 srcmini
srcmini本文概述
如果你想了解更多有关Python的信息, 请参加srcmini的免费的Python数据科学入门课程。
你们都看过数据集。有时它们很小, 但是有时它们的大小却非常大。处理非常大, 至少足以引起处理瓶颈的数据集变得非常具有挑战性。
那么, 是什么使这些数据集如此之大?好吧, 它的特征。特征数量越多, 数据集将越大。好吧, 并非总是如此。你会发现特征数量很多的数据集, 但是它们不包含那么多实例。但这不是这里讨论的重点。因此, 你可能想知道一台商用计算机如何在不打败灌木丛的情况下处理这些类型的数据集。
通常, 在高维数据集中, 仍然存在一些完全不相关, 无关紧要和不重要的特征。已经看到, 与关键特征相比, 这些类型的特征对预测建模的贡献通常较小。他们的贡献也可能为零。这些特征会导致许多问题, 进而导致无法进行有效的预测建模-
- 这些特征不必要的资源分配。
- 这些特征会产生噪音, 因此机器学习模型可能会表现极差。
- 机器模型需要花费更多时间进行培训。
那么, 这里的解决方案是什么?最经济的解决方案是特征选择。
特征选择是从给定数据集中选择最重要特征的过程。在许多情况下, 特征选择还可以增强机器学习模型的性能。
听起来很有趣吧?
你对特征选择及其在数据科学和机器学习领域的重要性进行了非正式介绍。在这篇文章中, 你将介绍:
- 介绍特征选择并了解其重要性
- 特征选择和降维之间的区别
- 不同类型的特征选择方法
- 使用scikit-learn实现不同的特征选择方法
特征选择简介
特征选择也称为变量选择或属性选择。
本质上, 这是选择最重要/最相关的过程。数据集的特征。
了解特征选择的重要性
在处理包含大量要素的数据集时, 可以最好地认识到要素选择的重要性。这种类型的数据集通常称为高维数据集。现在, 具有如此高的维数会带来很多问题, 例如-如此高的维数会大大增加你的机器学习模型的训练时间, 这会使你的模型非常复杂, 进而可能导致过度拟合。
通常在高维特征集中, 有几个特征是多余的, 这意味着这些特征仅是其他基本特征的扩展。这些冗余特征也无法有效地促进模型训练。因此, 很显然, 有必要为数据集提取最重要和最相关的特征, 以便获得最有效的预测建模性能。
“变量选择的目的是三方面的:提高预测变量的预测性能, 提供更快, 更具成本效益的预测变量, 以及更好地理解生成数据的基本过程。”
-变量和特征选择简介
现在, 让我们了解降维与特征选择之间的区别。
有时, 特征选择与降维有误。但是它们是不同的。特征选择与降维不同。两种方法都倾向于减少数据集中的属性数量, 但是降维方法是通过创建新的属性组合(有时称为特征变换)来实现的, 而特征选择方法包括并排除数据中存在的属性而不更改它们。
降维方法的一些示例包括主成分分析, 奇异值分解, 线性判别分析等。
让我总结一下特征选择对你的重要性:
- 它使机器学习算法的训练速度更快。
- 它降低了模型的复杂性, 并使其更易于解释。
- 如果选择正确的子集, 则可以提高模型的准确性。
- 它减少了过拟合。
在下一节中, 你将研究不同类型的常规要素选择方法-过滤器方法, 包装器方法和嵌入式方法。
过滤方式
下图最好地描述了基于过滤器的特征选择方法:

图片来源:Analytics Vidhya
过滤方法依赖于要评估的数据的一般唯一性并选择特征子集, 不包括任何挖掘算法。筛选方法使用精确的评估标准, 其中包括距离, 信息, 依赖性和一致性。筛选方法使用排名技术的主要标准, 并使用排名方法进行变量选择。使用排名方法的原因是简单, 产生出色且相关的特征。排序方法将在分类过程开始之前滤除不相关的特征。
过滤方法通常用作数据预处理步骤。特征的选择与任何机器学习算法无关。特征根据统计得分进行排名, 这些得分往往会确定特征与结果变量的相关性。关联是一个高度上下文相关的术语, 并且因工作而异。你可以参考下表为不同类型的数据(在这种情况下为连续的和分类的)定义相关系数。

图片来源:Analytics Vidhya
一些滤波方法的一些示例包括卡方检验, 信息增益和相关系数得分。
接下来, 你将看到包装器方法。
包装方法
像过滤器方法一样, 让我给你同样的信息图, 这将帮助你更好地了解包装器方法:
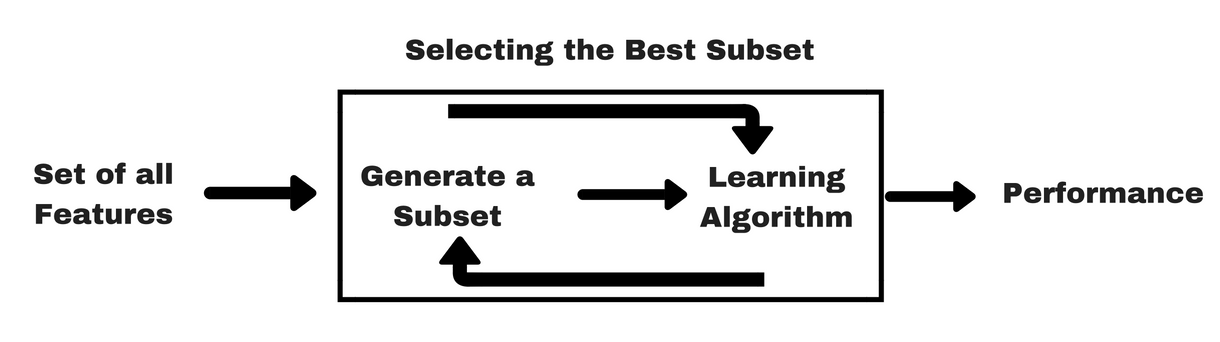
图片来源:Analytics Vidhya
如上图所示, 包装器方法需要一种机器学习算法, 并将其性能用作评估标准。该方法搜索最适合机器学习算法的特征, 旨在提高挖掘性能。为了评估特征, 使用聚类评估用于分类任务的预测准确性和聚类的优劣。
包装方法的一些典型示例是前向特征选择, 后向特征消除, 递归特征消除等。
- 正向选择:该过程从一组空的特征[精简集]开始。确定最佳原始特征并将其添加到精简集中。在每个后续迭代中, 将剩余的最佳原始属性添加到集合中。
- 向后消除:该过程从整套属性开始。在每个步骤中, 它都会删除集合中剩余的最差属性。
- 前向选择和后向消除的组合:可以将逐步前向选择和后向消除方法进行组合, 以便在每个步骤中, 该过程选择最佳属性, 并从其余属性中消除最差的属性。
- 递归特征消除:递归特征消除执行贪婪搜索以找到性能最佳的子集。它迭代创建模型, 并在每次迭代时确定性能最佳或最差的特征。它使用左侧的特征构造后续模型, 直到探索所有特征为止。然后, 根据特征消除的顺序对特征进行排序。在最坏的情况下, 如果数据集包含N个特征, 则RFE会对2N个特征组合进行贪婪搜索。
够好了!
现在让我们研究嵌入式方法。
嵌入式方法
从某种意义上说, 嵌入式方法是迭代的, 需要注意模型训练过程的每个迭代, 并仔细提取对特定迭代的训练贡献最大的那些特征。正则化方法是最常用的嵌入式方法, 在给定系数阈值的情况下会对特征进行惩罚。
这就是正则化方法也称为惩罚方法的原因, 该方法会在预测算法(例如回归算法)的优化中引入其他约束, 从而使模型偏向更低的复杂度(系数越少)。
正则化算法的示例包括LASSO, Elastic Net, Ridge Regression等。
过滤器和包装器方法之间的区别
好吧, 有时根据特征性来区分过滤器方法和包装器方法可能会造成混淆。让我们看看它们之间有什么不同。
- 过滤器方法没有合并机器学习模型来确定某项特征的优缺点, 而包装器方法使用机器学习模型并对其进行训练以决定该特征是否必要。
- 与包装方法相比, 筛选方法要快得多, 因为它们不涉及训练模型。另一方面, 包装方法在计算上是昂贵的, 并且在海量数据集的情况下, 包装方法并不是要考虑的最有效的特征选择方法。
- 在没有足够的数据来建模特征的统计相关性的情况下, 过滤器方法可能无法找到特征的最佳子集, 但是包装器方法由于其详尽的性质始终可以提供特征的最佳子集。
- 在最终的机器学习模型中使用包装方法的特征可能会导致过度拟合, 因为包装方法已经使用这些特征训练了机器学习模型, 并且影响了学习的真正力量。但是在大多数情况下, 滤波方法的特征不会导致过拟合
到目前为止, 你已经研究了特征选择的重要性, 了解其与降维的区别。你还介绍了各种类型的特征选择方法。到现在为止还挺好!
现在, 让我们看看执行特征选择时可能会遇到的一些陷阱:
重要考虑
你可能已经了解了机器学习管道中特征选择的价值及其集成后提供的服务类型。但是, 重要的是要准确了解在机器学习管道中应该将特征选择集成到何处。
简而言之, 在将数据输入模型进行训练之前, 应该包括特征选择步骤, 尤其是在使用诸如交叉验证之类的精度估计方法时。这样可以确保在训练模型之前就对数据折页执行特征选择。但是, 如果你先执行特征选择以准备数据, 然后对所选特征执行模型选择和训练, 那将是一个大错误。
如果你对所有数据执行特征选择然后进行交叉验证, 那么交叉验证过程的每一折中的测试数据也将用于选择特征, 这往往会影响机器学习模型的性能。
理论足够多!现在让我们直接进行一些编码。
Python案例研究
对于此案例研究, 你将使用Pima Indians Diabetes数据集。数据集的描述可以在这里找到。
该数据集对应于分类任务, 你需要根据这些任务基于8个特征来预测一个人是否患有糖尿病。
数据集中共有768个观测值。你的首要任务是加载数据集, 以便继续进行。但是在此之前, 我们需要导入必要的依赖项。你可以随时导入其他文件。
import pandas as pd
import numpy as np
现在已经导入了依赖项, 让我们借助Pandas库将Pima Indians数据集加载到Dataframe对象中。
data = pd.read_csv("diabetes.csv")
数据集已成功加载到Dataframe对象数据中。现在, 让我们看一下数据。
data.head()
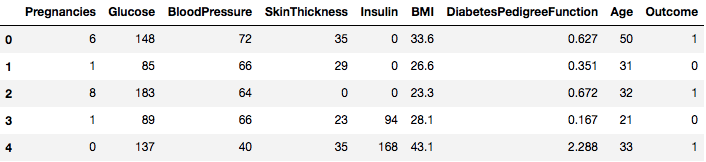
因此, 你可以看到标记为1和0的结果中有8种不同的特征, 其中1代表观察结果患有糖尿病, 0代表观察结果没有糖尿病。已知数据集缺少值。具体而言, 对于某些标记为零值的列, 缺少观测值。你可以通过这些列的定义来推断出这一点, 并且使零值对于那些度量无效是不切实际的, 例如, 对于体重指数为零或血压无效。
但是对于本教程, 你将直接使用数据集的预处理版本。
# load data
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
dataframe = pd.read_csv(url, names=names)
你现在已将数据加载到名为dataframe的DataFrame对象中。
让我们将DataFrame对象转换为NumPy数组以实现更快的计算。另外, 让我们将数据分成单独的变量, 以便要素和标签分开。
array = dataframe.values
X = array[:, 0:8]
Y = array[:, 8]
精彩!你已经准备好数据。
首先, 你将对非负特征实施Chi-Squared统计检验, 以从数据集中选择4个最佳特征。你已经看到Chi-Squared测试属于过滤器方法类。如果有人对了解Chi-Squared的内部知识感到好奇, 那么此视频可以做得很好。
scikit-learn库提供SelectKBest类, 该类可与一组不同的统计测试一起使用, 以选择特定数量的特征, 在本例中为Chi-Squared。
# Import the necessary libraries first
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
你导入了库以运行实验。现在, 让我们来看一下它的作用。
# Feature extraction
test = SelectKBest(score_func=chi2, k=4)
fit = test.fit(X, Y)
# Summarize scores
np.set_printoptions(precision=3)
print(fit.scores_)
features = fit.transform(X)
# Summarize selected features
print(features[0:5, :])
[ 111.52 1411.887 17.605 53.108 2175.565 127.669 5.393 181.304]
[[148. 0. 33.6 50. ]
[ 85. 0. 26.6 31. ]
[183. 0. 23.3 32. ]
[ 89. 94. 28.1 21. ]
[137. 168. 43.1 33. ]]
解释:
你可以看到每个属性的得分以及所选的4个属性(得分最高的属性):塑化, 测试, 质量和年龄。该分数将帮助你进一步确定用于训练模型的最佳特征。
附注:第一行表示要素名称。为了对数据集进行预处理, 对名称进行了数字编码。
接下来, 你将实现递归特征消除, 这是一种包装特征选择方法。
递归特征消除(RFE)的工作方式是递归删除属性, 并根据剩余的属性建立模型。
它使用模型准确性来确定哪些属性(和属性组合)对预测目标属性的贡献最大。
你可以在scikit-learn文档中了解有关RFE类的更多信息。
# Import your necessary dependencies
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
你将结合使用RFE和Logistic回归分类器来选择前3个特征。只要技术熟练且一致, 算法的选择就没有太大关系。
# Feature extraction
model = LogisticRegression()
rfe = RFE(model, 3)
fit = rfe.fit(X, Y)
print("Num Features: %s" % (fit.n_features_))
print("Selected Features: %s" % (fit.support_))
print("Feature Ranking: %s" % (fit.ranking_))
Num Features: 3
Selected Features: [ True False False False False True True False]
Feature Ranking: [1 2 3 5 6 1 1 4]
你可以看到, RFE选择了前三项特征, 例如预浸料, 质量和脚蹬。
这些在支持数组中标记为True, 在排名数组中标记为选项” 1″。这反过来表明了这些特征的优势。
下一步, 你将使用Ridge回归, 它基本上是一种正则化技术, 也是一种嵌入式特征选择技术。
本文为你提供了有关Ridge回归的绝佳解释。请务必检查一下。
# First things first
from sklearn.linear_model import Ridge
接下来, 你将使用Ridge回归来确定系数R2。
另外, 请查看scikit-learn的Ridge回归官方文档。
ridge = Ridge(alpha=1.0)
ridge.fit(X, Y)
Ridge(alpha=1.0, copy_X=True, fit_intercept=True, max_iter=None, normalize=False, random_state=None, solver='auto', tol=0.001)
为了更好地了解Ridge回归的结果, 你将实现一个辅助函数, 该函数将帮助你更好地打印结果, 以便于你轻松地解释它们。
# A helper method for pretty-printing the coefficients
def pretty_print_coefs(coefs, names = None, sort = False):
if names == None:
names = ["X%s" % x for x in range(len(coefs))]
lst = zip(coefs, names)
if sort:
lst = sorted(lst, key = lambda x:-np.abs(x[0]))
return " + ".join("%s * %s" % (round(coef, 3), name)
for coef, name in lst)
接下来, 你将把Ridge模型的系数项传递给这个小函数, 看看会发生什么。
print ("Ridge model:", pretty_print_coefs(ridge.coef_))
Ridge model: 0.021 * X0 + 0.006 * X1 + -0.002 * X2 + 0.0 * X3 + -0.0 * X4 + 0.013 * X5 + 0.145 * X6 + 0.003 * X7
你可以发现所有附加在特征变量后的系数项。它将再次帮助你选择最基本的特征。在应用Ridge回归时, 请牢记以下几点:
- 也称为L2正则化。
- 对于相关特征, 这意味着它们倾向于获得相似的系数。
- 具有负系数的特征贡献不大。但是, 在你要处理许多特征的更为复杂的情况下, 此分数肯定会帮助你完成最终的特征选择决策过程。
好了, 案例研究部分到此结束。上一节中实现的方法将帮助你全面了解特定数据集的特征。让我给你介绍这些技术的一些关键点:
- 特征选择本质上是数据预处理的一部分, 这被认为是任何机器学习管道中最耗时的部分。
- 这些技术将帮助你以更系统的方式和机器学习友好的方式进行处理。你将能够更准确地解释特征。
总结!
在本文中, 你介绍了研究最深入和研究最深入的统计主题之一, 即特征选择。你还熟悉了它的不同变体, 并使用它们来查看数据集中哪些要素很重要。
你可以通过将相关度量合并到wrapper方法中来进一步了解本教程, 并查看其性能。在操作过程中, 你可能最终会创建自己的特征选择机制。这样便可以为你的小型研究奠定基础。研究人员还使用各种软计算原理来执行选择。这本身就是整个研究领域。另外, 你应该在各种数据集上尝试现有的特征选择算法, 并得出自己的推论。
为什么这些传统特征选择方法仍然有效?
是的, 这个问题很明显。因为存在神经网络体系结构(例如CNN), 它们能够从数据中提取最重要的特征, 但这也有局限性。对于没有特定属性(常规图像所具有的属性, 例如过渡属性, 边缘, 位置属性, 轮廓等)的常规表格数据集, 使用CNN并不是最明智的决定。此外, 当你的数据和资源有限时, 在常规表格数据集上训练CNN可能会完全浪费。因此, 在这种情况下, 你研究的方法肯定会派上用场。
如果你想进一步了解此主题, 请参考以下资源:
- 知识发现和数据挖掘的特征选择
- 子空间, 潜在结构和特征选择:”统计和优化观点”研讨会
- 特征选择:问题陈述和用途
- 在数据分析中使用遗传算法进行特征选择
以下是用于编写本教程的参考。
- Data Mining: Concepts and Techniques; Jiawei Han Micheline Kamber Jian Pei.
- 特征选择简介
- 有关特征选择的Analytics Vidhya文章
- 分层和混合模型-srcmini课程
- Python中机器学习的特征选择
- 通过机器学习和特征选择方法检测流数据中的异常值
- S. Visalakshi和V. Radha, “特征选择技术和应用的文献综述:数据挖掘中的特征选择综述”, 2014 IEEE国际计算智能与计算研究会议, 哥印拜陀, 2014年, 第1-6页。
如果有任何疑问, 请务必在评论部分中发表你的疑问!
评论前必须登录!
注册