 srcmini
srcmini在上一主题中, 我们学习了以不同的文件格式编写SAS数据集。现在, 在本主题中, 我们将学习如何使用SAS编程语言将多个数据集连接为单个数据集。
假设你在不同的数据集中有许多观测值, 并且需要在一个数据集中收集所有观测值, 然后你将做什么。为此, SAS可以帮助你将不同的数据集连接为一个数据集。
SET语句用于将不同的数据集连接为一个数据集。串联数据集存储原始数据集的所有观测值之和。串联数据集中的所有观察遵循这样的正确存储顺序, 首先是第一数据集的所有观察, 其次是第二数据集的所有观察, 依此类推。
理想情况下, 所有组合数据集应具有相同数量的变量, 但是如果它们具有不同数量的变量, 则所有变量都将出现在结果中, 而小型数据集的值将丢失。
句法:
SET data-set 1 data-set 2 data-set 3 data-set 4........;其中
Set:这是一条语句, 用于将不同的数据集连接为一个数据集。
数据集1数据集2:这些是要串联的数据集的名称。
现在, 让我们通过一个示例来了解如何连接数据集:
让我们考虑一个组织的员工数据, 该数据有两个单独的数据集, 一个用于培训部门, 另一个用于非培训部门。为了获得所有员工的全部详细信息, 我们需要将两个数据集连接起来。为此, 我们使用SET语句。
DATA Training_Dept;
INPUT empid name $ salary;
DATALINES;
101 Avinash 20000
103 Meera 25000
106 Tushar 27000
;
RUN;
DATA NON_Training_Dept;
INPUT empid name $ salary;
DATALINES;
102 Mitali 23000
104 Rohan 40000
105 Akanksha 45000
107 Prabhat 49000
108 Mohan 62000
RUN;
DATA All_Dept;
SET Training_Dept NON_Training_Dept;
RUN;
PROC PRINT DATA = All_Dept;
RUN;现在, 在SAS studio中执行以上代码:
输出
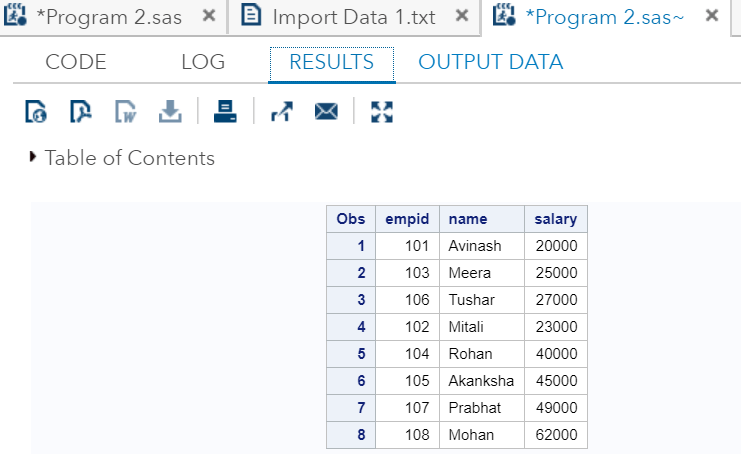
从输出中可以看到, 两个数据集都连接在一个表中。
不同情况
在某些情况下, 数据集的变量有所不同。在这种类型的不同情况下, 级联数据集中的观测总数始终等于每个数据集中的观测总数。让我们看看数据集变量具有变化的不同情况。
1.当变量数量不同时
如果所有数据集的变量数都不相等, 那么数据集仍然会串联在一起, 但是多余变量的值会在小数据集中消失。让我们通过一个例子来理解。
例如:
有两个要连接的数据集。一个是training_department, 具有五个变量, 即Empid, 姓名, 薪水, 地址和课程, 另一个是non_training_department, 具有三个变量, 即empid, 名称和薪水。在输出中, 数据集non_training_department的address和course值将消失。
DATA Training_Dept;
INPUT empid name $ salary address$ course$;
DATALINES;
101 Avinash 20000 delhi msoffice
103 Meera 25000 bhopal internet
106 Tushar 27000 indore database
;
RUN;
DATA NON_Training_Dept;
INPUT empid name $ salary;
DATALINES;
102 Mitali 23000
104 Rohan 40000
105 Akanksha 45000
107 Prabhat 49000
108 Mohan 62000
RUN;
DATA All_Dept;
SET Training_Dept NON_Training_Dept;
RUN;
PROC PRINT DATA = All_Dept;
RUN;现在, 在SAS studio中执行以上代码:
输出
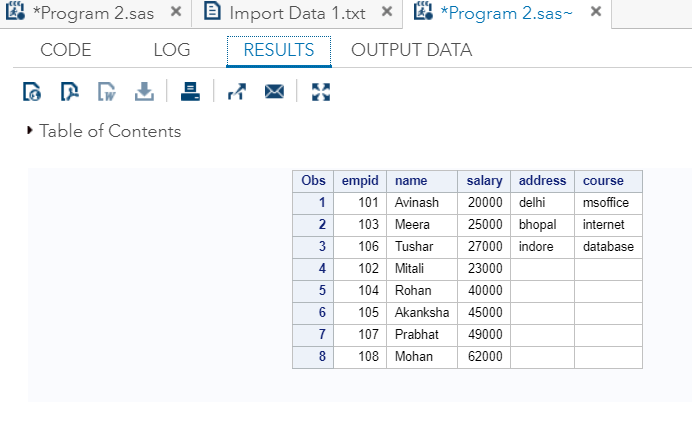
从输出中可以看到, 数据集non_training_department缺少地址和路线的值。
2.当不同的变量名
当所有数据集包含相同数量的变量, 但名称不同时, 在这种情况下, 我们可以通过应用重命名语句来连接数据集。如果我们不使用Rename语句, 那么SAS仍将连接数据集, 但是对于不同的名称变量, 它将产生丢失的结果。我们可以将Rename语句与为连接而创建的数据集一起应用。让我们通过一个例子来理解。
例如:
在下面的示例中, 我们有两个数据集, 一个是Training_Dept, 另一个是Non_Training_Dept。这两个数据集都有一个引用相同值(即名称)的变量, 但在两个数据集中用不同的名称声明。在数据集Training_Dept中, 变量按名称声明, 而在数据集Non_Training_Dept中, 按名称声明。为了连接它们, 我们在连接的数据集All_Dept上应用RENAME语句。
DATA Training_Dept;
INPUT empid name $ salary;
DATALINES;
101 Avinash 20000
103 Meera 25000
106 Tushar 27000
;
RUN;
DATA NON_Training_Dept;
INPUT empid ename $ salary ;
DATALINES;
102 Mitali 23000
104 Rohan 40000
105 Akanksha 45000
107 Prabhat 49000
108 Mohan 62000
RUN;
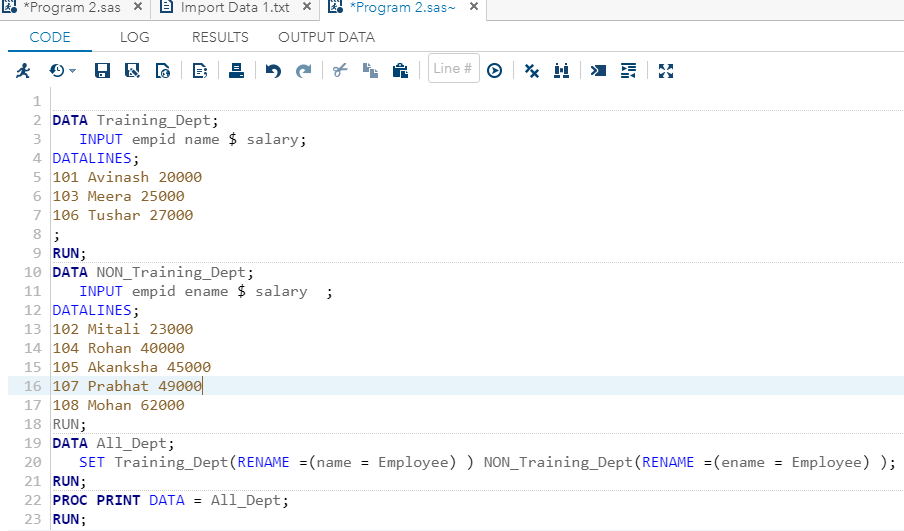
DATA All_Dept;
SET Training_Dept(RENAME =(name = Employee) ) NON_Training_Dept(RENAME =(ename = Employee) );
RUN;
PROC PRINT DATA = All_Dept;
RUN;现在, 在SAS studio中执行以上代码:
输出
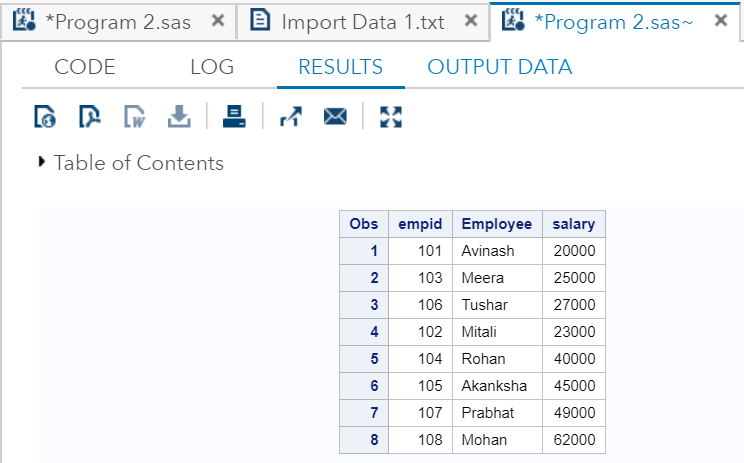
正如我们在输出中看到的那样, 雇员名称由变量Employee串联。
3.当变量的长度不同时
如果数据集中变量的长度不同, 则可以通过应用Length语句将它们连接起来。在连接数据集中应用Length语句时, 我们应该考虑使用更大的长度, 而不是使用较小的长度, 因为SAS会生成更长的容器, 可以轻松接受较小的长度值。
例如:
在下面的示例中, 变量名称在Training_Dept数据集中具有5的长度, 在Non_Training_Dept数据集中具有7的长度。串联时, 我们将长度设为8。
DATA Training_Dept;
INPUT empid 1-2 name $ 3-7 salary 8-14 ;
DATALINES;
1 Richa 632.3
3 Micha 521.5
6 Tusha 548.6
;
RUN;
DATA NON_Training_Dept;
INPUT empid 1-2 name $ 3-9 salary 10-16 ;
DATALINES;
2 Dany 515.2
4 Rian 629.1
5 Gury 743.25
7 Pranab 532.8
8 Rasmi 522.5
RUN;
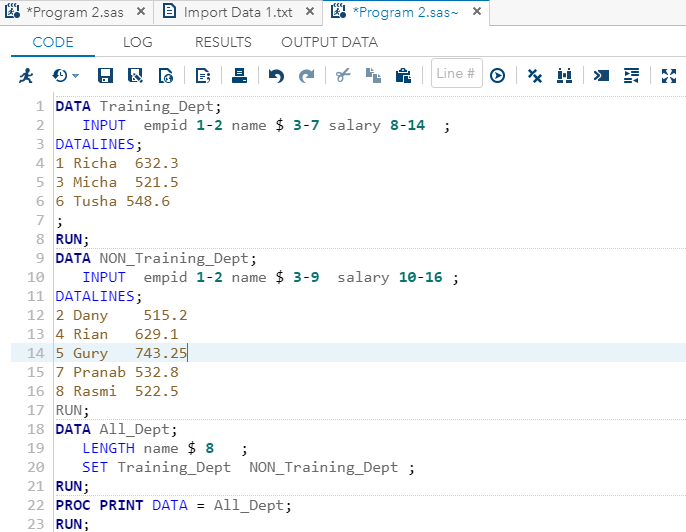
DATA All_Dept;
LENGTH name $ 8 ;
SET Training_Dept NON_Training_Dept ;
RUN;
PROC PRINT DATA = All_Dept;
RUN;在SAS Studio中执行以上代码:
输出
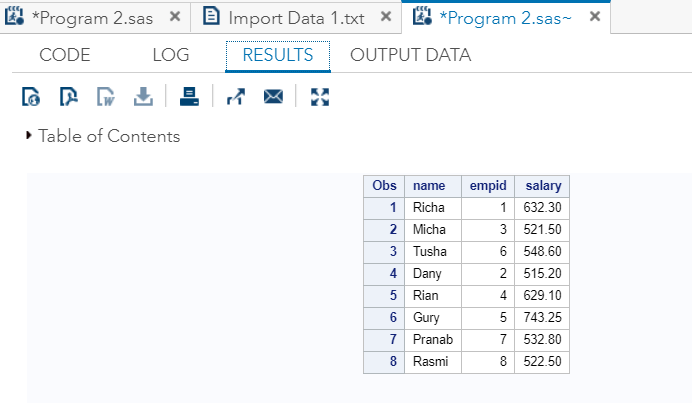
正如我们在输出中看到的那样, 变量名由更高的字符长度(即8)连接起来
评论前必须登录!
注册