 srcmini
srcmini本文概述
大家都知道, 机器学习领域会随着时间的流逝越来越好。预测模型构成了机器学习的核心。模型的精度越高, 模型越好, 对特定问题的解决方案也越好。在本文中, 你将学习称为集成学习的知识, 这是一种有效的技术, 可以改善你的机器学习模型的性能。
在这篇文章中, 你将介绍:
- 什么是集成学习?
- 它如何提高机器学习模型的性能?
- 不同的集成学习方法
- 集成的陷阱
- 带有真实测试数据集的不同Ensemble学习方法的Pythonic实现
- 集成学习的进一步研究
因此, 让我们开始吧。
什么是集成学习?
在统计和机器学习领域, 集成学习技术试图通过提高预测模型的准确性来提高预测模型的性能。集成学习是一个过程, 通过该过程可以策略性地构建多个机器学习模型(例如分类器)以解决特定问题。
让我们以一个真实的例子来建立直觉。
假设你想投资一家公司XYZ。但是你不确定其性能。因此, 你需要寻求有关股价是否会以每年6%的速度增长的建议?你决定与具有不同领域经验的各种专家取得联系:
公司XYZ的员工:此人了解公司的内部功能, 并具有有关公司功能的内部信息。但是他对竞争对手如何创新, 技术如何发展以及这种发展对XYZ公司产品的影响缺乏更广阔的视野。过去, 他正确率是70%。
XYZ公司的财务顾问:此人对在这种竞争环境中公司战略如何公平具有更广阔的视野。但是, 他对公司内部政策的公平性缺乏看法。过去, 他正确率是75%。
股票市场交易员:此人观察了过去三年中公司的股价。他知道季节性趋势以及整个市场的表现。他还对股票如何随时间变化产生了敏锐的直觉。过去, 他正确率是70%。
竞争对手的雇员:此人了解竞争对手公司的内部功能, 并且知道有待进行的某些更改。他缺乏对公司的关注, 也没有将竞争对手的成长与主题公司联系起来的外部因素。过去, 他有60%的时间是正确的。
同一细分市场中的市场研究团队:该团队分析XYZ公司产品相对于其他产品的客户偏好, 以及随着时间的变化。因为他与客户方打交道, 所以他不知道XYZ公司会因实现自己的目标而带来的变化。在过去, 他们做对了75%。
社交媒体专家:此人可以帮助我们了解XYZ公司如何将其产品定位于市场。随着时间的流逝, 客户对公司的看法会如何变化?他不知道数字营销之外的任何细节。过去, 他正确率达65%。
鉴于你拥有广泛的访问权限, 你可能可以合并所有信息并做出明智的决定。
在六个专家/团队都确认这是一个正确决定的情况下(假设所有预测彼此独立), 你将获得1-(30%。25%。30%。40%)的组合准确率。 。25%。35%)= 1-0.07875 = 99.92125%
这里使用的所有预测都是完全独立的假设有些极端, 因为它们预计会相互关联。但是, 你可以通过将各种预测结合在一起来了解我们如何确定。
好吧, 集成学习也不例外。
集成是一种将各种学习者(个体模型)组合在一起以简化模型的稳定性和预测能力的艺术。在上面的示例中, 我们将所有预测共同组合的方式将称为集成学习。
而且, 基于Ensemble的模型可以结合在两种情况下, 即数据量大时和数据量太小时时。
现在, 让我们了解你如何实际获得不同的机器学习模型集。模型可能因各种原因而彼此不同:
- 数据总数可能有所不同。
- 可以使用不同的建模技术。
- 可能有不同的假设。
想象一下, 你在玩琐碎的追求。当你一个人玩耍时, 可能会有一些你擅长的主题, 而有些却几乎一无所知。如果我们想最大程度地提高琐碎的追求分数, 就需要建立一个涵盖所有主题的团队。这是集成的基本思想:将来自多个模型的预测组合起来可以平均出特质误差并产生更好的总体预测。
下图显示了集成的示例示意图。
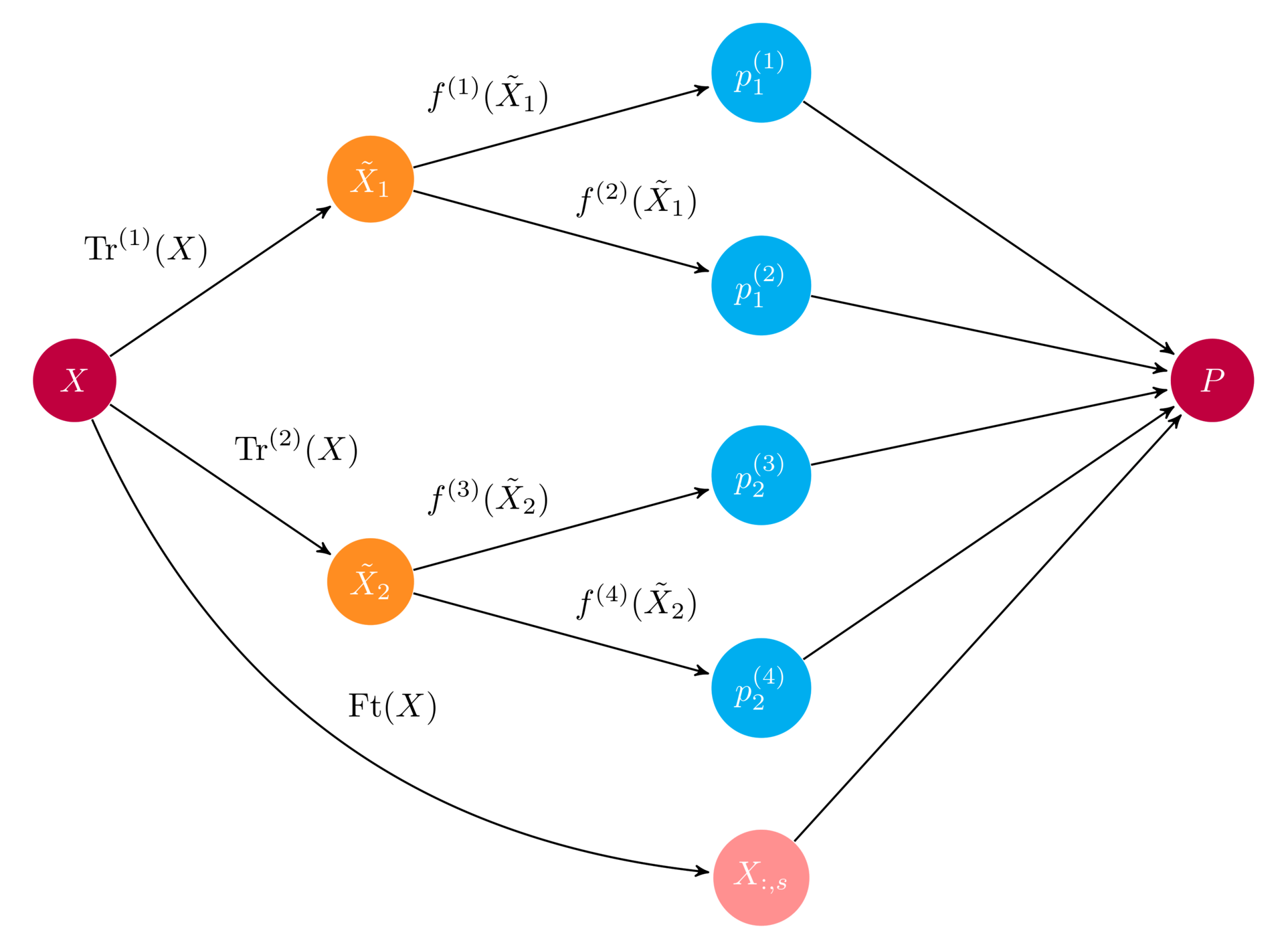
资源
在上图中, 输入数组X通过两个预处理流水线馈入, 然后馈送到一组基础学习器f(i)。集合将所有基本学习者预测合并到最终预测数组P中。
现在, 重要的问题是如何组合预测。在琐碎的追求示例中, 很容易想象团队成员可能会做出自己的决定, 而多数投票会决定选择哪一个。机器学习在分类问题上非常相似:采用最常见的类别标签预测等同于多数表决规则。但是还有许多其他组合预测的方法, 更一般而言, 你可以使用模型来学习如何最好地组合预测。
下图显示了基本的Ensemble结构:
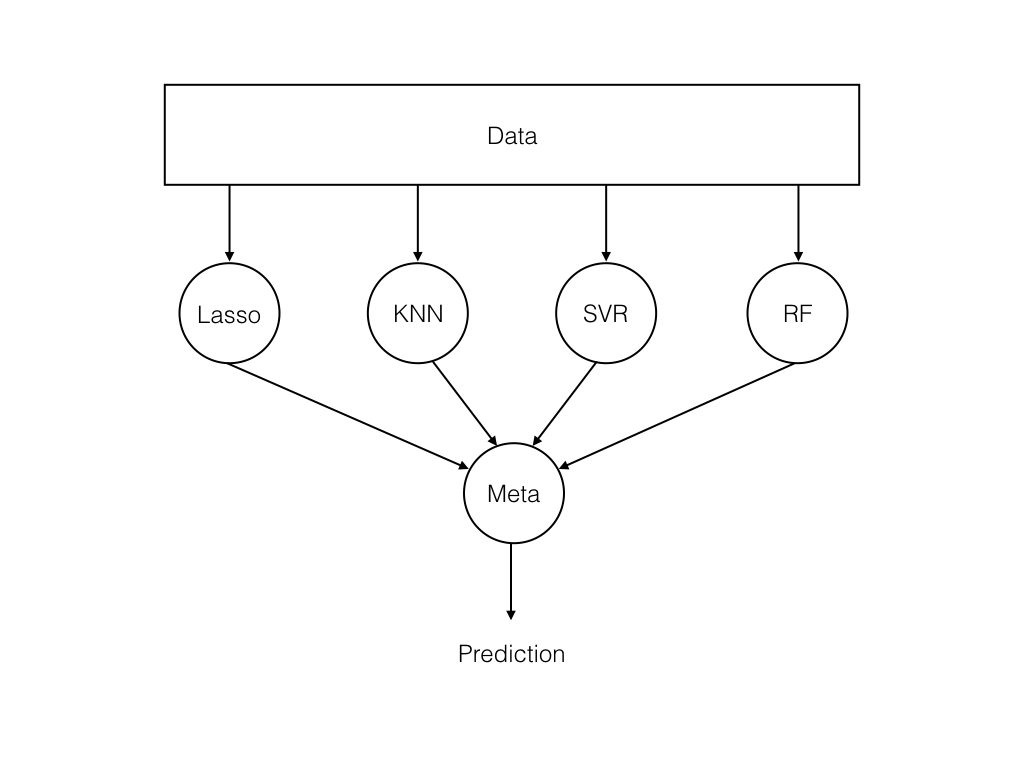
资源
在这里, 数据被馈送到一组模型, 而元学习者将模型预测结合起来。
使用集成进行模型错误并减少此错误
从任何机器模型产生的错误都可以在数学上分解为三个部分。以下是这些组件:
偏差+方差+不可减少的误差
为什么在当前情况下如此重要?要了解集成模型背后发生的情况, 你首先需要知道是什么导致了模型错误。你将简要介绍这些错误。
偏差误差有助于量化预测值与实际值的平均差异。高偏差误差意味着我们有一个表现不佳的模型, 该模型会不断遗漏基本趋势。
另一方面的方差量化了对同一观测值所做的预测彼此之间如何不同。高方差模型将过度适合你的训练人群, 并且在训练后的任何观察结果上均表现不佳。下图将使你更加清楚(假设红色斑点是真实值, 蓝色点是预测值):
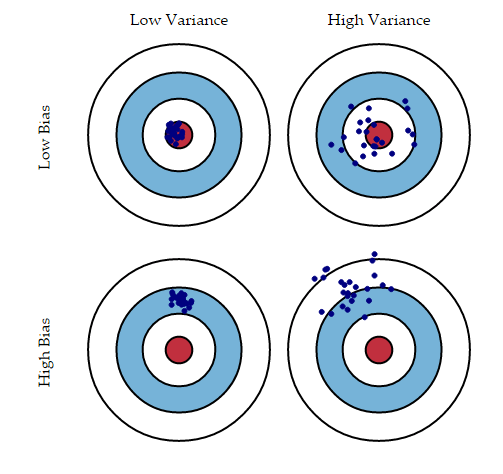
资源
通常, 随着你增加模型的复杂性, 由于模型中的偏差较小, 你会看到错误减少。但是, 这只会发生到特定的时刻。随着模型的不断复杂化, 最终会过度拟合模型, 因此模型将开始遭受高方差的困扰。
现在你已经熟悉了Ensemble学习的基础知识, 让我们看一下不同的Ensemble学习技术:
不同类型的集成学习方法
尽管有多种类型的Ensemble学习方法, 但以下三种是业内最常用的方法。
基于袋的Ensemble学习:
套袋是Ensemble的一种构建技术, 也称为Bootstrap聚合。 Bootstrap建立了Bagging技术的基础。 Bootstrap是一种采样技术, 其中我们从” n”个观测值中选择” n”个观测值。但是选择是完全随机的, 也就是说, 可以从原始总体中选择每个观察值, 以便在自举过程的每次迭代中均可以选择每个观察值。自举样本形成后, 将使用自举样本训练单独的模型。在实际实验中, 从训练集中提取自举样本, 然后使用测试集对子模型进行测试。最终的输出预测将跨所有子模型的投影进行组合。
以下信息图简要介绍了Bagging:
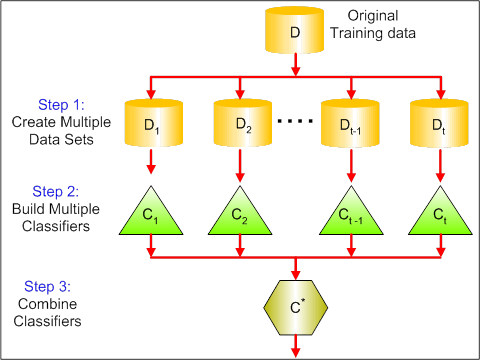
资源
基于促进的集成学习:
提升是顺序学习技术的一种形式。该算法通过使用整个训练集训练模型来工作, 然后通过拟合初始模型的残差值来构造后续模型。通过这种方式, Boosting尝试对那些先前模型估计不足的观测值赋予更高的权重。一旦创建了模型序列, 就可以通过模型的准确性得分对模型所做的预测进行加权, 然后将结果合并以创建最终估计。 Boosting技术中通常使用的模型是XGBoost(极端梯度增强), GBM(梯度增强机), ADABoost(自适应增强)等。
基于投票的集成学习:
投票是最直接的Ensemble学习技术之一, 其中结合了来自多个模型的预测。该方法首先使用相同的数据集创建两个或多个单独的模型。然后, 可以使用基于投票的Ensemble模型包装先前的模型并汇总这些模型的预测。构建基于投票的Ensemble模型后, 可以将其用于对新数据进行预测。可以为子模型做出的预测分配权重。堆叠聚合是一种可以用来学习如何以最佳方式权衡这些预测的技术。
以下信息图最恰当地描述了基于投票的集成:
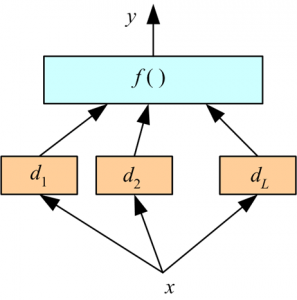
资源
好了, 现在是时候应用这些概念来增强直觉和信心了。让我们在Python中进行操作。
Python案例研究
你将用于此案例研究的数据集被普遍称为威斯康星州乳腺癌数据集。与之相关的任务是分类。
数据集包含以良性或恶性类标记的10个特征总数。这些要素有699个实例, 其中缺少16个要素值。数据集仅包含数值。
数据集可从此处下载。
你将使用强大的scikit-learn库实现集成。
首先, 导入此案例研究所需的所有Python依赖项。
import pandas as pd
import numpy as np
from sklearn.preprocessing import Imputer
from sklearn.preprocessing import MinMaxScaler
让我们将数据集加载到DataFrame对象中。
data = pd.read_csv('cancer.csv')
data.head()

“样本代码编号”列只是一个指标, 在建模中没有用。因此, 让我们删除它:
data.drop(['Sample code number'], axis = 1, inplace = True)
data.head()

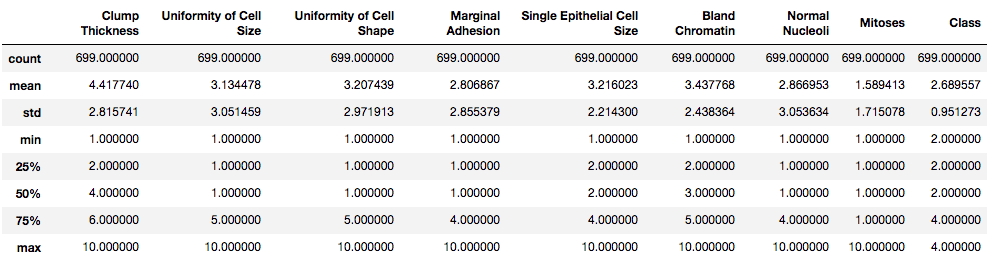
你可以看到该列现在已删除。让我们使用Panda的describe()和info()函数获取有关数据的一些统计信息:
data.describe()
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 699 entries, 0 to 698
Data columns (total 10 columns):
Clump Thickness 699 non-null int64
Uniformity of Cell Size 699 non-null int64
Uniformity of Cell Shape 699 non-null int64
Marginal Adhesion 699 non-null int64
Single Epithelial Cell Size 699 non-null int64
Bare Nuclei 699 non-null object
Bland Chromatin 699 non-null int64
Normal Nucleoli 699 non-null int64
Mitoses 699 non-null int64
Class 699 non-null int64
dtypes: int64(9), object(1)
memory usage: 54.7+ KB
如前所述, 数据集包含缺失值。名为”裸核”的列包含它们。让我们验证一下。
data['Bare Nuclei']
0 1
1 10
2 2
3 4
4 1
5 10
6 10
7 1
8 1
9 1
10 1
11 1
12 3
13 3
14 9
15 1
16 1
17 1
18 10
19 1
20 10
21 7
22 1
23 ?
24 1
25 7
26 1
27 1
28 1
29 1
..
669 5
670 8
671 1
672 1
673 1
674 1
675 1
676 1
677 1
678 1
679 1
680 10
681 10
682 1
683 1
684 1
685 1
686 1
687 1
688 1
689 1
690 1
691 5
692 1
693 1
694 2
695 1
696 3
697 4
698 5
Name: Bare Nuclei, dtype: object
你可以在其中找到一些”?”, 对吗?好吧, 这些是你缺失的值, 你将使用均值插补来插补它们。但是首先, 你将用0代替那些”?”。
data.replace('?', 0, inplace=True)
data['Bare Nuclei']
0 1
1 10
2 2
3 4
4 1
5 10
6 10
7 1
8 1
9 1
10 1
11 1
12 3
13 3
14 9
15 1
16 1
17 1
18 10
19 1
20 10
21 7
22 1
23 0
24 1
25 7
26 1
27 1
28 1
29 1
..
669 5
670 8
671 1
672 1
673 1
674 1
675 1
676 1
677 1
678 1
679 1
680 10
681 10
682 1
683 1
684 1
685 1
686 1
687 1
688 1
689 1
690 1
691 5
692 1
693 1
694 2
695 1
696 3
697 4
698 5
Name: Bare Nuclei, dtype: object
现在将”?”替换为0。让我们现在做缺失值处理。
# Convert the DataFrame object into NumPy array otherwise you will not be able to impute
values = data.values
# Now impute it
imputer = Imputer()
imputedData = imputer.fit_transform(values)
现在, 如果你看一下数据集本身, 你将看到该数据集的所有要素范围都不相同。这可能会引起问题。功能的微小变化可能不会影响其他功能。要解决此问题, 你可以将要素范围标准化为统一范围, 在这种情况下为0-1。
scaler = MinMaxScaler(feature_range=(0, 1))
normalizedData = scaler.fit_transform(imputedData)
精彩!
你已经执行了进行集成实验所需的所有预处理。
你将从基于袋装的集成开始。在这种情况下, 你将使用袋装决策树。
# Bagged Decision Trees for Classification - necessary dependencies
from sklearn import model_selection
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
你已经导入了袋装决策树的依赖项。
# Segregate the features from the labels
X = normalizedData[:, 0:9]
Y = normalizedData[:, 9]
kfold = model_selection.KFold(n_splits=10, random_state=7)
cart = DecisionTreeClassifier()
num_trees = 100
model = BaggingClassifier(base_estimator=cart, n_estimators=num_trees, random_state=7)
results = model_selection.cross_val_score(model, X, Y, cv=kfold)
print(results.mean())
0.9571428571428573
让我们看看你在上面的单元格中做了什么。
首先, 你初始化了10倍交叉验证折叠。之后, 你实例化了具有100棵树的决策树分类器, 并将其包装在基于Bagging的集成中。然后, 你评估了模型。
你的模型表现很好。产生的准确性为95.71%。
辉煌!让我们实现其他的。
(如果你想快速了解交叉验证, 则可以使用此链接。)
# AdaBoost Classification
from sklearn.ensemble import AdaBoostClassifier
seed = 7
num_trees = 70
kfold = model_selection.KFold(n_splits=10, random_state=seed)
model = AdaBoostClassifier(n_estimators=num_trees, random_state=seed)
results = model_selection.cross_val_score(model, X, Y, cv=kfold)
print(results.mean())
0.9557142857142857
在这种情况下, 你基于AmbBoost的Ensembling类型进行了分类(有70棵树)。该模型为你提供10倍交叉验证的95.57%的准确性。
最后, 是时候实施基于投票的Ensemble技术了。
# Voting Ensemble for Classification
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.ensemble import VotingClassifier
kfold = model_selection.KFold(n_splits=10, random_state=seed)
# create the sub models
estimators = []
model1 = LogisticRegression()
estimators.append(('logistic', model1))
model2 = DecisionTreeClassifier()
estimators.append(('cart', model2))
model3 = SVC()
estimators.append(('svm', model3))
# create the ensemble model
ensemble = VotingClassifier(estimators)
results = model_selection.cross_val_score(ensemble, X, Y, cv=kfold)
print(results.mean())
0.9642857142857142
你实现了基于投票的集成模型, 在其中采用了Logistic回归, 决策树和支持向量机进行投票。该模型迄今为止表现最好, 十次交叉验证的准确率为96.42%。
现在, 让你熟悉Ensemble学习的一些常见陷阱。
集成学习的陷阱
通常, 它总是会表现得更好并不是正确的。有几种集成方法, 每种方法都有其自身的优点/缺点。使用哪个, 然后取决于当前的问题。
例如, 如果你的模型具有较高的方差(它们过度拟合了数据), 那么你可能会受益于使用装袋。如果你对模型有偏见, 最好将它们与Boosting结合使用。也有不同的策略来形成集成。该主题范围太广, 无法一一回答。
但是关键是:如果你对设置使用了错误的集成方法, 你将不会做得更好。例如, 将Bagging与偏差模型结合使用将无济于事。
另外, 如果你需要在概率环境中工作, 则集成方法也可能不起作用。众所周知, Boosting(以AdaBoost等最流行的形式)提供的概率估计很差。也就是说, 如果你想要一个模型, 使你不仅可以对数据进行分类, 还可以对数据进行推理, 那么使用图形模型可能会更好。
因此, 在本文中, 你对Ensemble学习技术进行了介绍。你介绍了它的基础知识, 以及它如何提高模型的性能。你介绍了它的三种主要类型。
另外, 你在scikit-learn的帮助下在Python中实现了这三种类型, 并且在此过程中, 你对必要的预处理步骤有了一些了解。
真是壮举!做得好!在最后一节中, 我建议你进一步考虑对乐团进行的一些尝试。
更进一步
- 尝试其他基于Boosting的Ensemble技术。梯度提升, XGBoost等
- 尝试使用scikit-learn在集成中提供的不同参数设置, 然后尝试找出为什么特定设置表现良好的原因。这将使你的理解更加牢固。链接
- 尝试对各种数据集进行Ensemble学习, 以了解应在何处和不应该在何处应用Ensemble学习。对于查找数据集, Kaggle, UCI存储库等是搜索的好地方。
我在编写本教程时使用的一些参考资料:
- 流行集成方法的实证研究
- 集成方法, KDNuggets博客
希望你喜欢本教程。在评论部分中, 让我知道你的疑问(如果有的话)。
如果你有兴趣了解有关Ensemble的机器学习的更多信息, 请参加srcmini的Python与树型模型机器学习课程。
评论前必须登录!
注册