 srcmini
srcminiKohonen自组织特征图(SOM)是指使用竞争性学习进行训练的神经网络。基本的竞争性学习意味着竞争过程发生在学习周期之前。竞争过程表明某些标准选择了获胜的处理要素。选择中奖处理元素后, 根据使用的学习定律调整其权重向量(Hecht Nielsen 1990)。
自组织映射在输入数据和映射的处理元素之间进行拓扑排序的映射。有序拓扑意味着, 如果两个输入具有相似的特征, 则最活跃的处理元素将对在地图上彼此靠近的输入进行响应。处理元素的权重向量按升序排列。 Wi <Wi + 1对于i的所有值或Wi + 1对于i的所有值(此定义仅对一维自组织映射有效)。
自组织图通常表示为下图所示的处理元素的二维表。每个处理元素都有其自己的权重向量, 对SOM(自组织图)的学习取决于这些向量的适应性。网络的处理元素在自组织过程中具有竞争力, 并且特定标准选择了权重已更新的获胜处理元素。通常, 这些标准用于限制输入向量和权重向量之间的欧几里得距离。 SOM(自组织图)与基础竞争学习有所不同, 因此, 不仅调整获胜处理元素的权重向量, 还调整邻近处理元素的权重向量。首先, 邻域的大小在很大程度上使SOM大致排序, 并且随着时间的流逝, 大小逐渐减小。最后, 仅调整获胜处理元素, 从而可以对SOM进行微调。邻域的使用使拓扑排序过程成为可能, 并且与竞争性学习一起使过程非线性。
它是由芬兰教授兼研究员Teuvo Kohonen博士于1982年发现的。自组织映射是指为在输入和输出空间之间保持拓扑结构的应用而提出的无监督学习模型。该算法的显着特征是, 在高维空间中接近且相似的输入向量也被映射为由2D空间中的节点闭合。从根本上讲, 它是一种降维方法, 因为它将高维输入映射到低维离散化表示, 并保留其输入空间的基本结构。
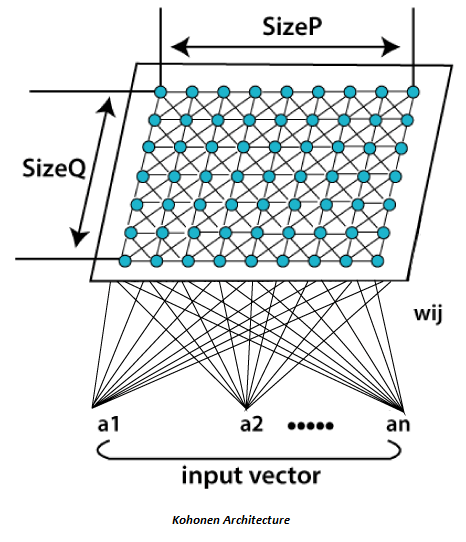
由于节点是自组织的, 因此整个学习过程都无需监督即可进行。它们也被称为特征图, 因为它们基本上是在重新训练输入数据的特征, 并且如彼此之间的相似性所指示的那样简单地对自身进行分组。它对于可视化复杂或大量的高维数据并将它们之间的关系显示在一个低二维字段中, 以检查给定的未标记数据是否具有任何结构具有实际价值。
自组织图(SOM)的体系结构和算法属性均不同于典型的人工神经网络(ANN)。它的结构由神经元的单层线性2D网格组成, 而不是由一系列层组成。此晶格上的所有节点都直接与输入向量关联, 但彼此不关联。这意味着节点不知道其邻居的值, 仅根据给定输入来更新其关联的权重。网格本身是根据输入数据在每次迭代中进行协调的地图。这样, 在聚类之后, 每个节点都有其自己的坐标(i.j), 这使一个节点能够根据毕达哥拉斯定理来计算两个节点之间的欧几里得距离。
自组织图利用竞争性学习而不是纠错学习来调整权重。这意味着在每个周期中只有一个单独的节点被激活, 在该周期中, 输入向量的出现特征被引入到神经网络中, 因为所有节点都在争夺对输入作出响应的特权。
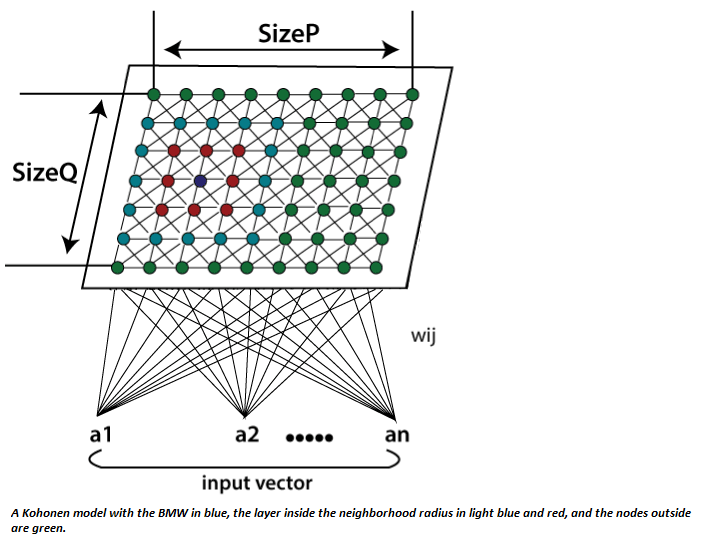
根据当前输入值与网络中所有其他节点之间的相似性, 选择选定的节点-最佳匹配单元(BMU)。选择输入向量, 所有节点及其相邻节点之间的分数欧几里得差的节点, 并在特定半径内进行选择, 以使其位置略微调整以协调输入向量。通过体验网格上存在的所有节点, 整个网格最终将整个输入数据集与朝向一个区域聚集的连接节点进行匹配, 并且将相异的节点隔离开。
算法
第1步
每个节点权重w_ij初始化为随机值。
第2步
选择一个随机输入向量x_k。
步骤:3
对地图上的所有节点重复步骤4和5。
步骤4
计算权重向量wij和与第一个节点相连的输入向量x(t)之间的欧几里得距离, 其中t, i, j = 0。
步骤:5
跟踪产生最小距离t的节点。
步骤:6
计算总体最佳匹配单位(BMU)。这意味着与所有计算节点的距离最小的节点。
步骤:7
在Kohonen地图中发现BMU的半径σ(t)的拓扑邻域βij(t)。
步骤:8
对BMU邻域中的所有节点重复上述操作:通过包括输入矢量x(t)与神经元权重w(t)之差的一小部分, 更新BMU邻域中第一个节点的权重向量w_ij。
步骤:9
重复完整的迭代, 直到达到所选的迭代极限t = n。
在这里, 步骤1代表初始化阶段, 而步骤2至9代表训练阶段。
哪里;
t =当前迭代。
i =节点网格的行坐标。
J =节点网格的列坐标。
W =权重向量
w_ij =网格中节点i, j之间的关联权重。
X =输入向量
X(t)=迭代t的输入向量实例
β_ij=邻域函数, 减小并表示距BMU的节点i, j的距离。
σ(t)=邻域函数的半径, 该函数计算更新矢量时在2D网格中检查相邻节点的距离。随着时间的流逝, 它逐渐减少。
评论前必须登录!
注册