 srcmini
srcmini本文概述
现实世界的数据几乎总是乱七八糟。作为数据科学家, 数据分析师乃至开发人员, 如果你需要发现有关数据的事实, 至关重要的是要确保数据足够整齐地做到这一点。实际上, 整理数据的定义非常全面, 你可以查看此Wiki页面以找到有关它的更多资源。
在本教程中, 你将练习一些SQL中最常见的数据清除技术。你将创建自己的虚拟数据集, 但是这些技术也可以应用于(表格形式的)真实数据。本教程的内容如下:
- 不同的数据类型及其混乱的值
- 数字混乱可能引发的问题
- 清洗数值
- 凌乱的弦
- 清洗字符串值
- 凌乱的日期值并清除它们
- 重复并删除它们
很多事情要覆盖。让我们开始!
请注意, 你应该已经知道如何在PostgreSQL(本教程中将使用的RDBMS)中编写SQL查询的基础知识。如果你需要修改概念, 那么以下可能是一些有用的资源:
- srcmini的SQL数据科学入门课程
- PostgreSQL初学者指南
不同的数据类型, 它们的混乱值和补救措施。
在表格形式的数据中, 最常见的数据类型是字符串, 数字或日期时间。你可能会遇到所有这些类型的混乱值。现在, 让我们采用这些类型中的每一个, 并查看它们各自混乱值的一些示例。让我们从数字类型开始。
乱数
数字可以通过多种方式以凌乱的形式出现。在这里, 将向你介绍最常见的方法:
- 意外的类型/类型不匹配:请考虑你正在使用的数据集中有一个名为age的列。你会看到该列中存在的值是浮点型的-样本值类似23.0、45.0、34.0等。在这种情况下, 你不需要年龄列为浮点类型。是不是
- 空值:尽管这在上述所有数据类型中尤为常见, 但此处的空值仅表示该值不可用/为空。但是, 空值也可以其他形式出现。以皮马印第安人糖尿病数据集为例。数据集包含诸如血浆葡萄糖浓度, 舒张压之类的列的零值, 这实际上是无效的。如果你对数据集执行任何统计分析而没有处理这些无效条目, 则你的分析将不准确。
现在让我们研究这些问题可能引起的问题以及如何处理它们。
凌乱数字及其处理问题
现在, 让我们看一下如果不清除凌乱的数据(可能是上述类型的错误)可能会遇到的最常见问题。
1.数据汇总
假设数字列的输入为空, 并且你正在计算该列的摘要统计信息(例如平均值, 最大值, 最小值)。在这种情况下, 结果将无法准确传达。再次考虑带有无效零条目的Pima印度糖尿病数据集。如果你如前所述在列上计算摘要统计信息, 你将得到正确的结果吗?结果会不会是错误的?那么, 如何解决这个问题呢?有几种方法:
- Removing the entries containing missing/null values (not recommended)
- Imputing the null entries with a numeric value (typically with mean or median of the respective column)
现在让我们动手处理这些问题, 以及对抗空值的第二种选择。
考虑以下名为条目的PostgreSQL表:
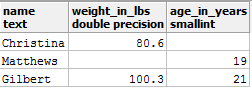
你可以在上表中看到两个空条目。假设你要从该表中获取平均重量值, 并执行了以下查询:
select avg(weight_in_lbs) as average_weight_in_lbs from entries;
你得到90.45作为输出。它是否正确?那么, 该怎么办呢?让我们借助COALESCE()函数用该平均值填充空条目。
让我们首先用COALESCE()填充缺失的值(请记住, COALESCE()不会更改原始表中的值, 它只是返回更改了值的表的临时视图):
select *, COALESCE(weight_in_lbs, 90.45) as corrected_weights from entries;
你应该得到如下输出:
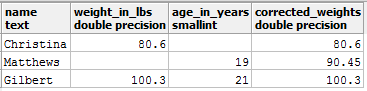
现在, 你可以再次应用AVG():
select avg(corrected_weights) from
(select *, COALESCE(weight_in_lbs, 90.45) as corrected_weights from entries) as subquery;
这比以前的结果要准确得多。现在, 让我们研究如果列数据类型不匹配, 可能会发生的另一个问题。
2.表联接
考虑你正在使用以下表格student_metadata和department_details:

你可以在student_mtadata表中看到, dept_id是整数类型, 在department_details表中, 它以文本类型显示。现在, 假设你想连接这两个表并要生成一个包含以下列的报告:
- id
- 名称
- 部门名称
为此, 你运行以下查询:
select id, name, dept_name from
student_metadata s join department_details d
on s.dept_id = d.dept_id;
你将遇到此错误, 然后:
错误:运算符不存在:smallint =文本
这是一个描述此问题的惊人图表(来自srcmini的SQL报表课程):
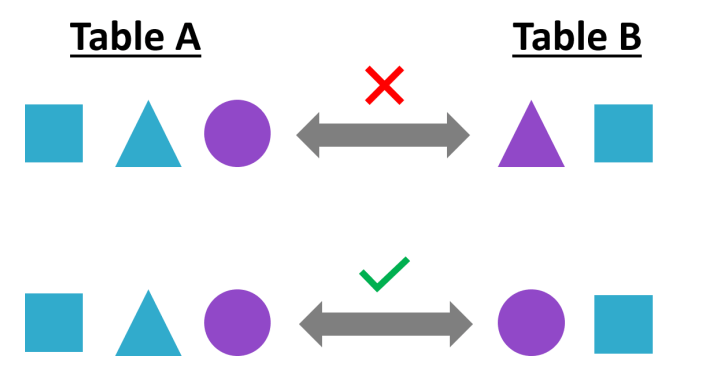
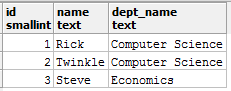
发生这种情况是因为在连接两个表时数据类型未匹配。在这里, 你可以在联接表时将department_details表中的dept_id列CAST为整数。这样做的方法如下:
select id, name, dept_name from
student_metadata s join department_details d
on s.dept_id = cast(d.dept_id as smallint);
你会得到所需的报告:
现在让我们讨论字符串如何以凌乱的形式出现, 它们的问题以及处理它们的方式。
凌乱的琴弦并清洁它们
字符串值也很常见。让我们从查看名为student_details的表中的列dept_name(表示部门名称)的值开始本节:
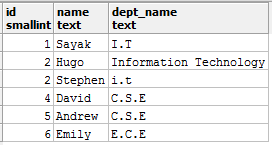
像上面这样的字符串值可能会导致很多意想不到的问题。 I.T, 信息技术和i.t均指同一部门, 即信息技术, 并且假设规范文档要求这些值仅作为I.T出现。现在, 假设你要计算属于IT部门的学生人数, 然后运行以下查询:
select dept_name, count(dept_name) as student_count
from student_details
group by dept_name;
你会得到:
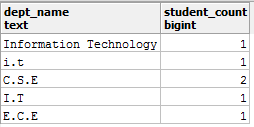
这是准确的报告吗? -不!那么, 你如何解决这个问题呢?
首先, 让我们更详细地确定问题:
- 你将信息技术作为一种价值, 应该转换为IT和
- 你将i.t作为另一个值, 应将其转换为I.T.
在第一种情况下, 你可以将值Information Technology替换为I.T, 在第二种情况下, 可以将字符转换为UPPER形式。尽管建议你逐步解决此类问题, 但你可以在单个查询中完成此操作。这是解决该问题的查询:
select upper(replace(dept_name, 'Information Technology', 'I.T')) as dept_cleaned, count(dept_name) as student_count
from student_details
group by dept_cleaned;
和报告:
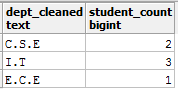
你可以在此处阅读有关PostgreSQL字符串函数的更多信息。
现在让我们讨论一些示例, 其中日期值可能很乱, 你可以执行哪些操作来清理它们。
凌乱的日期并清理它们
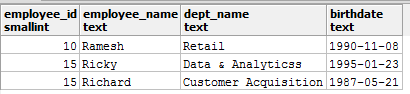
考虑到你正在使用名为employees的表, 该表包含一个名为birthdate的列, 但没有适当的日期类型。现在, 你想使用专用日期函数(例如DATE_PART())执行查询。除非并且直到你将生日日期列设置为日期类型, 否则你将无法执行此操作。让我们看看实际情况。
考虑生日为YYYY-MM-DD格式。
员工表如下所示:
现在, 你运行以下查询从生日中提取月份:
select date_part('month', birthdate) from employees;
然后你立即收到此错误:
错误:函数date_part(未知, 文本)不存在
除了错误以外, 你还会得到一个很好的提示:
提示:没有函数与给定的名称和参数类型匹配。你可能需要添加显式类型转换。
让我们按照提示将CAST生日设置为适当的日期类型, 然后应用DATE_PART():
select date_part('month', CAST(birthdate AS date)) as birthday_months from employees;
你应该得到结果:

现在, 让我们继续本教程的总结部分, 你将在其中研究数据重复的影响以及如何解决它们。
数据重复:原因, 影响和解决方案
在本节中, 你将研究导致数据重复的一些最常见原因。你还将看到它们的影响以及防止它们发生的一些方法。考虑以下两个表band_details和some_festival_record:

表band_details传达了有关音乐乐队的信息, 其中包含它们的标识符, 名称和已完成的演出总数。另一方面, 表some_festival_record描绘了一个假设的音乐节, 并包含有关在那里进行的乐队表演的记录。
现在, 假设你要生成一个报告, 其中应包含乐队名称, 他们的演出次数以及他们在音乐节上演出的总次数。这里需要内部连接。你运行以下查询:
select band_name, sum(total_show_count) as total_shows, sum(performed) as total_times_performed
from band_details b join some_festival_record s
on b.id = s.band_id
group by band_name;
查询产生:
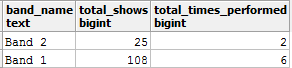
你不认为total_shows值在这里是错误的吗?因为从band_details表中, 你知道Band_1总共交付了36个节目。那这里出了什么问题?重复!
在联接两个表时, 你错误地汇总了total_show_count列, 这导致中间联接结果中的数据重复。如果删除聚合并相应地修改查询, 则应获得所需的结果:
select band_name, total_show_count, sum(performed) as total_times_performed
from band_details b join some_festival_record s
on b.id = s.band_id
group by band_name, total_show_count;
你现在可以得到预期的结果:
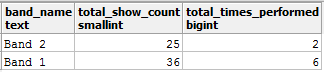
还有另一种防止数据重复的方法, 即在JOIN子句中添加另一个字段, 以便在更严格的条件下连接表。
你可以使用此.SQL文件生成此处使用的表, 并显示值。
进一步发展
感谢你阅读本教程。本教程向你介绍了数据分析管道中最重要的步骤之一-数据清理。你看到了各种形式的混乱数据以及解决它们的方法。但是, 可以使用更先进的技术来处理更复杂的数据清理问题, 如果你想在这方面有所作为, 可以参考以下一些出色的srcmini课程:
- 在SQL中联接数据
- 用SQL报告
欢迎在”评论”部分发表你的观点。
评论前必须登录!
注册