 3), 1, 0)), charted_word_count =
sum(ifelse(word %in% charted_words$top_word, 1, 0)), uncharted_word_count =
sum(ifelse(word %in% uncharted_words$top_word, 1, 0)), div_sq = lexical_diversity^2, den_sq = lexical_density^2, large_word_count2 = large_word_count^2
) %>%
select(-remove) %>%
distinct() %>% #to obtain one record per document
ungroup()
features$charted <- as.factor(features$charted)
return(features)
}
#remove these fields from the passed dataframe
remove <- c("word", "X", "X.1", "year", "album", "peak", "us_pop", "us_rnb", "decade", "chart_level")
song_summary <- features_func_chart(prince_tidy, remove)
设置和训练
通过为Prince数据集创建一个分类器任务(目标为图表字段), 执行与上述步骤相同的步骤。规范化数据, 设置交叉验证并创建学习者列表。我在这里添加了一些不同的算法, 因为你将要进行二进制分类, 而不是像以前那样进行多类分类。
task_prince <- makeClassifTask(id = "Prince", data = song_summary[-1], target = "charted")
task_prince <- normalizeFeatures(task_prince, method = "standardize", cols = NULL, range = c(0, 1), on.constant = "quiet")
# n-fold cross-validation
rdesc <- makeResampleDesc("CV", iters = 10, stratify = TRUE)
## Create a list of learners
lrns = list(
makeLearner("classif.randomForest", id = "Random Forest"), makeLearner("classif.logreg", id = "Logistic Regression"), makeLearner("classif.rpart", id = "RPART"), makeLearner("classif.xgboost", id = "xgBoost"), makeLearner("classif.lda", id = "LDA"), makeLearner("classif.qda", id = "QDA"), makeLearner("classif.ksvm", id = "SVM"), makeLearner("classif.PART", id = "PART"), makeLearner("classif.naiveBayes", id = "Naive Bayes"), makeLearner("classif.kknn", id = "KNN"), makeLearner("classif.nnet", id = "Neural Net")
)
set.seed(123)
bmr_prince = benchmark(lrns, task_prince, rdesc, meas, show.info = FALSE)
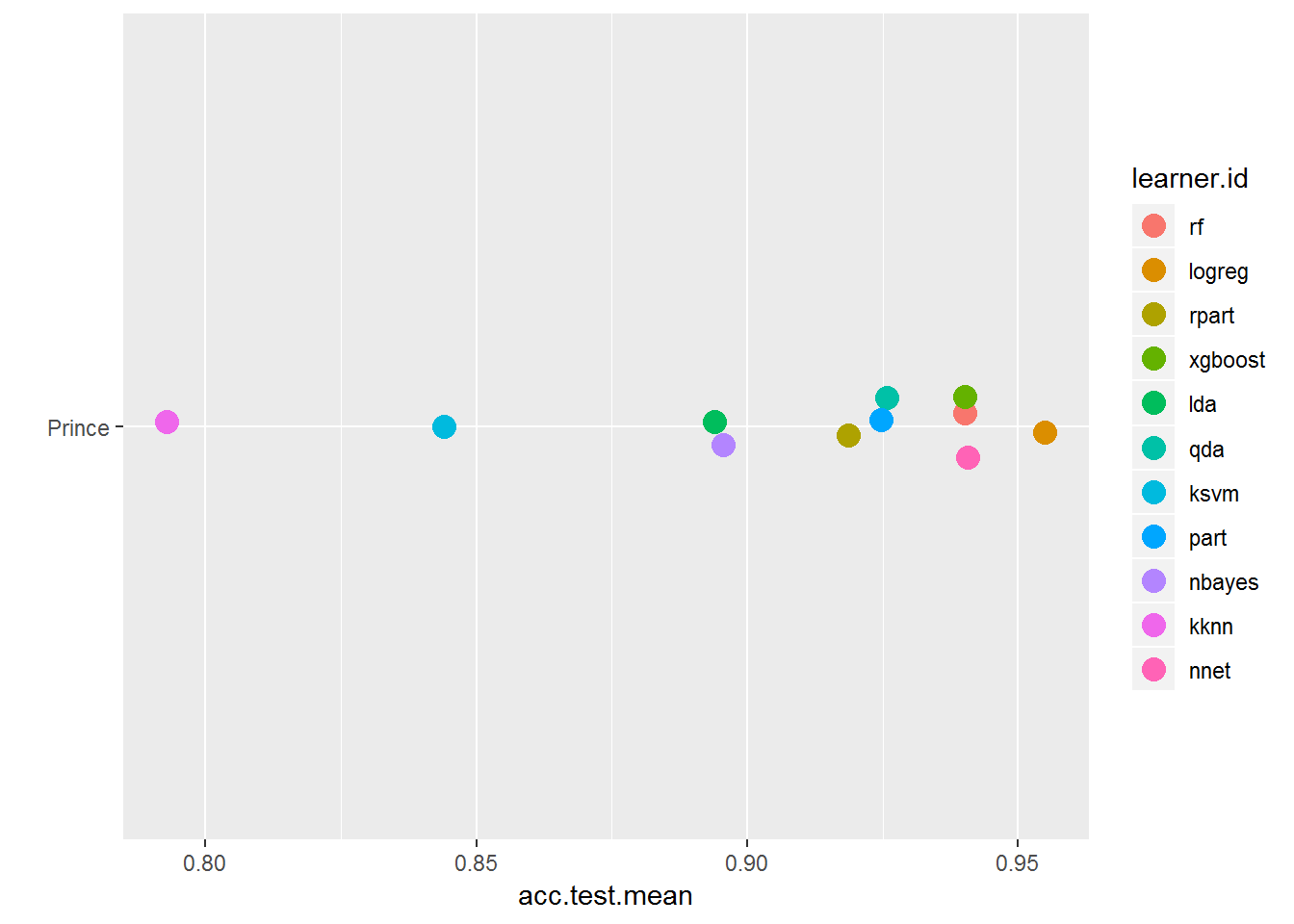
现在, 你已经创建了基准, 以多种格式检查结果。请注意, 学习者的表现与上述不同。
plotBMRSummary(bmr_prince)
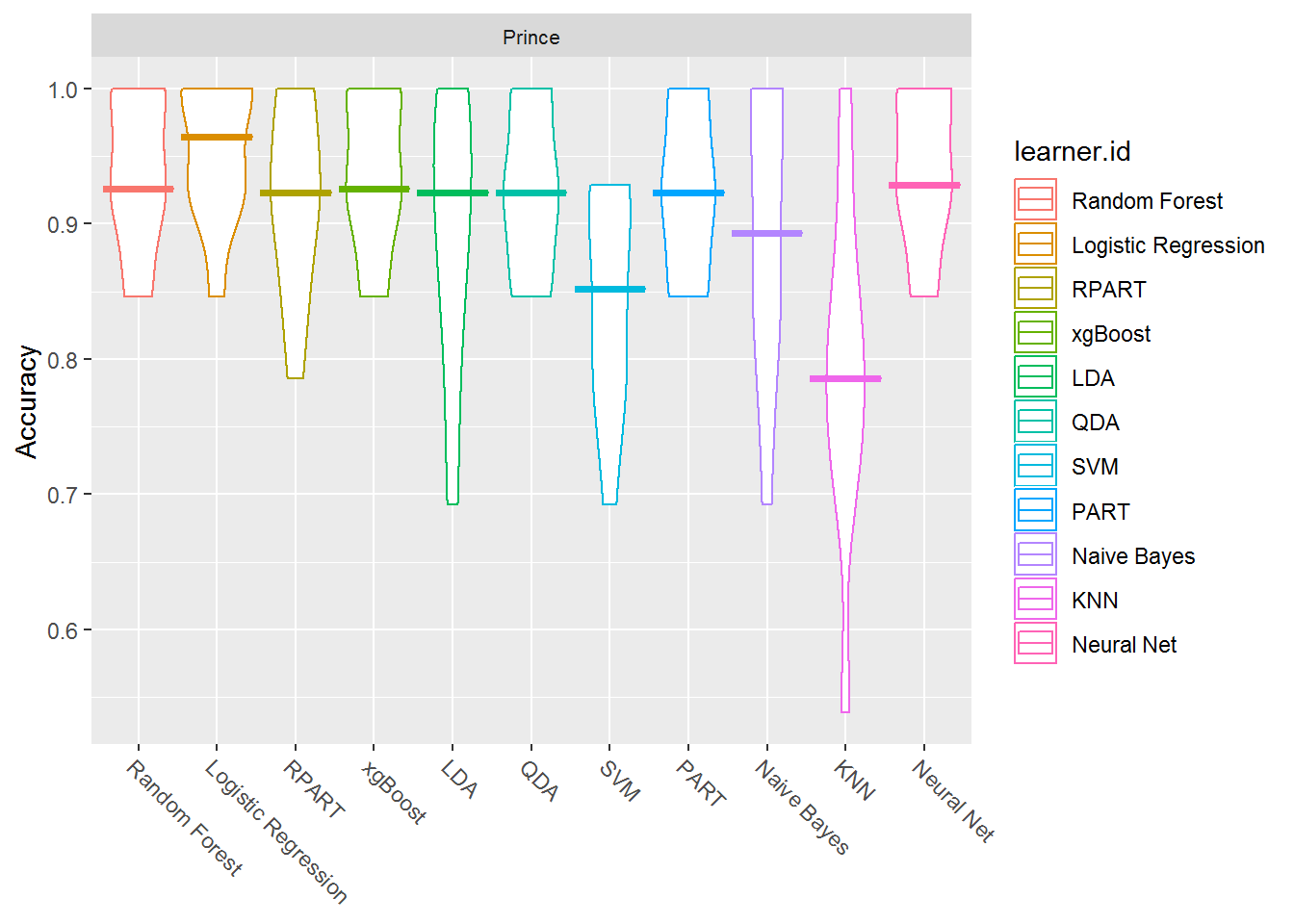
plotBMRBoxplots(bmr_prince, measure = acc, style = "violin", pretty.names = FALSE) +
aes(color = learner.id) +
ylab("Accuracy") +
theme(strip.text.x = element_text(size = 8))
#with knn so you can see the numbers
getBMRAggrPerformances(bmr_prince, as.df = TRUE) %>%
select(ModelType = learner.id, Accuracy = acc.test.mean) %>%
mutate(Accuracy = round(Accuracy, 4)) %>%
arrange(desc(Accuracy)) %>%
my_kable_styling("Validation Set Model Comparison")
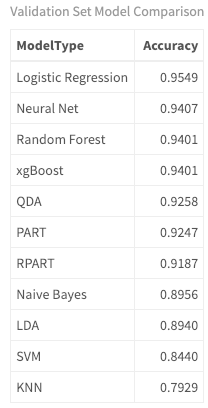
在预测图表级别时, 你现在正在处理两类问题。只有两个选项:图表或未知。在对类型进行分类时, 你遇到了一个多类问题, 其中可能有两个以上的类。 (请注意, 这与多标签问题不同, 在多标签问题中, 观察值可以具有多个类。这可能是要研究的问题!)。由于这是一个二项式分类问题, 因此我添加了两个不同的算法:QDA和Logistic回归。这两个更适合于两类问题。
Logistic回归用于二进制结果, 并为观察(歌曲)属于特定类别的概率建模。它基于默认值为0.5的阈值。例如, 概率大于.5的任何事物都属于目标类别, 而低于此阈值的任何事物均属于另一个类别。此阈值是可调的。 QDA是二次判别分析的缩写, 对于处理二次决策与线性决策边界更灵活。好的, 在没有更多信息的情况下抛弃技术术语对我来说是不公平的, 所以请花点时间查看必须使用的数据, 性能良好的算法, 并分别研究每个算法。我希望这种分析能吸引你去研究细节!
下一步是运行你的预测并查看分类。
predictions <- getBMRPredictions(bmr_prince)
calculateConfusionMatrix(predictions$Prince$`QDA`)$result %>%
my_kable_styling("Logistic Regression Confusion Matrix: Rows are True, Columns are Predictions")

分类错误
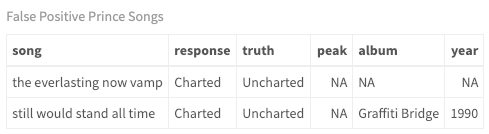
查看模型如何对每首歌曲进行分类非常容易。对于二进制分类, 有很多检查方法。就目前而言, 只看一下误报率-即实际上预测哪些歌曲未排在前100名之列。
false_positives <- as.data.frame(predictions$Prince$`QDA`) %>%
filter(truth == "Uncharted" & response == "Charted")
song_summary$id <- seq_len(nrow(song_summary))
song_summary %>%
inner_join(false_positives) %>%
inner_join(prince_charted_data) %>%
select(song, response, truth, peak, album, year) %>%
my_kable_styling("False Positive Prince Songs")
测试在哪里?
即使在训练模型时使用了交叉验证, 也应始终针对单独的数据集运行该模型(就像你对上述类型所做的那样)。我已将其留给你作为练习, 希望你对你的结果留下反馈。为了使这成为对歌词分析背后的预测能力的真实考验, 最现实的结果将来自像普林斯这样的流行摇滚风格中的另一位艺术家。另一个因素是时间段。这些歌曲大多是在70年代, 80年代和90年代录制的, 因此同一时期的歌手至关重要。或者, 选择你自己的艺术家进行培训和测试数据, 然后看看你能得到什么!
在本教程中, 你建立了一个模型来完全基于歌词来预测歌曲的流派。你对五种不同的艺术家和五种不同的类型使用了监督的机器学习分类算法和经过训练的模型。通过使用mlr框架, 你创建了任务, 学习者和重采样策略以训练然后调整模型。然后, 你针对未知艺术家的测试数据集运行模型。你可以确定哪种算法在默认设置下效果更好, 并最终预测出你的模型从未见过的新歌曲的类型。
关于歌词分析, 应该清楚的是, 即使音乐界(和广告牌图表)为每个艺术家都预先定义了流派, 但你的分析暗示根据歌词, 歌曲跨过流派, 通常不存在一对一的关系。 (我自己是一名词曲作者, 我的类型标语是”笨拙, 声学, 摇滚般的灵魂!”)。你还可以使用相同的技术来模拟一首歌曲是否完全基于歌词而在排行榜上排名靠前, 而且训练数据的准确性也很高。现在的任务是将这些知识应用于你自己的数据集!
在涉及歌词分析的整个三部分(共四个教程)的系列文章中, 我一直很乐意与你合作。希望你已经体会到与其他形式的文本(即非小说)相比, 使用这种类型的文本的复杂性以及歌词所涉及的微妙之处。希望你学习了新技能, 并能启发自己使用自己的数据来获取对你感兴趣的新主题的见解。机器学习是一个令人兴奋的领域, 作为新的或经验丰富的数据科学家, 创造力, 灵感和毅力将使你与众不同。因此, 请记住在四边形平行四边形之外思考并享受你的学习冒险!
“我将脚踩在起跑线上, 进入了崭新的一天。我在风中吹了个吻, 闭上了眼睛, 消除了恐惧。-黛比·利斯克, 新的一天。”
(顺便说一句, 我已经写了超过100首自己的歌曲, 并在音乐上运行了最后一个模型。它预测我的35首歌曲应该已经登上了排行榜!如果我更早知道这种技术的话!!也许我的下一篇文章应该是关于如何使用歌词分析来根据当下的歌手创作热门歌曲…)
进一步分析的主题!
我简要介绍了以下主题, 并鼓励你花时间对每个主题进行更深入的了解。
- 重复进行几次建模, 然后每次分别划分数据。
- 了解每种算法背后的概念, 以及为什么某些算法可以更好地处理某些数据集。
- 回顾性能测量的不同方面, 以及为什么根据用例, 某些方面比其他方面更重要。
- 了解如何针对不同类型的模型调整超参数
- 深入研究重采样(交叉验证和引导)并了解其目的。
- 考虑其他软件包而不是简单的mlr以获得更全面的知识
- 查看其他研究论文以及歌词分析领域中正在发生的事情。
请在评论部分提出任何问题!
以下是数据集的链接:
- Five_sources_data_balanced.csv
- Five_sources_data_test.csv
- explicit_words.csv
- prince_data_balanced.csv
评论前必须登录!
注册