 srcmini
srcmini本文概述
- 集合与列表和元组
- Python集的优点
- 初始化集合
- 从集中添加和删除值
- 从集合中删除值
- 从集合中删除所有值
- 遍历一组
- 将集转换为有序值
- 从列表中删除重复项
- 设定操作方法
- 区别
- 对称差异
- 设定理解
- 会员资格测试
- 子集
- 冰雪奇缘
集合与列表和元组
列表和元组是标准Python数据类型, 可按顺序存储值。集合是另一种标准Python数据类型, 它也存储值。主要区别在于, 与列表或元组不同, 集合不能具有相同元素的多次出现并存储无序值。
Python集的优点
由于集合不能具有相同元素的多次出现, 因此使集合非常有用, 可以有效地从列表或元组中删除重复的值, 并执行诸如联合和相交之类的常见数学运算。
如果你想提高你的Python技能, 或者你只是初学者, 请务必查看我们在srcmini上的Python程序员职业生涯。
本教程将向你介绍有关Python集和集理论的一些主题:
如何初始化空集和带有值的集。
如何从集合中添加和删除值
如何有效使用使用集来执行诸如成员资格测试之类的任务, 以及如何从列表中删除重复的值。
如何执行常见的集合运算, 例如并集, 交集, 差和对称差。
集合和冻结集合之间的区别
这样, 让我们开始吧。
初始化集合
集是可变的, 无序的(唯一)不可变值的可变集合。
你可以使用set()初始化一个空集。
emptySet = set()
要使用值初始化集合, 可以将列表传递给set()。
dataScientist = set(['Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS'])
dataEngineer = set(['Python', 'Java', 'Scala', 'Git', 'SQL', 'Hadoop'])

如果查看上面的dataScientist和dataEngineer变量的输出, 请注意, 集合中的值未按添加顺序排列。这是因为集合是无序的。
包含值的集也可以使用花括号来初始化。
dataScientist = {'Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS'}
dataEngineer = {'Python', 'Java', 'Scala', 'Git', 'SQL', 'Hadoop'}

请记住, 花括号只能用于初始化包含值的集合。下图显示使用不带值的花括号是初始化字典而不是集合的一种方法。
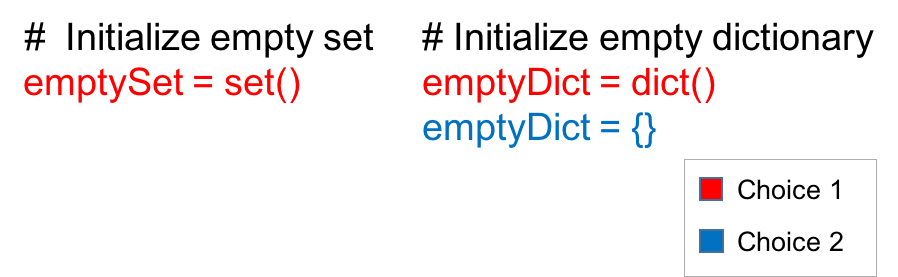
从集中添加和删除值
要在集合中添加或删除值, 首先必须初始化一个集合。
# Initialize set with values
graphicDesigner = {'InDesign', 'Photoshop', 'Acrobat', 'Premiere', 'Bridge'}
将值添加到集合
你可以使用add方法将值添加到集合中。
graphicDesigner.add('Illustrator')

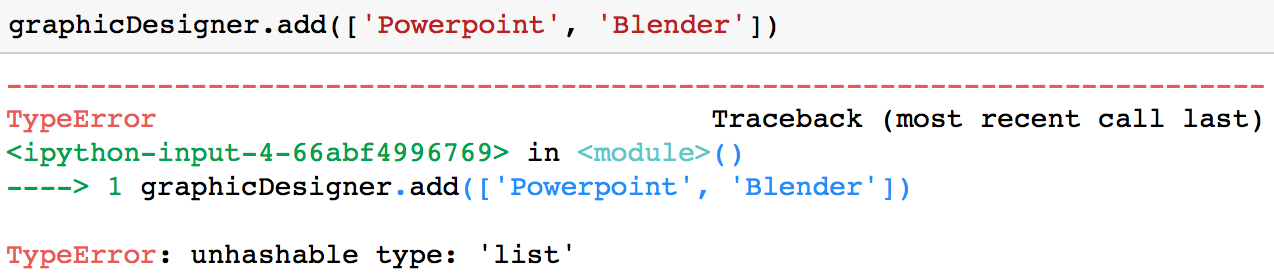
请务必注意, 你只能将不可变的值(例如字符串或元组)添加到集合中。例如, 如果你尝试将列表添加到集合中, 则会出现TypeError。
graphicDesigner.add(['Powerpoint', 'Blender'])
从集合中删除值
有几种从集合中删除值的方法。
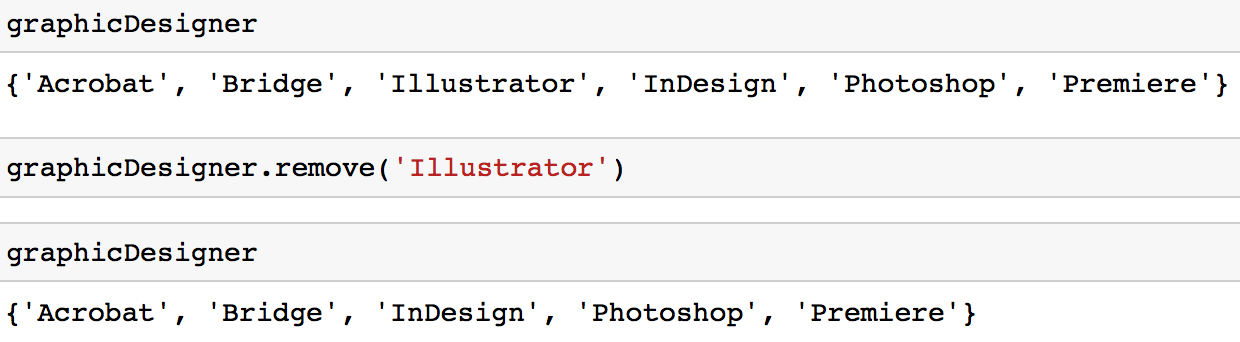
选项1:你可以使用remove方法从集合中删除一个值。
graphicDesigner.remove('Illustrator')
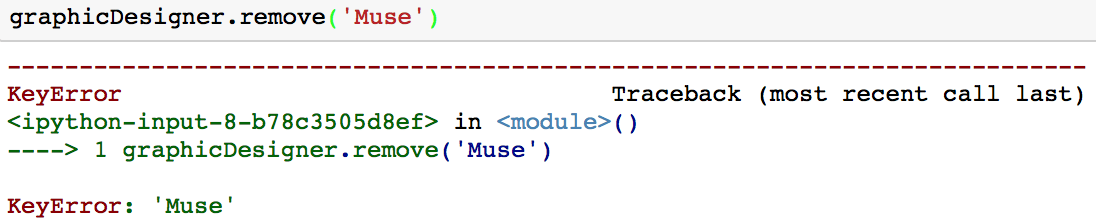
此方法的缺点是, 如果你尝试删除不在集合中的值, 则会收到KeyError。
选项2:你可以使用丢弃方法从集合中删除一个值。
graphicDesigner.discard('Premiere')

这种方法相对于remove方法的好处是, 如果你尝试删除不属于集合的值, 则不会收到KeyError。如果你熟悉字典, 则可能会发现它的工作方式与字典方法get相似。
选项3:你还可以使用pop方法从集合中删除并返回任意值。
graphicDesigner.pop()

重要的是要注意, 如果集合为空, 则该方法将引发KeyError。
从集合中删除所有值
你可以使用clear方法从集合中删除所有值。
graphicDesigner.clear()

遍历一组
像许多标准python数据类型一样, 可以遍历集合。
# Initialize a set
dataScientist = {'Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS'}
for skill in dataScientist:
print(skill)

如果查看在dataScientist中打印每个值的输出, 请注意, 打印在集合中的值与添加顺序不符。这是因为集合是无序的。
将集转换为有序值
本教程强调了集合是无序的。如果发现需要以有序形式从集合中获取值, 则可以使用有序输出列表的有序函数。
type(sorted(dataScientist))

下面的代码以字母降序输出设置的dataScientist中的值(在这种情况下为Z-A)。
sorted(dataScientist, reverse = True)

从列表中删除重复项
本节中的部分内容先前在教程18最常见的Python列表问题中进行了探讨, 但必须强调的是, 集合是从列表中删除重复项的最快方法。为了说明这一点, 让我们研究两种方法之间的性能差异。
方法1:使用集合从列表中删除重复项。
print(list(set([1, 2, 3, 1, 7])))
方法2:使用列表推导从列表中删除重复项(如果你想对列表推导进行复习, 请参阅本教程)。
def remove_duplicates(original):
unique = []
[unique.append(n) for n in original if n not in unique]
return(unique)
print(remove_duplicates([1, 2, 3, 1, 7]))
可以使用timeit库来衡量性能差异, 该库允许你对Python代码进行计时。下面的代码将每种方法的代码运行10000次, 并输出所需的总时间(以秒为单位)。
import timeit
# Approach 1: Execution time
print(timeit.timeit('list(set([1, 2, 3, 1, 7]))', number=10000))
# Approach 2: Execution time
print(timeit.timeit('remove_duplicates([1, 2, 3, 1, 7])', globals=globals(), number=10000))

比较这两种方法可以看出, 使用集合删除重复项更为有效。尽管看起来时间上的差别很小, 但是如果列表很大, 则可以节省很多时间。
设定操作方法
在Python中, 集合的常见用法是计算标准数学运算, 例如并集, 交集, 差和对称差。下图显示了两组A和B上的几个标准数学运算。每个Venn图的红色部分是给定set运算的结果集。
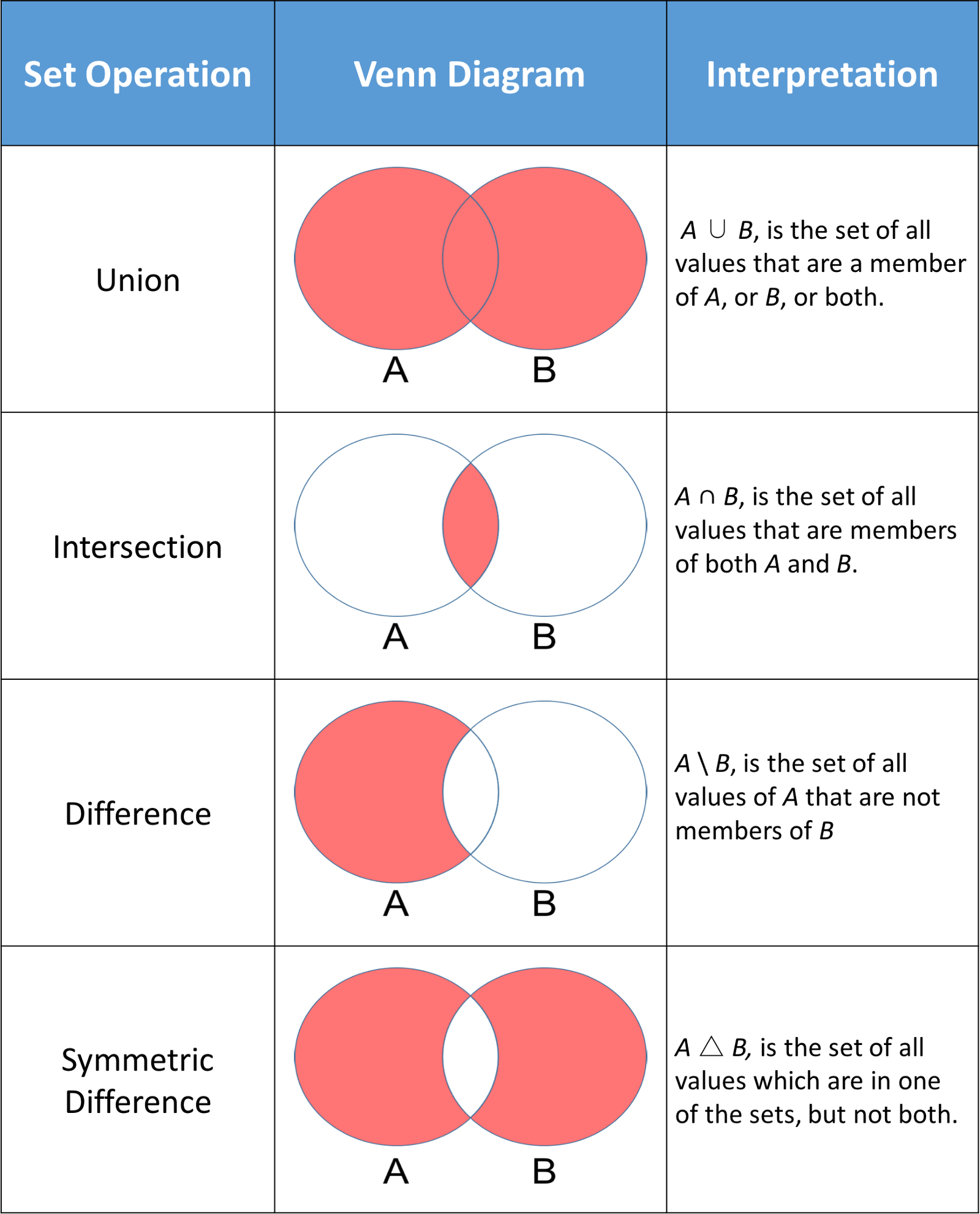
Python集具有允许你执行这些数学运算的方法以及为你提供等效结果的运算符。
在探索这些方法之前, 我们先初始化两个数据集dataScientist和dataEngineer。
dataScientist = set(['Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS'])
dataEngineer = set(['Python', 'Java', 'Scala', 'Git', 'SQL', 'Hadoop'])
联盟
表示为dataScientist∪dataEngineer的并集是由dataScientist或dataEngineer或两者组成的所有值的集合。你可以使用并集方法找出两组中的所有唯一值。
# set built-in function union
dataScientist.union(dataEngineer)
# Equivalent Result
dataScientist | dataEngineer

从并集返回的集合可以显示为下面的维恩图的红色部分。

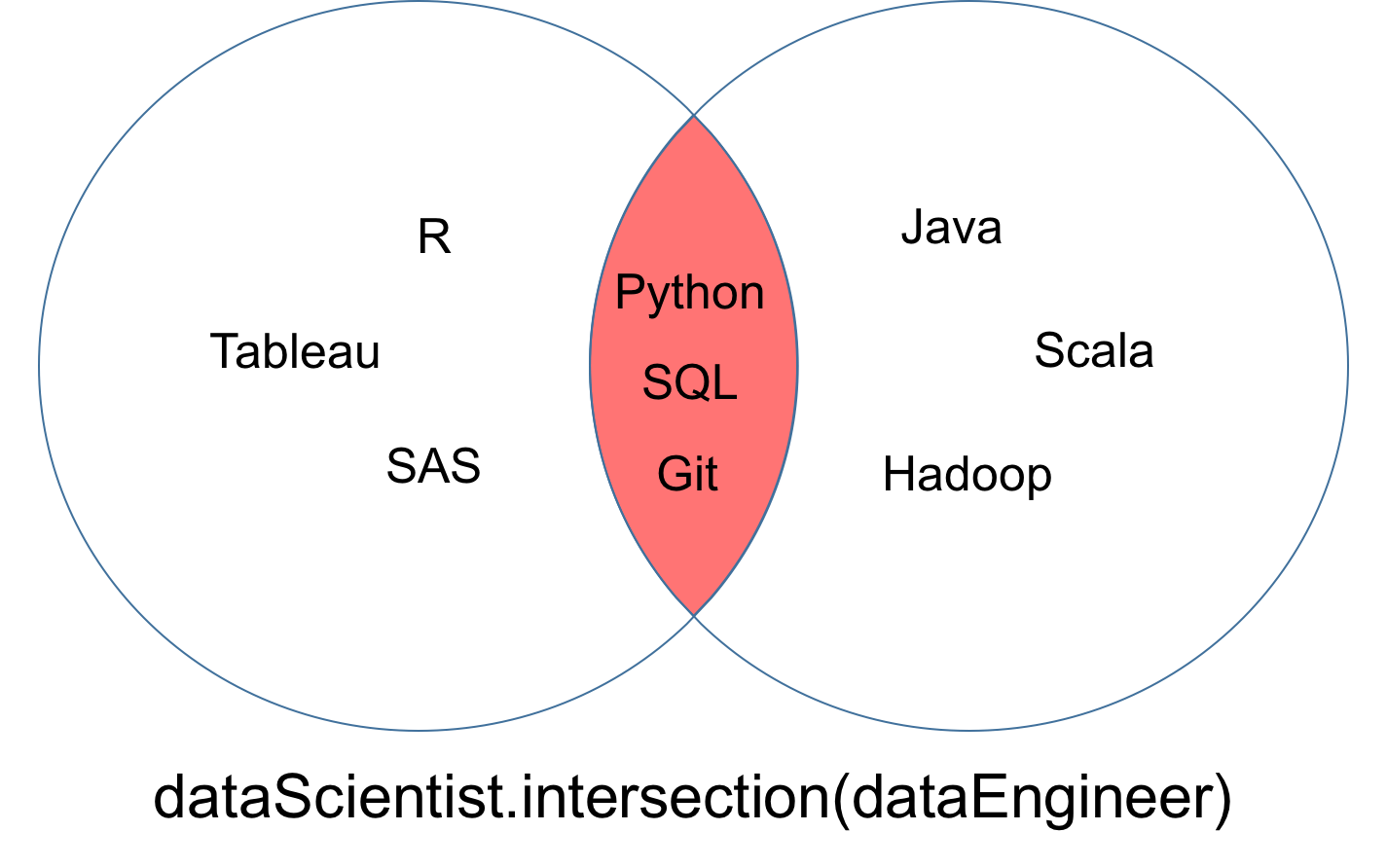
路口
表示dataScientist∩dataEngineer的两个集合dataScientist和dataEngineer的交集是所有值的集合, 这些值都是dataScientist和dataEngineer的值。
# Intersection operation
dataScientist.intersection(dataEngineer)
# Equivalent Result
dataScientist & dataEngineer

从相交处返回的集合可以可视化为以下维恩图的红色部分。
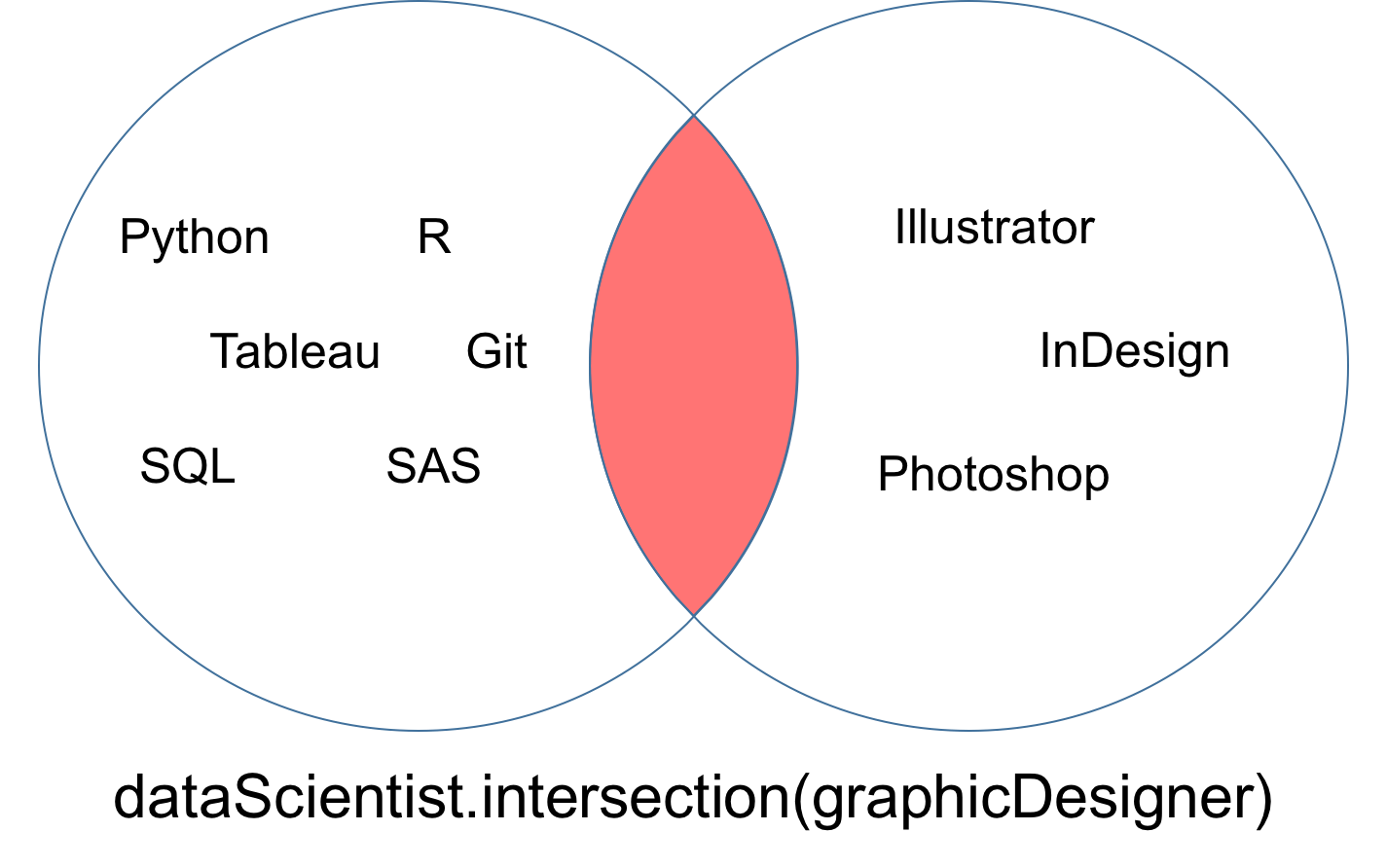
你可能会发现遇到一种情况, 就是要确保两组没有共同的价值。换句话说, 你需要两个交集为空的集合。这两个集合称为不交集。你可以使用isdisjoint方法测试不交集。
# Initialize a set
graphicDesigner = {'Illustrator', 'InDesign', 'Photoshop'}
# These sets have elements in common so it would return False
dataScientist.isdisjoint(dataEngineer)
# These sets have no elements in common so it would return True
dataScientist.isdisjoint(graphicDesigner)

你可以在下面的维恩(Venn)图所示的相交处注意到, 不相交集dataScientist和graphicDesigner没有共同的值。
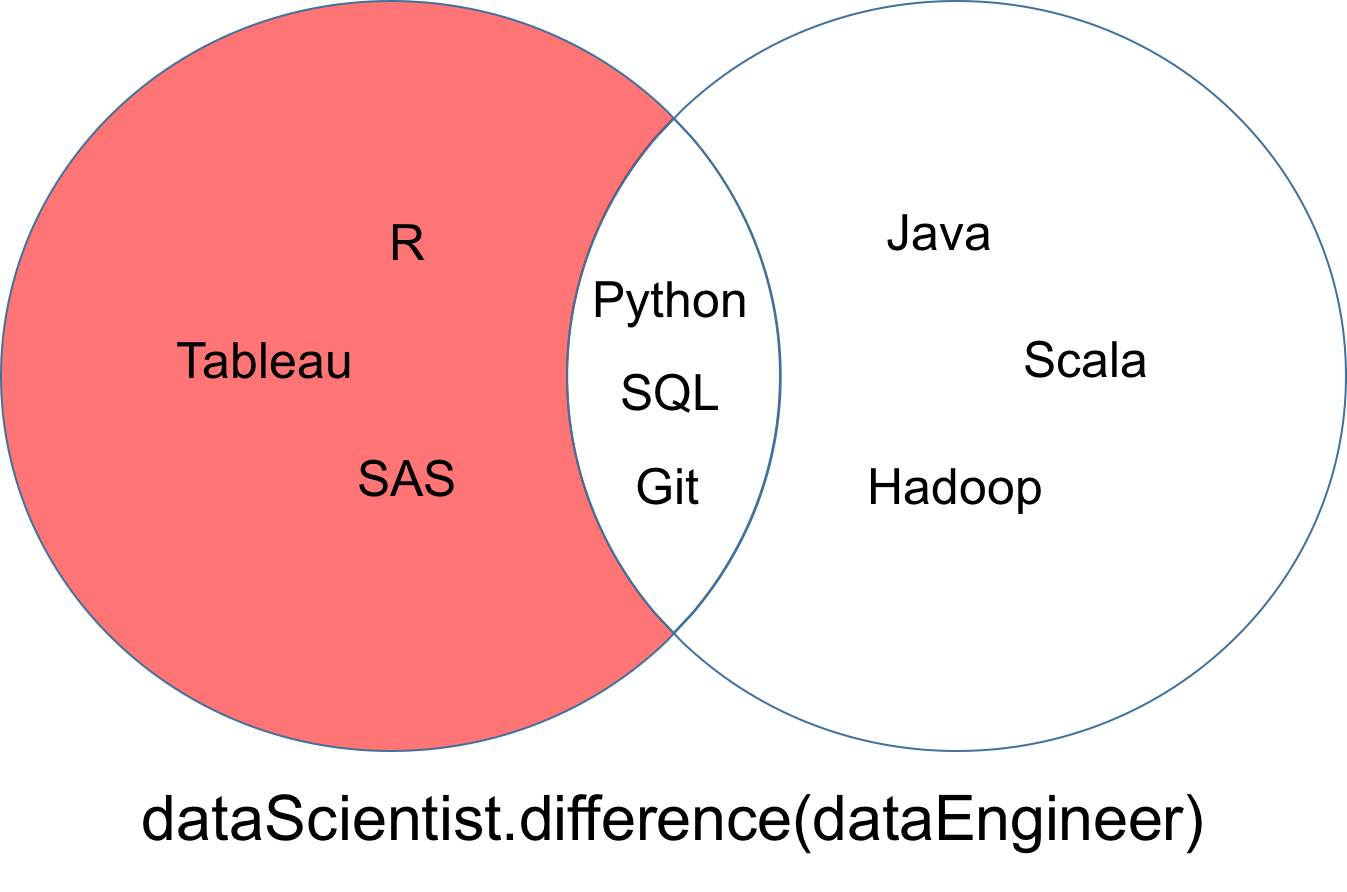
区别
表示dataScientist \ dataEngineer的两组dataScientist和dataEngineer之差是dataScientist的所有值的集合, 这些值不是dataEngineer的值。
# Difference Operation
dataScientist.difference(dataEngineer)
# Equivalent Result
dataScientist - dataEngineer

从差异返回的集合可以显示为下面的维恩图的红色部分。
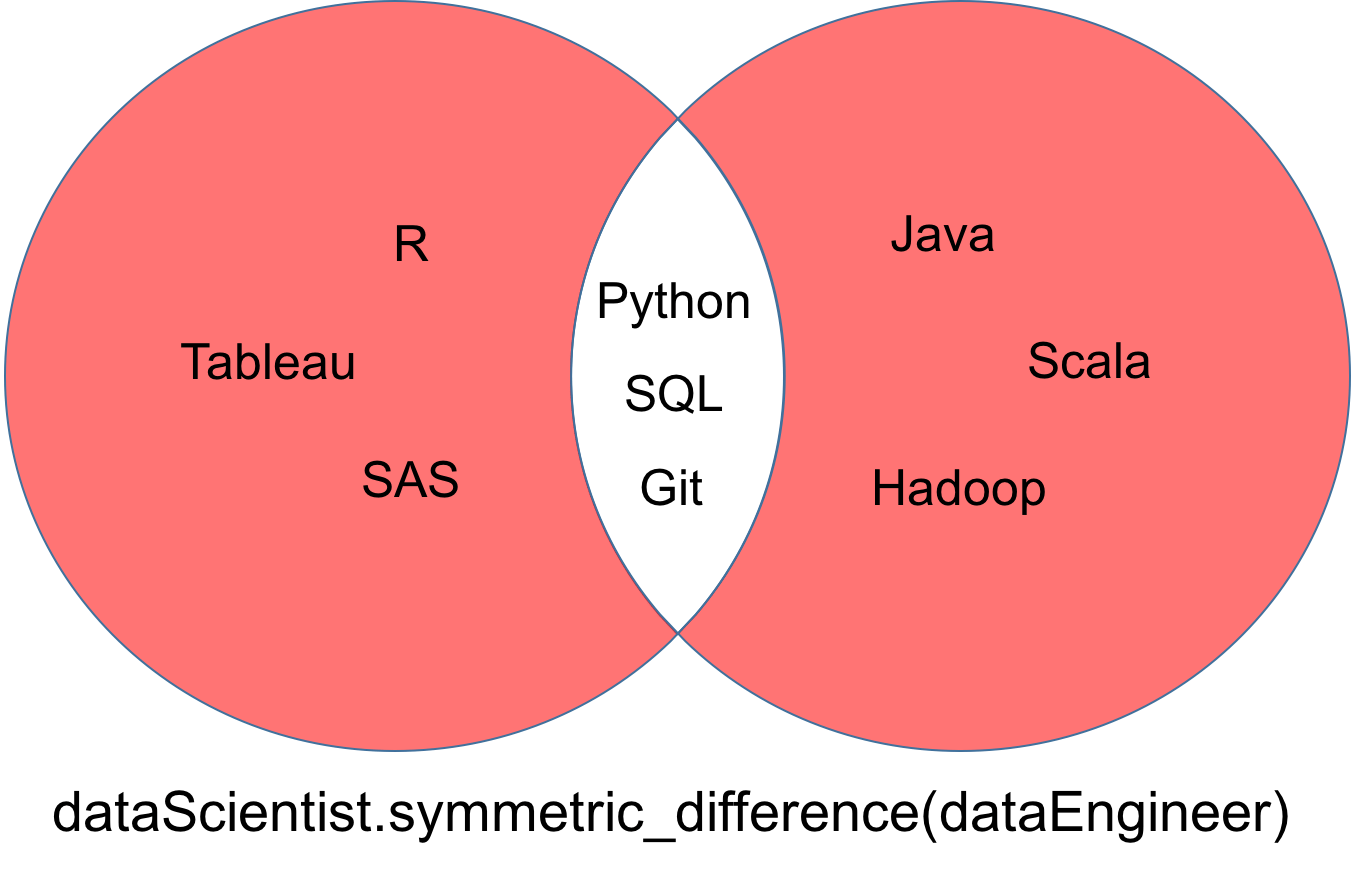
对称差异
两组数据的对称差dataScientist和dataEngineer表示为dataScientist△dataEngineer, 是所有值的集合, 这些值恰好是两组的其中一组, 但不是两组。
# Symmetric Difference Operation
dataScientist.symmetric_difference(dataEngineer)
# Equivalent Result
dataScientist ^ dataEngineer

从对称差异返回的集合可以显示为下面的维恩图的红色部分。
设定理解
你可能以前已经了解了列表理解, 字典理解和生成器理解。还有设定的理解力。集合理解非常相似。 Python中的集合理解可以构造如下:
{skill for skill in ['SQL', 'SQL', 'PYTHON', 'PYTHON']}

上面的输出是2个值的集合, 因为集合不能多次出现同一元素。
使用集合理解的思想是让你以与手工数学相同的方式编写代码并进行推理。
{skill for skill in ['GIT', 'PYTHON', 'SQL'] if skill not in {'GIT', 'PYTHON', 'JAVA'}}

上面的代码类似于你先前了解的设置差异。看起来有点不同。
会员资格测试
成员资格测试检查序列中是否包含特定元素, 例如字符串, 列表, 元组或集合。在Python中使用集的主要优点之一是它们针对成员资格测试进行了高度优化。例如, 集合进行成员资格测试比列表有效得多。如果你来自计算机科学背景, 这是因为列表中成员资格测试的平均案例时间复杂度为O(1)vs O(n)。
下面的代码使用列表显示成员资格测试。
# Initialize a list
possibleList = ['Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS', 'Java', 'Spark', 'Scala']
# Membership test
'Python' in possibleList

可以对集合进行类似的操作。集合恰好更有效。
# Initialize a set
possibleSet = {'Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS', 'Java', 'Spark', 'Scala'}
# Membership test
'Python' in possibleSet

由于possibleSet是一个集合, 值” Python”是possibleSet的值, 因此可以将其表示为” Python”∈possibleSet。
如果你有一个不属于集合的值, 例如” Fortran”, 则将其表示为” Fortran”-可能集。
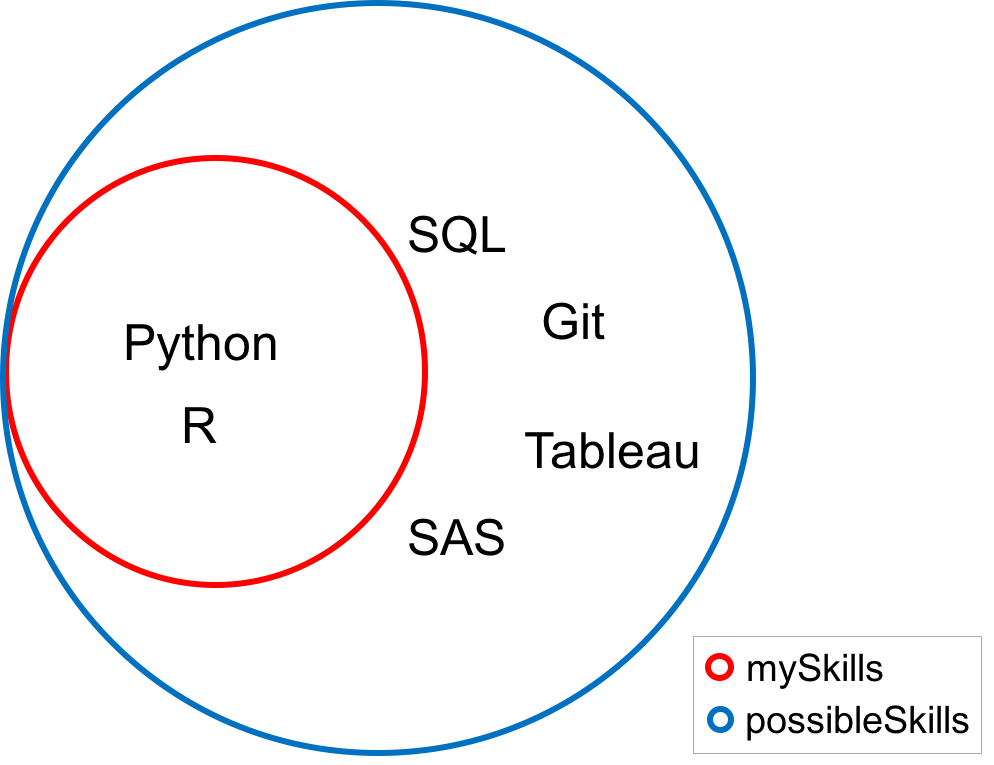
子集
理解成员资格的实际应用是子集。
让我们首先初始化两个集合。
possibleSkills = {'Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS'}
mySkills = {'Python', 'R'}
如果集合mySkills的每个值也都是集合可能的技能的值, 则将mySkills称为可能的技能的子集, 用数学方法写成mySkills可能的技能。
你可以使用issubset方法检查一组是否为另一组的子集。
mySkills.issubset(possibleSkills)

由于在这种情况下该方法返回True, 因此它是一个子集。在下面的维恩图中, 请注意, 设置mySkills的每个值也都是设置可能的技能的值。
冰雪奇缘
你已经遇到了嵌套列表和元组。
# Nested Lists and Tuples
nestedLists = [['the', 12], ['to', 11], ['of', 9], ['and', 7], ['that', 6]]
nestedTuples = (('the', 12), ('to', 11), ('of', 9), ('and', 7), ('that', 6))

嵌套集的问题在于你通常不能拥有嵌套集, 因为集不能包含包括集在内的可变值。
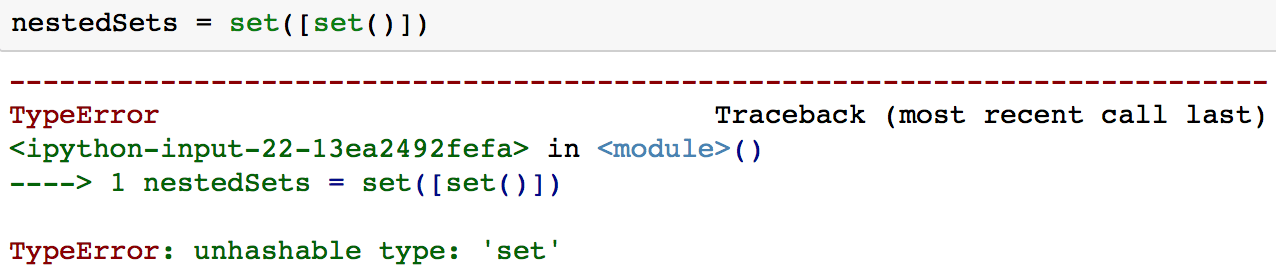
在这种情况下, 你可能希望使用冻结集。冻结集与集合非常相似, 只不过冻结集是不可变的。
你可以通过使用Frozenset()来创建一个Frozenset。
# Initialize a frozenset
immutableSet = frozenset()

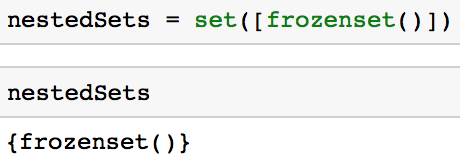
如果你使用类似于以下代码的frozenset, 则可以创建嵌套集。
nestedSets = set([frozenset()])
重要的是要记住, frozenset的主要缺点在于, 由于它们是不可变的, 因此, 你无法添加或删除值。
Python集非常有用, 可以有效地从列表等集合中删除重复值, 并执行诸如联合和相交之类的常用数学运算。人们经常遇到的一些挑战是何时使用各种数据类型。例如, 如果你不确定使用字典对集合的优势, 那么我建议你查看srcmini的日常练习模式。如果你对本教程有任何疑问或想法, 请随时通过以下评论或通过Twitter与我们联系。
评论前必须登录!
注册