 srcmini
srcmini本文概述
首先, 你将学习人工智能, 然后转向机器学习和深度学习。你将进一步学习机器学习与深度学习有何不同, 深度学习属于这两个学习领域。最后, 将向你介绍一些应用了机器学习和深度学习的现实应用程序。
什么是人工智能?
顾名思义, 通常被称为AI的人工智能是一种使计算机智能化的方式。你能想到一台计算机或机器人来完成类似于人类的各种任务吗?它是计算机科学的一个分支, 你可以在其中以编程方式对机器进行编码以使其变得智能。
人工智能之父约翰·麦卡锡(John McCarthy)说, 这是”制造智能机器, 特别是智能计算机程序的科学和工程学”。
人工智能背后的直觉与动机
人类的大脑, 是的, 你没看错。人工智能背后的直觉和动力来自人脑。这是赋予人类的最强大的工具。人类是地球上最聪明的物种。 Neocortex是这个强大大脑背后的秘密调味料。 Neocortex赋予你思考, 行动, 运作, 记忆等的能力。这是一个普遍的神话, 鲸鱼比人类聪明, 这是不正确的, 因为鲸鱼在其新大脑皮层中有4-5层, 比人类的大脑皮层小。在它们的新皮层有六层, 比鲸鱼更重要。
你的大脑以这种方式连接, 新皮层记忆负责存储的不是图像, 而是存储模式(时间和空间模式)。当这些模式或记忆被召回时, 大脑会预测它应该看到或听到的以及遇到的东西。如果该预测是正确的, 则人类会感到平常, 但是当该预测不正确时, 会让人感到惊讶。
科学足够了吗?
无论如何, 正如大家都记得的那样, 当你是3-4岁时, 你父母的习惯是让你学习26个英文字母, 这些字母组合成一个单词, 单词组合成一个句子等等。随着年龄的增长, 你开始从环境中学习, 就像玩耍时一样。如果你摔倒了, 大脑会记住不要再犯同样的错误。了解了所有这些信息后, 你就可以预测结果了, 比如说Z之前但X后面是Y时的结果, 或者乘以12等于24等于2。
因此, 出于类似的直觉, 人们希望计算机能够根据你输入的数据进行学习, 然后计算机应该足够聪明, 可以根据已学到的知识来做出决策。
根据Wikipedia的说法, “人工智能(AI), 有时也称为机器智能, 是由机器展示的智能, 与人类和其他动物所展现的自然智能形成对比。在计算机科学中, 人工智能的研究被定义为对”智能主体”的研究。 :能感知环境并采取行动以最大程度地成功实现目标的任何设备。”
需要智能机器吗?
我们之所以需要AI, 其背后的一个主要原因是使人们觉得多余的任务自动化。请记住, 在将两个或多个数字相乘时, 计算机在计算上要聪明得多, 它们可以在几秒钟内给出结果, 而人类却在挣扎。
同样, 如果使计算机根据记录学习一些数据或记录, 则由于可以从过去的数据或记录中了解某些模式和结构, 因此可以轻松预测未来的结果。
例如:假设你的大脑MRI图像质量下降, 可能是因为它缺乏清晰度, 并且使医生难以看到你的大脑扫描图像。在这种情况下, 人工智能可以派上用场, 使用正确的算法集, 例如使用机器学习算法对低分辨率的大脑MRI图像执行超分辨率, 可以将MRI图像投影到高清晰度图像中, 从而提高MRI图像的质量。分辨率空间。
这只是一个例子。在许多现实生活中, 已经成功部署了AI。
现在是时候学习一下什么是机器学习了, 因此, 不用多说, 让我们开始吧!
机器学习
从最基本的意义上讲, 机器学习(ML)是一种实现人工智能的方法。与AI相似, 机器学习是计算机科学的一个分支, 你可以在其中设计或研究可以学习的算法的设计。
有多种机器学习算法, 例如
- 决策树
- 朴素贝叶斯,
- 随机森林
- 支持向量机
- K近邻,
- K-均值聚类
- 高斯混合模型
- 隐马尔可夫模型等
现在, 请了解在机器学习中, 你使用了上述算法之一, 该算法使计算机能够自动学习和理解, 而无需反复编程。
现在的问题是计算机将如何自动学习?
好吧, 答案就是数据。你输入的数据具有算法必须理解的不同属性或特征, 并根据你提供的数据为你提供决策边界。一旦算法学习并解释了数据, 即意味着它已经训练好了, 你就可以将算法置于测试阶段, 而无需对其进行显式编程, 而是输入测试数据点并期望它会为你提供一些结果。
例如:假设你必须预测房屋的价格, 给定一个数据集, 其中包括房屋价格和房屋中的房间数, 以及具有类似属性的1000座房屋。价格和房间数都是特色。现在你的目标是将这两个功能提供给决策树算法。在这种情况下, 你的输入将是房间的数量, 并且算法必须预测房屋的价格。该算法将尝试了解房间数量与房屋成本之间的关系。
现在, 在测试时, 你将给该算法输入3(房间数)作为输入, 它应该能够准确预测房屋价格!
那不是很神奇吗?
让我们进一步深入研究机器学习, 看看它背后有什么!
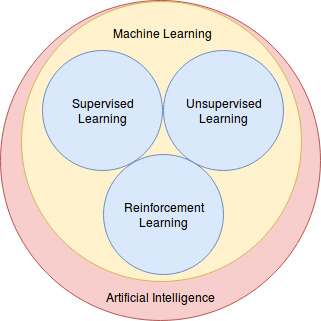
人工智能圈
众所周知, 机器学习是AI的子类别。同样, 各种学习算法也属于机器学习范畴。
从上图可以了解机器学习中的各种算法, 因此让我们快速了解它们吧!
- 监督学习:顾名思义, 监督是一种控制整个学习过程的学习技术。这些学习算法的主要目标是在给定一组训练样本以及训练标签(也称为对数据点进行分类)的情况下预测结果。由于你在训练时告诉算法, 它应该预测什么, 因此称为监督学习。让我们通过一个例子来理解它。
假设你有10, 000张图片, 5000张猫图片和5000张狗图片, 每张猫和狗图片的标签分别为0和1。现在, 该技术的目标是在给定约束作为标签的情况下在数据中查找模式。监督学习算法将尝试在10, 000张图像之间找到边界, 将它们分为两半。这样, 在测试时, 当新图像(例如, 猫图像)作为输入而没有任何标签时, 算法会将其放入标签为0的猫篮子中, 这意味着该算法能够将该图像预测/分类为猫的形象。
瞧!这不奇怪吗?

监督学习
- 无监督学习:与无监督学习不同, 你没有针对训练样本的训练标签。算法的制定方式使得它们可以在数据中找到合适的结构和模式。一旦这些一致的模式变得显而易见, 就可以将相似的数据点聚在一起, 而不同的数据点将位于不同的聚类中。它主要用于将高维数据投影到低维, 以进行可视化或分析。

无监督学习
- 强化学习:这是一种机器学习, 具有代理(如机器人)来通过采取行动和量化结果来学习如何在环境中表现。如果代理做出正确的响应, 它将获得奖励积分, 这会提高代理采取更多此类行动的信心。它适用于也称为(MDP)的马尔可夫决策过程。
例如:在下图中, 你可以看到代理(机器人)在环境(迷宫)中采取行动, 翻译是眼睛, 它会为每一个正确的举动获得奖励, 并根据其当前状态采取下一个行动行动。

强化学习(来源)
强化学习的一些很酷的应用是玩游戏(Alpha Go, Chess, Mario), 机器人技术, 交通灯控制系统等。
这就是关于机器学习的全部内容。现在是时候让你对深度学习有所了解了!
深度学习!
它是机器学习的子类别。与机器学习类似, 深度学习在其中也可以进行监督, 无监督和强化学习。如前所述, 人工智能的思想是受人脑启发的。因此, 让我们尝试在这里连接点, 深度学习受到人工神经网络的启发, 而通常称为ANN的人工神经网络则受到人类生物神经网络的启发。深度学习是执行机器学习的方式之一。
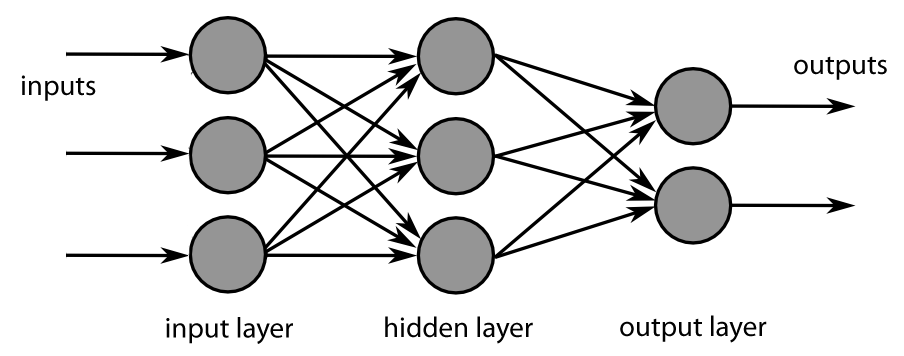
浅层神经网络(来源)
从上图可以看到, 它是一个浅层神经网络, 可以称为”浅层学习网络”。神经网络将始终具有:
- 输入层:可以是图像的像素或时间序列数据
- 隐藏层:通常称为权重, 它是在训练神经网络时学习的
- 输出层:最终层主要是为你提供输入到网络的输入的预测。
因此, 神经网络是一种近似函数, 在该函数中, 神经网络尝试学习隐藏层中的参数(权重), 当将其与输入相乘时, 将为你提供接近所需输出的预测输出。
深度学习只不过是在输入和输出层之间堆叠多个这样的隐藏层, 因此命名为深度学习
深度学习方法
有多种设计用于应用深度学习的方法。每个提议的方法都有一个特定的用例, 例如你拥有的数据类型, 你想应用的有监督的学习还是无监督的学习, 要用数据解决什么类型的任务。因此, 根据这些因素, 你可以选择最能解决问题的一种方法。
一些深度学习方法是:
- 卷积神经网络
- 递归神经网络
- 长期记忆
- 自动编码器
- 去噪自动编码器
- 堆叠式自动编码器
- 可变自动编码器
- 稀疏自动编码器
- 生成对抗网络
深度学习可用于:
- 分类:是预测猫还是狗的任务, 甚至是多类别的分类,
- 特征提取以可视化低维空间中的数据,
- 数据预处理
- 时间序列预测:库存预测, 天气预报等,
- 回归任务, 例如本地化,
- 对象识别既是分类任务也是回归任务,
- 机器人技术。
深度学习与机器学习之间的比较!
- 功能:深度学习是机器学习的一个子集, 它以数据为输入, 并使用逐层堆叠的人工神经网络做出直观而智能的决策。另一方面, 机器学习是深度学习的超集, 它以数据为输入, 解析数据, 并根据其在训练中所学到的知识(决策)进行尝试。
- 特征提取器:深度学习被认为是从原始数据中提取有意义特征的一种合适方法。它不依赖于手工制作的特征, 例如局部二进制模式, 梯度直方图等, 最重要的是, 它执行分层特征提取。它逐层学习特征, 这意味着在初始层它学习低层特征, 并且随着层次结构的上移, 它开始学习数据的更抽象表示(如下图所示)。另一方面, 机器学习不是从数据中提取有意义的特征的好方法。它依靠手工制作的功能作为出色表现的输入。

深度学习网络学习的分层功能(来源)
这里的特征是指平均像素值, 形状, 纹理, 位置, 颜色和方向。大多数传统机器学习算法的性能取决于识别和提取特征的准确性。使用传统的特征提取器并不能解决重大问题, 因为即使数据稍有变化也会改变从常规特征提取器提取的特征, 例如局部二进制模式(LBP), 定向梯度直方图(HOG)等。学习网络尝试通过组合不同级别的层来学习所有这些功能, 最后将它们组合起来以形成更大的图片作为抽象表示。
- 数据依赖性:即使数据集很小, 机器学习算法也通常能很好地起作用, 但是深度学习是”数据饥渴”, 你拥有的数据越多, 执行的效果就越好。人们常说, 随着数据的增加, 网络深度(层数)也会增加, 因此需要进行更多的计算。

数据量(x轴)与性能(y轴)的关系图
从上图可以看到, 与传统的机器学习算法相比, 随着数据的增加, 深度学习算法的性能也随之提高, 在传统的机器学习算法中, 即使增加数据, 性能也会在不久后达到饱和。
- 计算能力:正如你所了解的那样, 深度学习网络依赖于数据, 因此它们所需要的不仅仅是CPU所能提供的。对于深度学习网络培训, 你需要一个图形处理单元(GPU), 该图形处理单元(GPU)具有数千个内核, 而CPU的内核却非常少。计算能力不仅取决于数据量, 还取决于网络的深度(大), 随着数据量或层数的增加, 你将需要越来越多的计算能力。另一方面, 传统的机器学习算法可以在规格相当不错的CPU上实现。
训练和推断时间:深度学习网络的训练时间范围从几个小时到几个月不等。是的, 你没有看错!培训通常可以持续数月。如果你有大量数据, 则对网络进行训练以获取更重要的数据通常需要时间。此外, 随着网络中层数的增加, 称为权重的参数数将增加, 因此导致训练缓慢。
由于输入的测试数据将通过网络中的所有层, 因此不仅训练而且非常深入的神经网络也可能要花费大量的推理时间, 因此会发生大量乘法运算, 这将花费大量时间。
传统的机器学习算法通常训练非常快, 范围从几分钟到几个小时不等, 但是在测试期间, 某些算法也可能花费相当多的时间。
- 解决问题的技术:要使用机器学习解决问题, 你必须将问题分为不同的部分。假设你要进行对象识别, 因为你首先要遍历完整图像并查找每个位置是否存在对象以及对象的确切位置。 “然后, 从所有候选对象中, 应用机器学习算法, 比方说将支持向量机(SVM)与局部二进制模式(LBP)作为特征提取器来识别相关对象。另一方面, 在深度学习中, 你需要通过网络将边界框坐标和所有对象的相应标签都进行网络连接, 网络将学习自行进行本地化和分类。” -资源”
- 行业就绪:机器学习算法通常很容易对它们的工作方式进行解码。对于选择什么参数以及为什么选择这些参数, 它们是可以解释的, 但是另一方面, 深度学习算法不过是一个黑匣子。即使深度学习算法的性能可以超过人类, 但在行业中部署它们仍然不可靠。机器学习算法(例如线性回归, 决策树, 随机森林等)已广泛用于行业, 例如其用例之一是在银行部门中进行股票预测。
- 输出:传统机器学习的输出通常是一个数值, 例如分数或分类。深度学习方法的输出可以是分数, 元素, 文本, 语音等。
机器学习和深度学习的应用!
机器学习和深度学习在许多领域中得到广泛使用, 仅举几例:
- 医疗:用于癌细胞检测, 脑部MRI图像恢复, 基因打印等。
- 文档:超分辨率历史文档图像, 在文档图像中分割文本。
- 银行:股票预测, 财务决策。
- 自然语言处理:推荐系统:Netflix使用推荐系统根据用户的兴趣, 情感分析和照片标签向他们推荐电影。
- 信息检索:搜索引擎, 包括文本搜索和图像搜索, 例如Google, Amazon, Facebook, Linkedin等所使用的搜索引擎。
前景
深度学习和机器学习在相当长的一段时间内都在蓬勃发展, 并且从现在开始至少要持续十年。这些行业正在部署深度学习和机器学习算法以产生更多收入;他们正在教育员工学习这项技能, 并为他们的公司做出贡献。许多创业公司都提出了新颖的深度学习解决方案, 可以解决挑战性问题。
不仅行业, 而且学术界每天都在进行大量具有开创性的研究, 而深度学习的方式正在彻底改变整个世界, 令人难以置信。深度学习架构的性能比现代方法要好得多, 并且取得了最先进的性能。
在未来几年中, 拥有深度学习和机器学习技能的行业或学术界的生存很可能会发挥重要作用。
总结
在今天的帖子中, 向你介绍了人工智能的全面理论分析和两种实现人工智能的技术, 即机器学习和深度学习。你还了解了各种机器学习和深度学习算法, 以及这两种学习技术之间的区别。
这篇文章仅仅是个开始;还有很多内容要讲, 为什么不参加srcmini的Python深度学习课程呢?此外, 遵循Python与Keras结合使用卷积神经网络教程可能对你们所有人来说都是一个很好的起点!
评论前必须登录!
注册