 srcmini
srcmini本文概述
考虑以下情况-
你正在处理数据集。你创建分类模型并立即获得90%的准确性。结果对你来说似乎很棒。你再深入一点, 就会发现几乎所有数据都属于一个类。该死的!数据不平衡可能会使你感到沮丧。
当你发现数据中的类不平衡并且以为你认为所有的出色结果都被骗了时, 你会感到非常沮丧。更令人沮丧的是, 好书甚至没有全面地涵盖这一主题。
这是数据集不平衡及其可能导致令人沮丧的结果的情况示例。
在本教程中, 你将发现可用于在数据不平衡的数据集上提供出色结果的技术。具体来说, 你将学习:
- 数据不平衡是什么意思?
- 为什么不平衡的数据集是一个严重的问题要解决?
- 准确性悖论
- 分类器评估的不同指标
- 处理不平衡数据的各种方法
- 关于该主题的进一步阅读
首先让我们看看什么是不平衡数据。

资料来源:KDNuggets
什么是不平衡数据?
不平衡数据通常是指分类任务, 其中类别没有被平等地表示。
例如, 你可能遇到100个实例的二进制分类问题, 其中80个实例标记为Class-1, 其余20个实例标记为Class-2。
这本质上是一个不平衡数据集的示例, 并且Class-1实例与Class-2实例的比率为4:1。
无论是Kaggle竞赛还是真实的测试数据集, 类不平衡问题都是最常见的问题之一。
大多数现实世界中的分类问题都显示出某种程度的类不平衡, 当没有足够的数据实例与任何一个类标签相对应时, 就会发生这种情况。因此, 必须正确选择模型的评估指标。如果未完成, 则可能最终会调整/优化无用的参数。在实际的业务至上方案中, 这可能会导致完全浪费。
在某些问题中, 阶级失衡不仅普遍存在;它一定会发生。例如, 处理欺诈性和非欺诈性交易的数据集, 与非欺诈性交易的数量相比, 欺诈性交易的数量很可能要少得多。这就是问题所在。你将研究原因。
为什么不平衡的数据集是一个严重的问题要解决?
尽管所有许多机器学习算法(无论是深度算法还是统计算法)在许多实际应用中都显示出了巨大的成功, 但是从不平衡数据中学习的问题仍然是最新技术。通常, 从不平衡数据中进行的学习称为不平衡学习。
以下是学习不平衡的重大问题:
- 当数据集的数据不足时, 类分布开始倾斜。
- 由于数据集固有的复杂特性, 从此类数据中学习需要对数据进行转换的新认识, 新方法, 新原理和新工具。而且, 这仍然不能保证为你的业务问题提供有效的解决方案。在最坏的情况下, 它可能会变成残留量为零的废物完全可以重复使用。
此时, 你必须想到的一个显而易见的问题是-为什么在GPU时代, TPU机器学习算法无法有效地解决不平衡的数据?很明显的问题, 你现在就可以找到答案。
对于特定的机器学习算法在提供不平衡数据时无法执行的原因, 机器学习算法的评估有很多工作要做。
“在这种情况下, 你的准确性衡量指标可以告诉你你具有出色的准确性(例如90%), 但是准确性仅反映了基础类的分布。” -精通机器学习
假设你有一个数据集(与分类任务相关联), 该数据集包含两个类, 分配比率为9:1。数据集中存在的实例总数为1000, 类别标签为Class-1和Class-2。因此, 使用分配比率, 对应于Class-1的实例数为900, 而Class-2实例的实例数为100。现在, 你应用了标准分类器(例如Logistic回归), 并测量了与分类精度有关的性能, 得出了分类器正确分类的实例数。现在, 仔细看看并进行深入思考。
将所有1000个实例归类为Class-1, 你的Logistic回归模型不必太复杂。在这种情况下, 你将获得90%的分类精度, 这实际上不足以测试分类器的实际质量。显然, 你需要一些其他指标来评估系统性能。你很快就会看到。你刚刚研究的现象称为准确性悖论。
处理不平衡数据的方法
你将通过研究除分类准确性以外的一些指标来开始本节, 以便在分类器处理不平衡数据时真正判断分类器。
首先, 让我们在这里定义四个基本术语:
- 真实正值(TP)–一个正值且正确分类为正值的实例
- 真负数(TN)–负数且正确分类为负数的实例
- 误报(FP)–否定但被错误分类为正数的实例
- 假阴性(FN)–实例为阳性, 但被错误地分类为阴性
下图将为上述条件辩护:
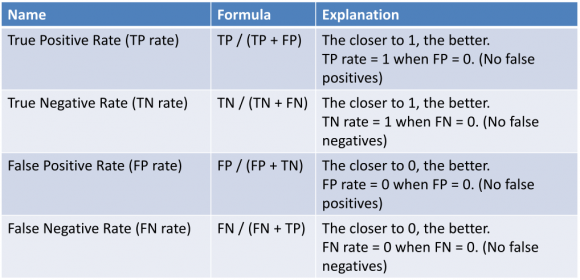
资源
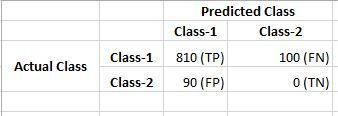
现在, 假设你在刚刚看到的玩具数据集上训练了另一个分类器, 这一次你应用了”随机森林”。你的分类精度为70%。现在, 你已经了解了真实的正负比率和错误的正负比率, 你将以更详细的方式研究早期Logistic回归和随机森林的性能。
假设你为逻辑回归得到以下正负率和误正负率:
现在, 假设随机森林的真实正负比率和错误正负负比率如下:
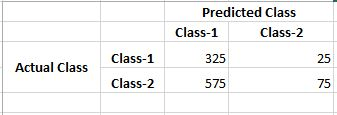
只需查看两个分类器正确预测的否定类的数量(真否定)即可。在处理不平衡的数据集时, 你需要将此数字设置为最高优先级(因为在数据集中, Class-1占主导)。因此, 考虑到这一点, Random Forest轻松权衡了Logistic回归。
现在, 你将在一个极好的地方学习解决不平衡数据集问题的方法。
(请记住, 以上表示形式通常被称为混淆矩阵。)
以下是从混淆矩阵派生的两个术语, 在评估分类器时经常使用。
精度:精度是真实肯定的数量除以真实肯定和错误肯定的数量。换一种方式;它是肯定预测的数量除以预测的肯定类别值的总数。也称为正预测值(PPV)。
可以将精度视为分类器准确性的度量。精度低也可能表示大量误报。
召回率:召回率是”正肯定”数除以”正肯定”数和”假负”数。换句话说, 它是肯定预测的数量除以测试数据中肯定类别值的数量。也称为灵敏度或真实正利率。
召回可以被认为是分类器完整性的度量。召回率低表明许多假阴性。
在这种情况下可能有用的其他一些指标:
- AUC
- ROC曲线
- f1-得分
- 马修斯相关系数(MCC)
之前, 你开始研究解决类不平衡问题的方法, 让我们以一个非常实际的示例为例, 在该示例中, 仅选择分类准确性作为评估指标可能会产生灾难性的结果。 (这样做是为了确保你在训练下一个分类器时不仅考虑分类准确性。)
乳腺癌数据集是标准的机器学习数据集。它包含9个属性, 描述286名罹患乳腺癌并幸存下来的妇女以及乳腺癌是否在5年内复发。让我们研究此数据集, 以使你真正了解问题。
数据集涉及二进制分类问题。在286名妇女中, 有201名没有患乳腺癌, 其余85名则没有。
让我们更直观地探索数据集。
import numpy as np
import pandas as pd
# Load the dataset into a pandas dataframe
data = pd.read_csv("breast-cancer.data", header=None)
# See the data
print(data.head(10))
0 1 2 3 4 5 6 7 8 \
0 no-recurrence-events 30-39 premeno 30-34 0-2 no 3 left left_low
1 no-recurrence-events 40-49 premeno 20-24 0-2 no 2 right right_up
2 no-recurrence-events 40-49 premeno 20-24 0-2 no 2 left left_low
3 no-recurrence-events 60-69 ge40 15-19 0-2 no 2 right left_up
4 no-recurrence-events 40-49 premeno 0-4 0-2 no 2 right right_low
5 no-recurrence-events 60-69 ge40 15-19 0-2 no 2 left left_low
6 no-recurrence-events 50-59 premeno 25-29 0-2 no 2 left left_low
7 no-recurrence-events 60-69 ge40 20-24 0-2 no 1 left left_low
8 no-recurrence-events 40-49 premeno 50-54 0-2 no 2 left left_low
9 no-recurrence-events 40-49 premeno 20-24 0-2 no 2 right left_up
9
0 no
1 no
2 no
3 no
4 no
5 no
6 no
7 no
8 no
9 no
列名是数字的, 因为你使用的是部分预处理的数据集。但是, 如果你有兴趣, 则可以参考下图:

资源
让我们看一下类分布的条形图。
import matplotlib.pyplot as plt
classes = data[9].values
unique, counts = np.unique(classes, return_counts=True)
plt.bar(unique, counts)
plt.title('Class Frequency')
plt.xlabel('Class')
plt.ylabel('Frequency')
plt.show()

你可以在这里清楚地看到班级不平衡。 “是”表示患有癌症并且很明显的实例, 与对应于其他类别的实例相比, 这些实例的数量最少。
让我们定义数据集中存在的”无重复发生”和”重复发生”事件, 这将使事情变得更加明显。
- 全部不复发:仅预测没有乳腺癌复发的模型将达到(201/286)* 100或70.28%的准确性。这被称为”全无复发”。这是一个高精度, 但是很糟糕的模型。如果这种模式被误解, 则会使85名妇女误以为自己的乳腺癌不会再发生(误假率很高), 送回家中。
- 所有复发:仅预测乳腺癌复发的模型将达到(85/286)* 100或29.72%的准确性。这就是所谓的”所有复发”。此模型无法产生良好的准确性, 会使201名认为患有乳腺癌复发的妇女回家, 但事实并非如此(高误报率)。
这个概念现在应该已经在你体内激发了火花。让我们继续前进。
好!现在, 你有足够的理由怀疑为什么仅考虑分类精度来评估分类模型不是一个好选择。
现在让我们研究一些方法。
重新采样数据集:
处理不平衡的数据集包括各种策略, 例如在将数据作为输入提供给机器学习算法之前, 改进训练算法中的分类算法或平衡类(本质上是数据预处理步骤)。后一种技术是优选的, 因为它具有更广泛的应用和适应性。而且, 增强算法所需的时间通常比生成所需样本所需的时间更长。但是出于研究目的, 两者都是首选。
抽样类别的主要思想是增加少数类别的样本或减少多数类别的样本。这样做是为了在两个类的实例数量上获得合理的平衡。
采样可以有两种主要类型:
- 你可以从少数类中添加实例的副本, 这称为过采样(或更正式地说是替换采样), 或者
- 你可以从多数类中删除实例, 这称为欠采样。
从实现的角度来看, 这听起来也更加容易。是不是在本文的后面, 你将了解一个专门用于执行采样的库。
随机欠采样:
当你从数据集的多数类中随机消除实例并将其分配给少数类(不填写在多数类中创建的空白)时, 这称为随机欠采样。在多数数据集中为此创建的空隙使过程随机化。
这种方法的优点:
- 当训练数据集很大时, 它可以通过减少训练数据样本的数量来帮助改善模型的运行时间并解决内存问题。
缺点:
- 它可以丢弃有关数据本身的有用信息, 这对于构建基于规则的分类器(例如”随机森林”)可能是必需的。
- 通过随机欠采样选择的样本可能是有偏差的样本。在那种情况下, 这将不是人口的准确代表。因此, 这可能会导致分类器在实际看不见的数据上表现不佳。
随机过采样:
就像随机欠采样一样, 你也可以执行随机过采样。但是在这种情况下, 在多数类的帮助下, 你可以通过将它们复制到恒定程度来增加与少数类相对应的实例。在这种情况下, 你不会减少分配给多数类的实例的数量。假设你有一个包含1000个实例的数据集, 其中980个实例对应于多数类, 而扩孔的20个实例对应于少数类。现在, 你通过将20个实例最多复制20次来对数据集进行过度采样。结果, 执行过采样后, 少数类中的实例总数将为400。
随机过采样的优点:
- 与欠采样不同, 此方法不会导致信息丢失。
缺点:
- 由于它复制了少数群体事件, 因此增加了过度拟合的可能性。
在考虑应用欠采样和过采样时, 可以考虑以下因素:
- 当你有大量数据时, 请考虑使用欠采样
- 当你没有大量数据时, 请考虑使用过度采样
- 考虑应用随机和非随机(例如分层)抽样方案。
- 考虑应用不同比例的类别标签(例如, 在二进制分类问题中你不必将1:1比例作为目标, 请尝试其他比例)
如果要在Python中实现欠采样和过采样, 则应签出scikit-learn-contrib。
现在, 你将研究处理不平衡数据的下一种方法。
尝试生成合成样本:
创建合成样本的一种简单方法是从少数类中的实例随机采样属性。
你可以使用系统的算法来生成合成样本。这种算法中最流行的称为SMOTE或合成少数采样技术。它是在2002年提出的, 你可以看看原始的SMOTE论文。以下信息图将为你提供有关合成样品的合理思路:
资源
SMOTE是一种过采样方法, 它创建”合成”示例, 而不是通过替换进行过采样。通过获取每个少数族裔样本并沿连接任何/所有k个少数族裔最近邻的线段引入综合示例, 对少数族裔进行过采样。根据所需的过采样量, 从k个最近的邻居中随机选择邻居。
SMOTE的核心是少数群体的建设。构造算法背后的直觉很简单。你已经研究了过度采样会导致过度拟合, 并且由于重复的实例, 决策边界变得更严格。如果你可以生成相似的样本而不是重复它们怎么办?在原始的SMOTE论文(如上链接)中, 已经表明, 对于机器学习算法, 这些新构造的实例不是精确的副本, 因此可以软化决策边界, 从而帮助算法更准确地近似假设。
但是, SMOTE有一些优点和缺点-
优点 –
- 当生成合成示例而不是复制实例时, 可缓解由随机过采样引起的过拟合。
- 不丢失任何信息。
- 实现和解释很简单。
缺点-
- 在生成综合示例时, SMOTE不考虑相邻示例可能来自其他类别。这会增加类的重叠, 并会引入其他噪声。
- 对于高维数据, SMOTE不太实用。
SMOTE有一些变体, 例如安全级别的SMOTE, 边界线SMOTE, OSSLDDD-SMOTE等。如果要使用SMOTE及其其他变体, 则可以如前所述检查scikit-learn-contrib模块。如果你想了解有关SMOTE的更多信息, 则应查阅本文档和本白皮书。
让我们继续本教程的最终方法。
尝试不同的观点:
有专门研究处理不平衡数据集的领域。他们有自己的算法, 度量和术语。
当你处理不平衡的数据时, 创造力和创新思维往往会为你提供新的观点。以下方法可以帮助你抢先一步:
成本敏感型学习:通常, 你可以使用正则化(如果你想了解有关正则化的更多信息, 可以查阅此srcmini文章)来惩罚通常出现在广义线性模型(GLM)中的大系数。尽管此应用程序因模型而异。你暂时仅考虑使用GLM。如果你可以设计出一种机制, 它会在每次分类错误时对分类器进行惩罚。这可以帮助分类器以更详细的方式学习假设。
以下是你应考虑的一些方法:
- 以正确的方式使用K折交叉验证
- 整合不同的重新采样数据集
- 用不同的比例重采样
- 聚班
包起来!
到目前为止, 你已经了解了不平衡数据的概念以及它在设计和开发机器学习模型时所产生的问题。你还看到了一些对于处理不平衡数据至关重要的原因。之后, 你研究了可以帮助你有效处理不平衡数据集的不同方法。处理不平衡的数据是研究的一个活跃领域, 它可以为你考虑新的研究问题开辟新的视野。
一口气处理了许多基本概念!非常精彩!
这就是本教程的全部内容。
如果你非常想研究不平衡数据这一主题, 那么下面是一些论文链接:
- 从不平衡数据中学习
- 解决不平衡训练集的诅咒:单方面选择
- 几种平衡机器学习训练数据方法的行为研究
参考文献:
- Analytics Vidhya关于不平衡数据的文章
- 走向有关不平衡数据的数据科学文章
- Python机器学习
如果你想了解有关数据可视化的更多信息, 请学习由Bokeh的开发人员之一的Bryan Van de Ven讲授的srcmini的”使用Bokeh进行交互式数据可视化”。
评论前必须登录!
注册