 srcmini
srcmini首先, 让我们导入基本必需的库来处理数据集。
import pandas as pd
现在, 让我们阅读数据集并查看它。
bfriday = pd.read_csv("BlackFriday.csv")
bfriday.head(10)
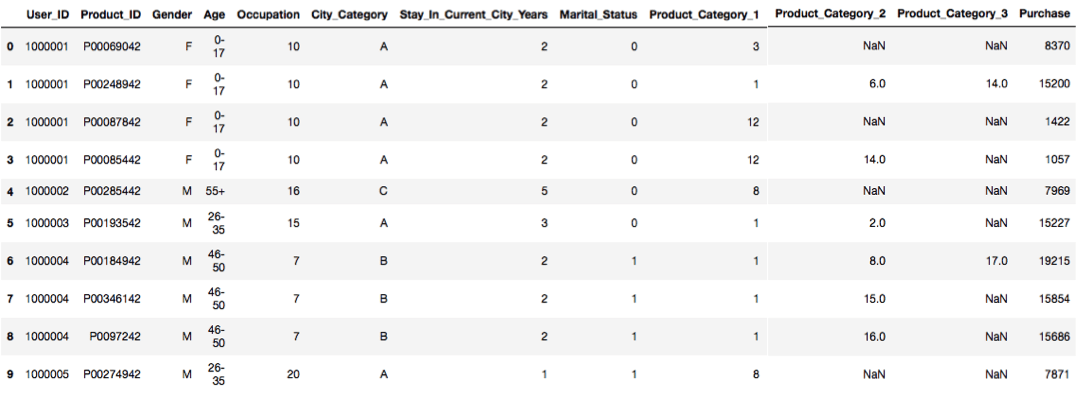
上一行是由10行和所有列组成的数据集的一部分。如果你尝试给出bfriday.head(x, y), 那将是一个错误, 因为计算机已经占用了强制列的总数。bfriday.head()这也将为你提供输出, 并且不会有任何错误, 并且计算机接受其选择的行和列
bfriday.shape #this gives use dimensions of dataset(rows, columns)
(550068, 12)
bfriday['Stay_In_Current_City_Years'].value_counts()# counts the number of values per each range, bfriday['City_Category'].value_counts()
1 193821
2 101838
3 95285
5 84726
0 74398
Name: Stay_In_Current_City_Years, dtype: int64
bfriday.isnull().sum() #colculates no of null values for each category in dataset
User_ID 0
Product_ID 0
Gender 0
Age 0
Occupation 0
City_Category 0
Stay_In_Current_City_Years 0
Marital_Status 0
Product_Category_1 0
Product_Category_2 173638
Product_Category_3 383247
Purchase 0
dtype: int64
b = ['Product_Category_2', 'Product_Category_3'] #here we are making an array consisting of 2 columns namely Product_Category_2, Product_Category_3
for i in b:
exec("bfriday.%s.fillna(bfriday.%s.value_counts().idxmax(), inplace=True)" %(i, i))
现在, 我们将用最大值填充空白空间。我们还可以使用bfriday.Product_Category_2.fillna(bfriday.Product_Category_2.value_counts()。idxmax(), inplace = True)清理或填充空白, 类似地, 你也可以清理名为Product_category_3的列
X = bfriday.drop(["Purchase"], axis=1)
现在, 我们从数据集中删除了名为purchase的列, 并构造了一个名为X的数组, 该数组由除purchase列之外的所有列组成。
from sklearn.preprocessing import LabelEncoder#Now let's import encoder from sklearn library
LE = LabelEncoder()
#Now we will encode the data into labels using label encoder for easy computing
X = X.apply(LE.fit_transform)#Here we applied encoder onto data
现在, 我们将使用pandas将数据转换为数字形式, 因为处理数字数据比处理分类数据更容易
X.Gender = pd.to_numeric(X.Gender)
X.Age = pd.to_numeric(X.Age)
X.Occupation = pd.to_numeric(X.Occupation)
X.City_Category = pd.to_numeric(X.City_Category)
X.Stay_In_Current_City_Years = pd.to_numeric(X.Stay_In_Current_City_Years)
X.Marital_Status = pd.to_numeric(X.Marital_Status)
X.Product_Category_1 = pd.to_numeric(X.Product_Category_1)
X.Product_Category_2 = pd.to_numeric(X.Product_Category_2)
X.Product_Category_3 = pd.to_numeric(X.Product_Category_3)
Y = bfriday["Purchase"]#Here we will made a array named as Y consisting of data from purchase column
from sklearn.preprocessing import StandardScaler
SS = StandardScaler()
通过去除均值并按比例缩放到单位方差来标准化特征通过计算训练集中样本的相关统计信息, 对每个特征独立进行对中和缩放。然后存储平均值和标准偏差, 以使用变换方法在以后的数据上使用。
Xs = SS.fit_transform(X)
#You must to transform X into numeric representation (not necessary binary).Because all machine learning methods operate on matrices of number
from sklearn.decomposition import PCA
pc = PCA(4)#here 4 indicates the number of components you want it into.
使用数据的奇异值分解进行线性降维是将数据投影到较低维空间.PCA是最常用的降维方法之一, PCA用于加速机器学习算法, 你可以将PCA拟合到训练集上只要。主成分分析(PCA)
PCA用新变量(称为主成分)替换了原始变量, 这些新变量的协变量为零, 并且降序变化。因此, 从数据中提取出主成分之间的协方差矩阵。

资料来源:6.3-主成分分析(PCA)
注意:-切勿对稀疏数据使用RandomizedPCA。在稀疏数据上使用RandomizedPCA是不正确的, 因为我们无法在不破坏稀疏性的情况下将数据居中, 这可能会破坏实际大小的稀疏数据的内存。但是, PCA需要居中
principalComponents = pc.fit_transform(X)#Here we are applying PCA to data/fitting data to PCA
pc.explained_variance_ratio_
array([7.35041374e-01, 2.64935995e-01, 1.10061180e-05, 6.21704987e-06])
principalDf = pd.DataFrame(data = principalComponents, columns = ["component 1", "component 2", "component 3", "component 4"])
from sklearn.model_selection import KFold
kf = KFold(20)
#Provides train/test indices to split data in train/test sets. Split dataset into k consecutive folds (without shuffling by default).
#Each fold is then used once as a validation while the k - 1 remaining folds form the training set.
for a, b in kf.split(principalDf):
X_train, X_test = Xs[a], Xs[b]
y_train, y_test = Y[a], Y[b]
from sklearn.linear_model import LinearRegression
回归是要检查两件事:(1)一组预测变量是否能很好地预测结果(因变量)? (2)特别是哪些变量是结果变量的重要预测因子, 它们以什么方式(由beta估计的大小和符号表示)会影响结果变量?这些回归估计用于解释一个因变量和一个或多个自变量之间的关系。具有一个因变量和一个自变量的回归方程的最简单形式由公式y = c + b * x定义, 其中y =估计因变量得分, c =常数, b =回归系数, x =分数自变量。
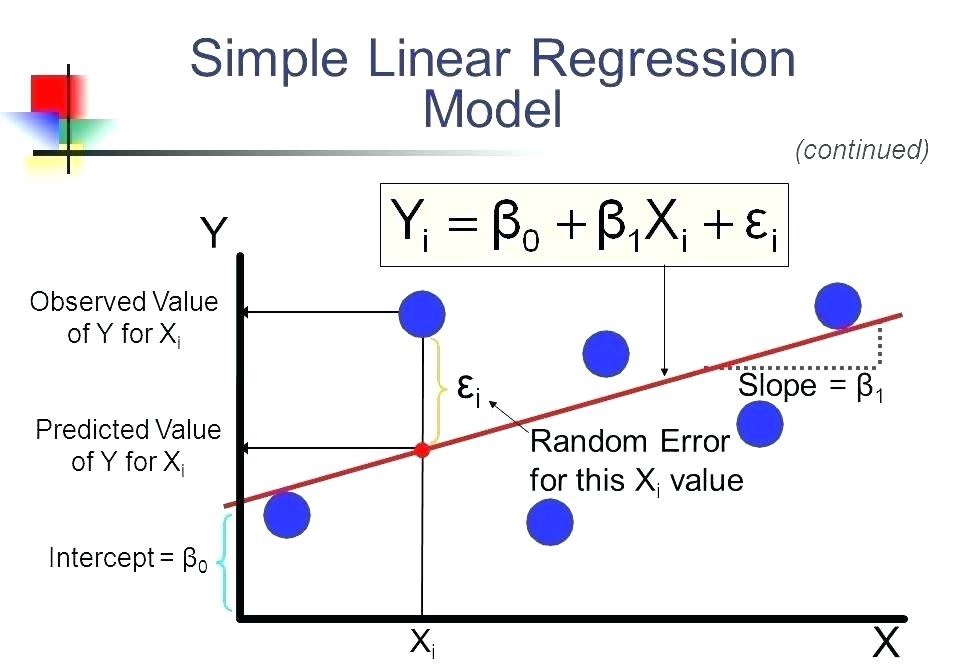
资料来源:线性回归
from sklearn.tree import DecisionTreeRegressor
决策树是从根节点开始自上而下构建的, 涉及将数据划分为包含具有相似值的实例的子集。决策树以树结构的形式构建模型。它将数据集分解为越来越小的子集, 与此同时, 关联的决策树也逐渐得到发展。最终结果是一棵具有决策节点和叶节点的树。决策节点(例如Outlook)具有两个或多个分支(例如Sunny, Overcast和Rainy), 每个分支代表测试属性的值。叶节点(例如, 播放的小时数)表示对数字目标的决定。树中最高的决策节点, 对应于称为根节点的最佳预测变量。决策树可以处理分类数据和数字数据。目标变量可以采用连续值(通常为实数)的决策树称为回归树。如果将树的最大深度设置得太高, 则决策树将学习训练数据的细节过于精细, 并从噪声中学习, 即它们过度拟合。

资料来源:决策树
from sklearn.ensemble import RandomForestRegressor
随机森林是一种估计器, 可将多个分类决策树拟合到数据集的各个子样本上, 并使用求平均值来提高预测准确性和控制过度拟合。子样本大小始终与原始输入样本大小相同, 但是如果bootstrap = True, 则将替换绘制样本。该技术背后的想法是去关联几棵树。它从训练数据中生成不同的自举样本(即自生成样本)。然后, 我们通过对它们进行平均来减少树木中的方差。因此, 在这种方法中, 它会在python或R中创建大量决策树。随机森林模型非常擅长处理具有数字特征的表格数据或具有少于数百个类别的分类特征的表格数据。随机森林具有捕获要素与目标之间的非线性交互作用的能力。
注意:基于树的模型不适用于稀疏特征。在处理稀疏输入数据时, 我们可以对稀疏特征进行预处理以生成数值统计数据, 或者切换到线性模型, 这更适合此类情况。
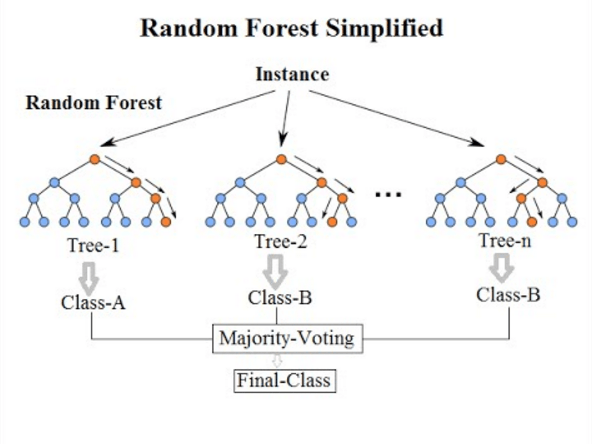
资料来源:William Koehrsen的《随机森林简单解释》
from sklearn.ensemble import GradientBoostingRegressor
梯度提升是一种针对回归和分类问题的机器学习技术, 它以弱预测模型(通常为决策树)的集合形式生成预测模型。像其他增强方法一样, 它以分阶段的方式构建模型, 并通过允许对任意可微分的损失函数进行优化来对其进行概括。提升可以解释为针对适当成本函数的优化算法。后两篇论文介绍了将Boosting算法作为迭代函数梯度下降算法的观点。也就是说, 通过迭代选择指向负梯度方向的函数(弱假设)来优化函数空间上的成本函数的算法。这种增强的功能梯度视图导致了机器学习和统计领域中除回归和分类之外的增强算法的发展。梯度增强以迭代的方式将弱的”学习者”组合为单个强学习者。在最小二乘回归设置中, 最简单的解释是目标是通过最小化均方误差来”教”模型F以预测y ^ = F(x)形式的值。

资料来源:梯度提升第1部分–视觉概念化
lr = LinearRegression()
dtr = DecisionTreeRegressor()
rfr = RandomForestRegressor()
gbr = GradientBoostingRegressor()
fit1 = lr.fit(X_train, y_train)#Here we fit training data to linear regressor
fit2 = dtr.fit(X_train, y_train)#Here we fit training data to Decision Tree Regressor
fit3 = rfr.fit(X_train, y_train)#Here we fit training data to Random Forest Regressor
fit4 = gbr.fit(X_train, y_train)#Here we fit training data to Gradient Boosting Regressor
fit():用于从训练数据生成学习模型参数
transform():从fit()方法生成的参数, 应用于模型以生成转换后的数据集。
fit_transform():它是对同一数据集的fit()和transform()api的组合
print("Accuracy Score of Linear regression on train set", fit1.score(X_train, y_train)*100)
print("Accuracy Score of Decision Tree on train set", fit2.score(X_train, y_train)*100)
print("Accuracy Score of Random Forests on train set", fit3.score(X_train, y_train)*100)
print("Accuracy Score of Gradient Boosting on train set", fit4.score(X_train, y_train)*100)
Accuracy Score of Linear regression on train set 11.829233894211866
Accuracy Score of Decision Tree on train set 100.0
Accuracy Score of Random Forests on train set 94.207451077798
Accuracy Score of Gradient Boosting on train set 65.49517152859553
print("Accuracy Score of Linear regression on test set", fit1.score(X_test, y_test)*100)
print("Accuracy Score of Decision Tree on test set", fit2.score(X_test, y_test)*100)
print("Accuracy Score of Random Forests on test set", fit3.score(X_test, y_test)*100)
print("Accuracy Score of Gradient Boosting on testset", fit4.score(X_test, y_test)*100)
Accuracy Score of Linear regression on test set 36.8210287243639
Accuracy Score of Decision Tree on test set 57.61911563230391
Accuracy Score of Random Forests on test set 74.71675935214292
Accuracy Score of Gradient Boosting on testset 72.43849411693184
本教程提供了有关如何填充空值的快速思路。我之所以这样写是因为, 在大多数情况下, 实际数据比较杂乱, 因为你有空值, 错误的值以及大量需要清除的废料。欢呼!你已经完成了本教程。如果你对本教程有任何疑问或想法, 请随时关注以下评论。
如果你想了解有关Python机器学习的更多信息, 请参加srcmini的Python机器学习预处理课程。
评论前必须登录!
注册