 srcmini
srcmini本文概述
卷积神经网络是在神经网络中进行图像分类和图像识别的技术之一。它旨在通过多层阵列处理数据。这种类型的神经网络用于诸如图像识别或面部识别之类的应用中。 CNN与其他神经网络之间的主要区别在于CNN将输入作为二维数组。它直接在图像上运行, 而不是像其他神经网络那样专注于特征提取。
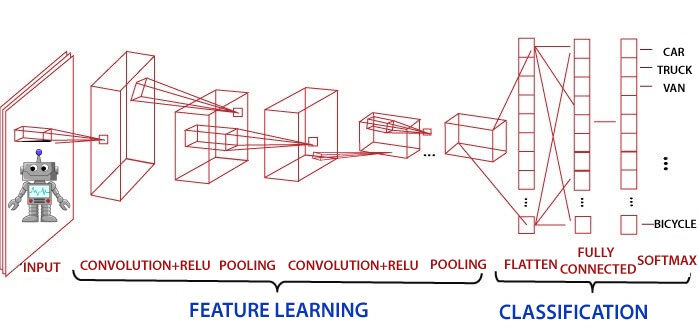
CNN的主要方法包括解决识别问题的方法。像Google和Facebook这样的一些公司已经在识别项目方面进行了现场研发, 以更快地完成活动。
场景标签, 物体检测和面部识别等是卷积神经网络工作的领域。
卷积神经网络(CNN或ConvNet)是一种前馈人工网络, 其神经元之间的连接方式受动物视觉皮层组织的启发。
视觉皮层有一小部分细胞, 对视野的特定区域敏感。我们大脑中的某些单个神经元细胞在存在特定方向的边缘时会做出反应。
卷积神经网络的起源
神经网络的智能是不自然的。虽然Rosenblatt早在1960年代就研究了人工神经网络, 但直到2000年代末, 使用神经网络的深度学习才开始兴起。关键推动因素是Google开展深度学习研究的计算能力和数据集的规模。 2012年7月, Google的研究人员针对从YouTube视频中切出的一系列未标记的静态图像公开了高级神经网络。
例如,
乍一看, 请考虑一下这种自然形象;我们将看到很多建筑物和颜色。
计算机如何读取图像?
图像分为3个颜色通道, 分别是红色, 绿色和蓝色。这些颜色通道中的每一个都映射到图像的像素。
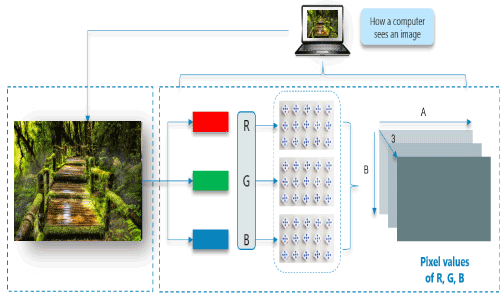
当暴露于顶点边缘时, 一些神经元会激发, 而当显示水平或对角线边缘时, 一些神经元会激发。 CNN利用与输入数据一起存在的空间相关性。神经网络的每个并发层都连接一些输入神经元。该区域称为局部感受野。局部感受野集中在隐藏的神经元上。
隐藏的神经元在提到的字段内处理输入数据, 而不实现特定边界之外的更改。
卷积神经网络具有以下4层
- 卷积
- ReLU层
- 汇集
- 完全连接
卷积层
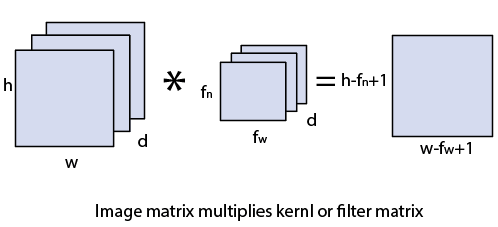
卷积层是从输入图像派生特征的第一层。卷积层通过使用输入数据的小方块学习图像特征来保存像素之间的关系。这是数学运算, 需要两个输入, 例如图像矩阵和核或任何滤波器。
- 图像矩阵的尺寸为h×w×d。
- 任何滤波器的尺寸为fh×fw×d。
- 输出尺寸为(h-fh + 1)×(w-fw + 1)×1。
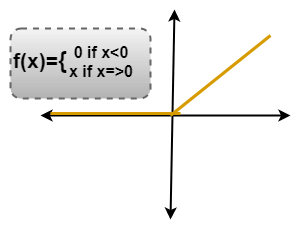
ReLU层
整流线性单位(ReLU)变换功能仅在输入大于一定数量时才激活节点。当数据低于零时, 输出为零, 但是当输入高于某个阈值时。它与因变量具有线性关系。
在这一层中, 我们从过滤后的图像中删除每个负值, 然后将它们替换为零。
正在避免将这些值相加为零。
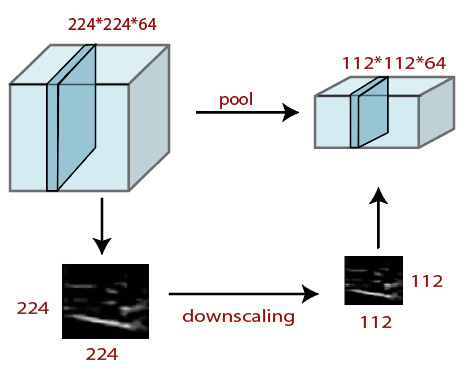
池化层
池化层在任何图像的预处理中都起着至关重要的作用。当图像太大时, 池化层会减少参数的数量。合并是从先前层获得的图像的”缩小比例”。可以比较缩小图像以降低图像的密度。空间池化也称为下采样和子采样, 它们降低了每个地图的维数, 但仍然是必不可少的信息。这些是以下类型的空间池。
为此, 我们执行以下4个步骤:
- 选择一个窗口大小(通常为2或3)
- 大步前进(通常2个)
- 在浏览的图像中浏览窗口
- 在每个窗口中取最大值
最大池
最大池化是基于样本的离散化过程。最大池化的主要目标是缩小输入表示的比例, 减小其尺寸并允许对合并的子区域中包含的特征进行假设。
通过在初始表示的非重叠子区域中应用max过滤器, 可以完成max pooling。
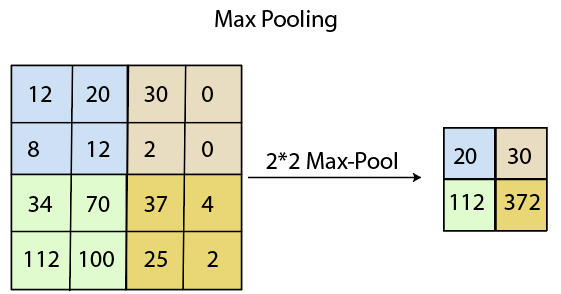
平均池化
缩小比例将通过将输入划分为矩形池区域并计算每个区域的平均值的平均池来执行。
句法
layer = averagePooling2dLayer(pool Size)
layer = averagePooling2dLayer(poolSize, Name, Value)汇总池
汇总池和均值池的子区域设置为与最大池化相同, 但不是使用max函数, 而是使用求和或均值。
在这一层中, 我们将图像堆栈缩小为较小的步长;
- 选择一个窗口大小(通常为2或3)
- 大步前进(通常2个)
- 在我们的窗口中浏览经过过滤的图像。
- 在每个窗口中取最大值。
执行窗口大小为2且跨度为2的合并。
完全连接(密集)层
全连接层(密集层)是一个层, 其中来自其他层的输入将被压入向量。它将输出转换为网络中任何所需数量的类。
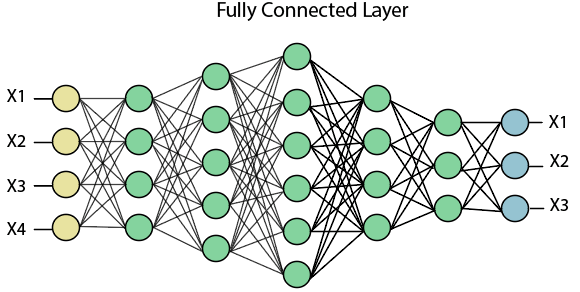
在上图中, 借助完全连接的图层, 将地图矩阵转换为向量, 例如x1, x2, x3 … xn。我们将结合功能来创建任何模型, 并应用激活功能(例如softmax或Sigmoid)将输出分类为汽车, 狗, 卡车等。
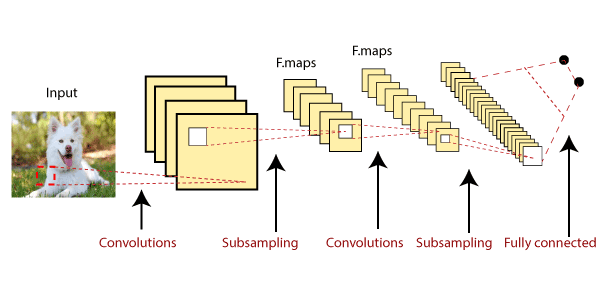
这是实际分类的最终结果。
评论前必须登录!
注册