 srcmini
srcmini本文学习市场篮子分析及其背后的APRIORI算法。你将看到它是如何通过预测顾客一起购买的物品来帮助零售商促进业务的。
你是一名数据科学家(或即将成为一名科学家), 并且你获得了一家经营零售商店的客户。你的客户会为你提供所有交易的数据, 这些数据包括一段时间内几位客户在商店中购买的商品, 并要求你使用该数据来促进他们的业务。你的客户不仅可以使用你的发现来更改/更新/添加库存中的项目, 还可以使用它们来更改实体店或在线商店的布局。为了找到对你的客户有用的结果, 你将使用市场篮分析(MBA), 该篮对给定的交易数据使用关联规则挖掘。
在本教程中, 你将学习:
- 什么是关联规则挖掘和应用
- 什么是APRIORI算法?
- 如何使用带有可视化的R实现MBA /关联规则挖掘?
关联规则挖掘
当你要查找集合中不同对象之间的关联, 在事务数据库, 关系数据库或任何其他信息存储库中查找频繁的模式时, 可以使用关联规则挖掘。关联规则挖掘的应用可以在零售, 聚类和分类的市场营销, 购物篮数据分析(或市场购物篮分析)中找到。通过生成一组称为关联规则的规则, 它可以告诉你客户经常一起购买哪些商品。简而言之, 它以规则的形式为你提供输出(如果这样做的话)。客户可以将这些规则用于多种营销策略:
- 根据趋势更改商店布局
- 客户行为分析
- 目录设计
- 在线商店的交叉营销
- 客户购买哪些热门商品
- 带有附加销售的定制电子邮件
考虑以下示例:
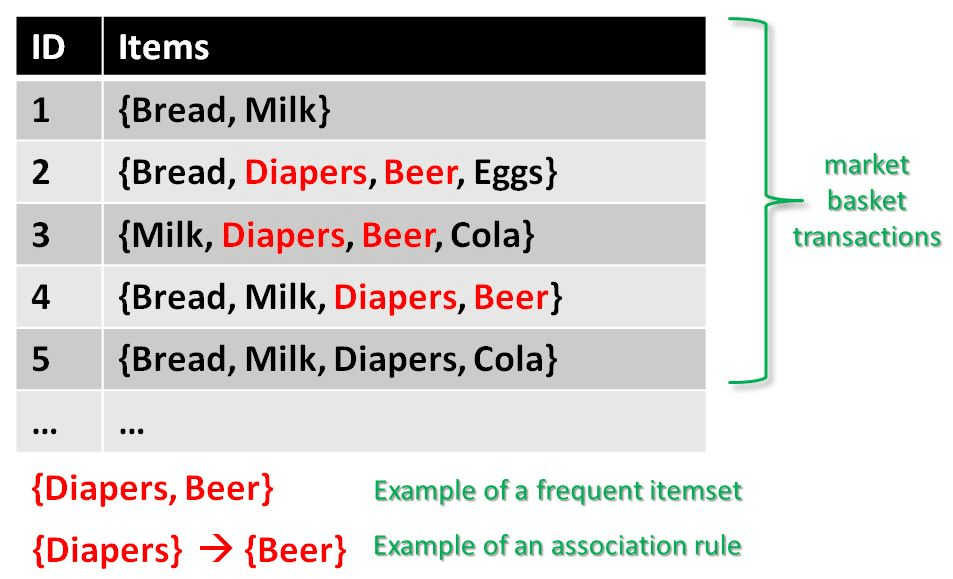
给定的是一组交易数据。你可以看到编号为1到5的交易。每个交易都显示该交易中购买的商品。你会看到尿布是在三笔交易中与啤酒一起购买的。同样, 面包是在三笔交易中用牛奶购买的, 因此它们都是频繁的商品集。关联规则的形式如下:
$ A => B [Support, Confidence] $
$ => $之前的部分称为if(前提), 而$ => $之后的部分称为then(后续)。
其中A和B是交易数据中的项目集。 A和B是不相交的集合。
$ Computer => Anti-virus Software [Support = 20 \%, confidence = 60 \%] $
上面的规则说:
- 20%的交易表明, 购买计算机后购买了防病毒软件
- 购买防病毒软件的客户中有60%是通过购买计算机来购买的
在以下部分中, 你将学习关联规则挖掘的基本概念:
关联规则挖掘的基本概念
- 项目集:一个或多个项目的集合。 K个项目集是指一组k个项目。
- 支持计数:项目集出现的频率
支持(一个或多个):包含项目集” X”的交易分数
$ Support(X)= \ frac {frequency(X)} {N} $
对于规则A => B, 支持如下:
$ Support(A => B)= \ frac {frequency(A, B)} {N} $
注意:P(AUB)是A和B一起出现的概率。 P表示概率。
继续, 尝试找到对Milk => Diaper的支持作为练习。
- 置信度(c):对于规则A => B, 置信度显示与A一起购买B的百分比。
$ Confidence(A => B)= \ frac {P(A \ cap B)} {P(A)} = \ frac {frequency(A, B)} {frequency(A)} $
具有A和B的事务数除以具有A的事务总数。
$ Confidence(面包=>牛奶)= \ frac {3} {4} = 0.75 = 75 \%$
现在找到对Milk => Diaper的信心。
注意:支持和信心可以衡量规则的有趣程度。它由最小支持和最小置信度阈值设置。客户设置的这些阈值有助于根据你自己或客户的意愿比较规则强度。越接近阈值, 规则对客户端使用的越多。
- 频繁项目集:支持大于或等于最小支持阈值(min_sup)的项目集。在上面的示例中, min_sup = 3。这是根据用户选择设置的。
- 强规则:如果规则A => B [Support, Confidence]满足min_sup和min_confidence, 则它是强规则。
- 提升:提升在规则A => B中给出A和B之间的相关性。相关性显示一个项目集A如何影响项目集B。
$ Lift(A => B)= \ frac {Support} {Supp(A)Supp(B)} $
例如, 规则{面包} => {牛奶}提升量计算为:
$ support(面包)= \ frac {4} {5} = 0.8 $
$ support(牛奶)= \ frac {4} {5} = 0.8 $
$ Lift(面包=>牛奶)= \ frac {0.6} {0.8 * 0.8} = 0.9 $
- 如果规则的提升为1, 则A和B是独立的, 因此无法从中得出任何规则。
- 如果提升> 1, 则A和B相互依赖, 其程度由ift值给出。
- 如果提升<1, 则A的存在会对B产生负面影响。
关联规则挖掘的目标
当你对给定的一组交易应用关联规则挖掘时, 你的目标将是找到具有以下各项的所有规则:
- 支持大于或等于min_support
- 置信度大于或等于min_confidence
APRIORI算法
在本教程的这一部分中, 你将了解将在R库后面进行市场篮子分析的算法。这将帮助你更多地了解客户, 并进行更多关注的分析。如果你已经了解APRIORI算法及其工作原理, 则可以进入编码部分。
关联规则挖掘被视为分两个步骤:
- 频繁项目集生成:查找支持> =预定min_support计数的所有频繁项目集
- 规则生成:列出频繁项目集中的所有关联规则。计算所有规则的支持和信心。修剪未达到min_support和min_confidence阈值的规则。
频繁项集生成是计算上最昂贵的步骤, 因为它需要完整的数据库扫描。
在上述步骤中, 就计算而言, 频繁项集生成是最昂贵的。
上面你仅看到了5个交易的示例, 但是在现实世界中, 零售交易数据可能超过GB或TB的数据, 因此需要一种优化算法来修剪项目集, 而这些数据集在以后的步骤中将无济于事。为此, 使用了APRIORI算法。它指出:
频繁项目集的任何子集也必须是频繁的。换句话说, 不需要生成或测试不频繁项集的超集
它用Itemset Lattice表示, 它是APRIORI算法原理的图形表示。它由k个项目集节点和该k个项目集的子集的关系组成。
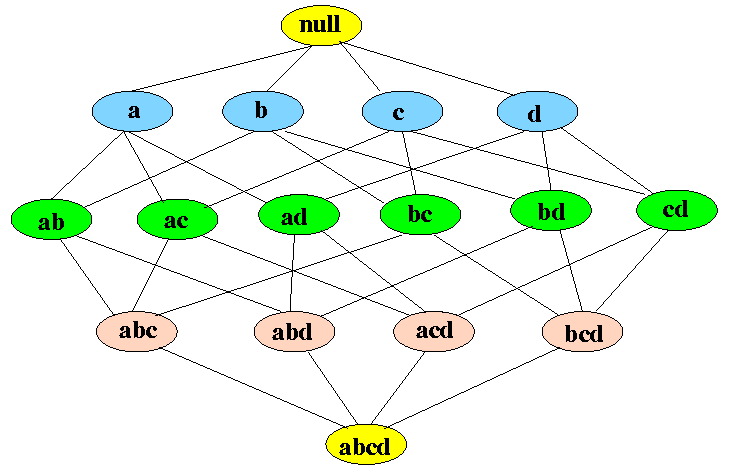
你可以在上图中看到, 底部是交易数据中的所有项目, 然后开始向上移动创建子集, 直到设置为空集为止。对于d个项目, 点阵的大小将变为$ 2 ^ d $。这表明通过为每种组合找到支持来生成”频繁项目集”将是多么困难。下图显示了APRIORI在减少生成集的数量方面有多少帮助:
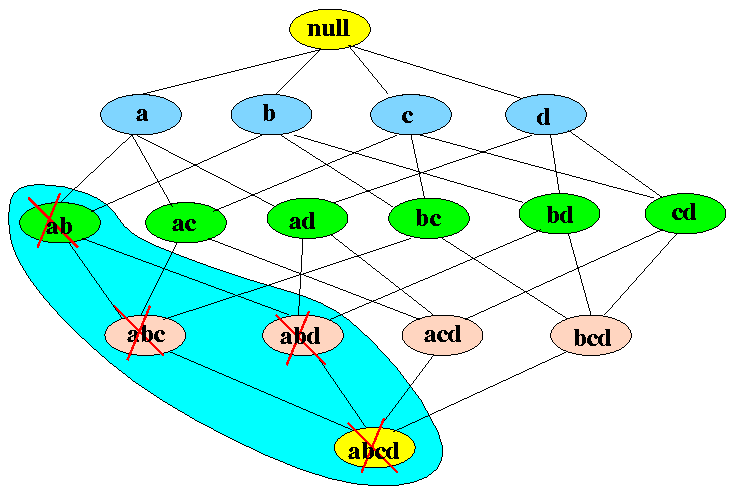
如果项目集{a, b}很少出现, 则我们无需考虑其所有超级集。
让我们通过一个例子来理解这一点。在下面的示例中, 你将看到APRIORI为什么是有效的算法并逐步生成强大的关联规则的原因。继续使用笔记本和笔!
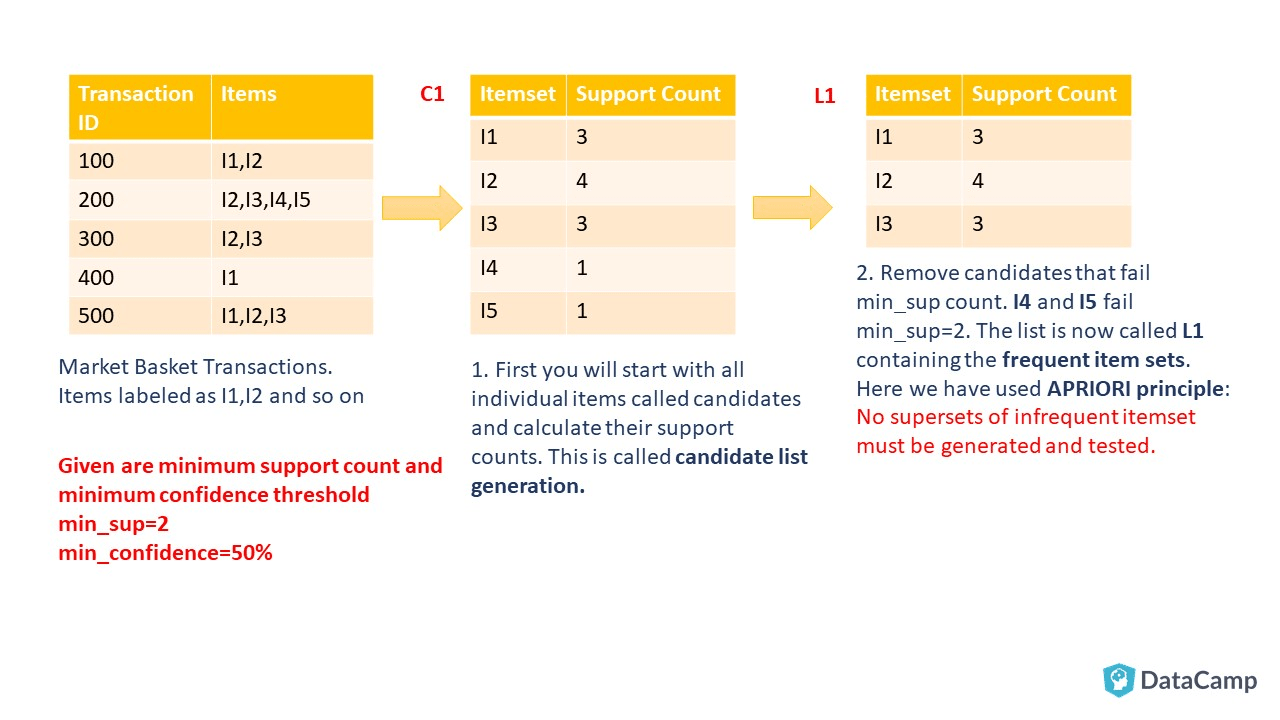
如你所见, 首先为1个项目集创建候选清单, 该清单将单独包括交易数据中存在的所有项目。考虑到来自现实世界的零售交易数据, 你可以看到此候选代的价格是多少。在这里, APRIORI发挥了作用, 并帮助减少了候选列表的数量, 最后生成了有用的规则。在接下来的步骤中, 你将看到我们如何达到频繁项集生成的结尾, 这是关联规则挖掘的第一步。
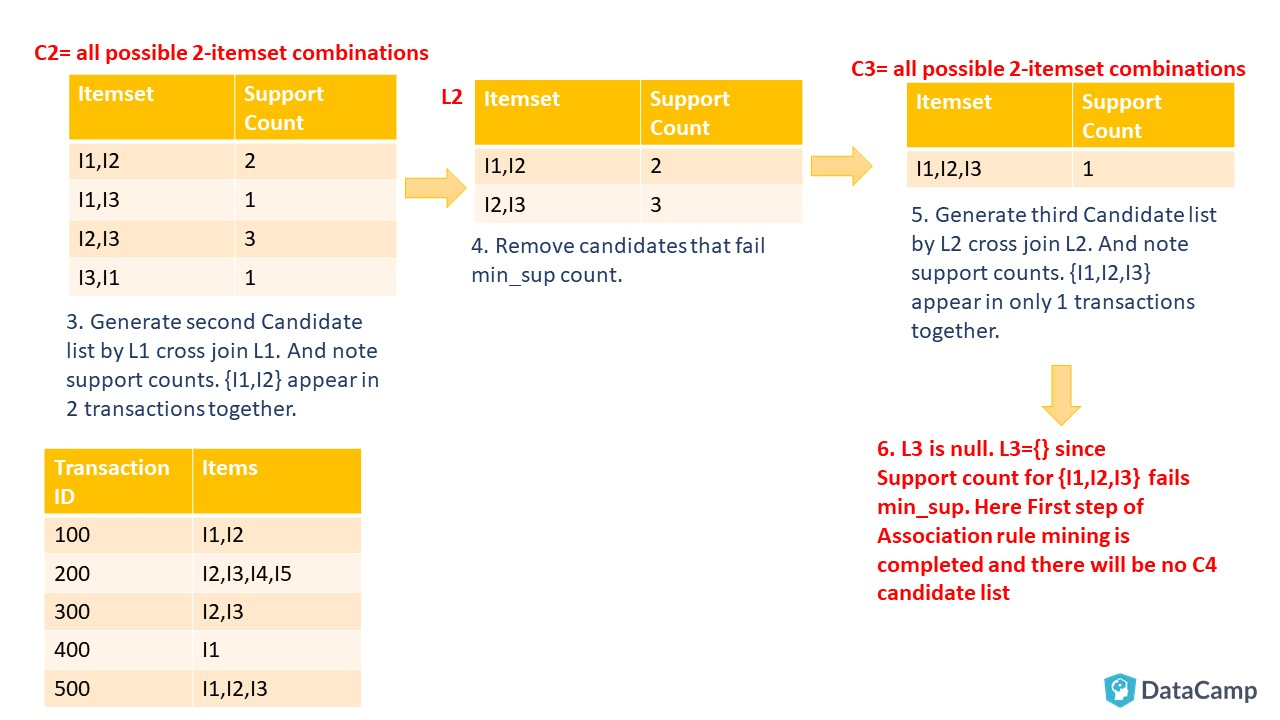
下一步将列出所有常用项目集。你将获取最后一个非空的频繁项目集, 在本示例中为L2 = {I1, I2}, {I2, I3}。然后, 使该频繁项集列表中存在该项集的所有非空子集。遵循下图所示:
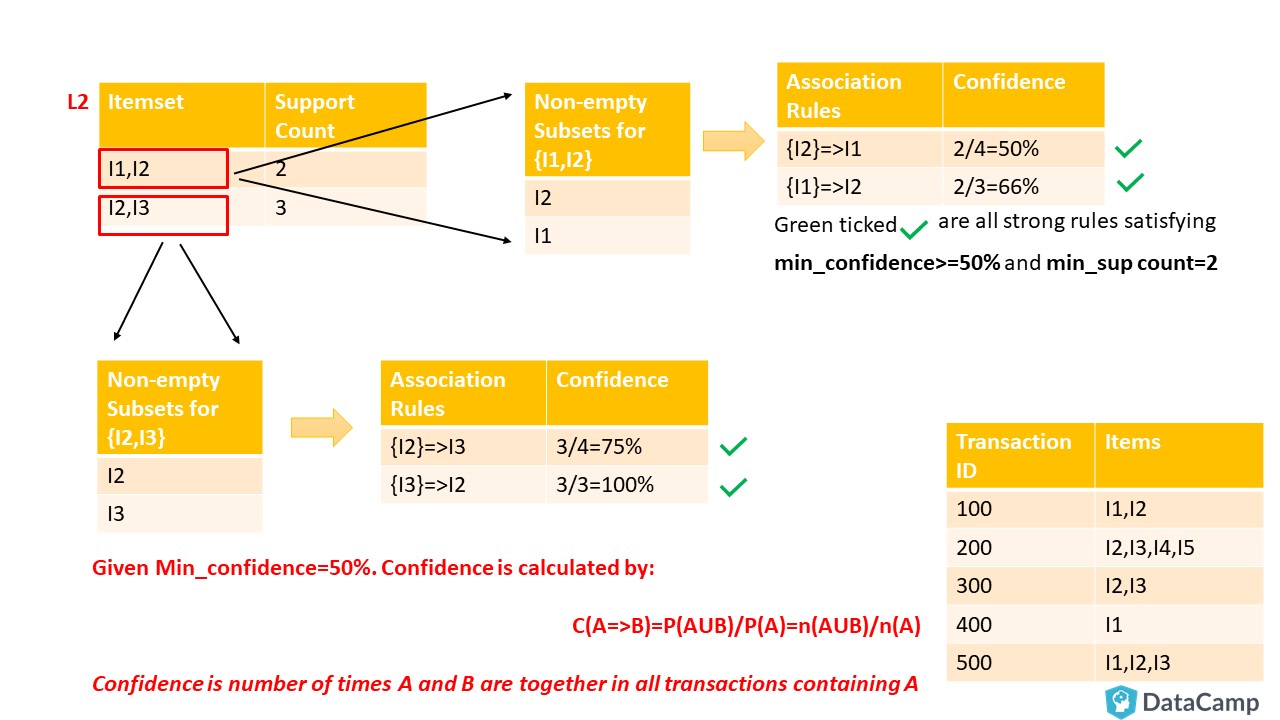
你可以在上方看到四个严格的规则。例如, 假设$ {I2} => I3 $的置信度等于75%, 则表明购买I2的人中有75%也购买了I3。
你现在已经了解了完整的APRIORI算法, 它是数据挖掘中最常用的算法之一。让我们进入代码phewww!
使用R实施MBA /关联规则挖掘
在本教程中, 你将使用UCI机器学习存储库中的数据集。该数据集称为”在线零售”, 你可以从此处下载。数据集包含2010年1月12日至2011年12月9日在英国注册的非商店在线零售的交易数据。使用此数据集而不使用R数据集的原因是, 你更有可能以这种形式接收零售数据, 因此必须对其应用数据预处理。
数据集说明
- 行数:541909
- 属性数量:08
属性信息
- 发票编号:发票编号。标称, 唯一分配给每个交易的6位整数。如果此代码以字母” c”开头, 则表示已取消。 + StockCode:产品(项目)代码。标称, 唯一分配给每个不同产品的5位整数。
- 描述:产品(项目)名称。名义上
- 数量:每笔交易中每个产品(项目)的数量。数字。
- InvoiceDate:发票日期和时间。数字, 每笔交易生成的日期和时间。数据集示例:2010年12月1日8:26
- 单价:单价。数值, 单位为英镑的产品价格。
- 客户编号:客户编号。标称, 唯一分配给每个客户的5位整数。
- 国家:国家名称。名义, 每个客户居住的国家/地区的名称。
加载库
首先, 你将加载所需的库。下表简要描述了这些库(从此处获取), 因此你知道每个库的作用:
| 包 | 描述 |
|---|---|
| 规则 | 提供用于表示, 处理和分析交易数据和模式(频繁项目集和关联规则)的基础结构。 |
| arulesViz | 使用各种可视化技术扩展包装” arules”, 以用于关联规则和项目集。该软件包还包括用于规则浏览的多个交互式可视化文件。 |
| tidyverse | tidyverse是为数据科学设计的R软件包的自以为是的集合 |
| 读xl | 在R中读取Excel文件 |
| 面粉 | 拆分, 应用和合并数据的工具 |
| ggplot2 | 创建图形和图表 |
| 针织衫 | R中的动态报告生成 |
| 润滑 | Lubridate是一个R软件包, 可以更轻松地处理日期和时间。 |
#install and load package arules
#install.packages("arules")
library(arules)
#install and load arulesViz
#install.packages("arulesViz")
library(arulesViz)
#install and load tidyverse
#install.packages("tidyverse")
library(tidyverse)
#install and load readxml
#install.packages("readxml")
library(readxl)
#install and load knitr
#install.packages("knitr")
library(knitr)
#load ggplot2 as it comes in tidyverse
library(ggplot2)
#install and load lubridate
#install.packages("lubridate")
library(lubridate)
#install and load plyr
#install.packages("plyr")
library(plyr)
library(dplyr)
数据预处理
使用read_excel(文件路径)将数据集从下载的文件读取到R中。在read_excel中提供文件的完整路径, 包括文件名(path-to-file-with-filename)
#read excel into R dataframe
retail <- read_excel('D:/Documents/Online_Retail.xlsx')
#complete.cases(data) will return a logical vector indicating which rows have no missing values. Then use the vector to get only rows that are complete using retail[, ].
retail <- retail[complete.cases(retail), ]
#mutate function is from dplyr package. It is used to edit or add new columns to dataframe. Here Description column is being converted to factor column. as.factor converts column to factor column. %>% is an operator with which you may pipe values to another function or expression
retail %>% mutate(Description = as.factor(Description))
retail %>% mutate(Country = as.factor(Country))
#Converts character data to date. Store InvoiceDate as date in new variable
retail$Date <- as.Date(retail$InvoiceDate)
#Extract time from InvoiceDate and store in another variable
TransTime<- format(retail$InvoiceDate, "%H:%M:%S")
#Convert and edit InvoiceNo into numeric
InvoiceNo <- as.numeric(as.character(retail$InvoiceNo))
NAs introduced by coercion
#Bind new columns TransTime and InvoiceNo into dataframe retail
cbind(retail, TransTime)
cbind(retail, InvoiceNo)
#get a glimpse of your data
glimpse(retail)
注意:第1页, 共100页。
Observations: 406, 829
Variables: 9
$ InvoiceNo <chr> "536365", "536365", "536365", "536365", "536365", "536365", "53...
$ StockCode <chr> "85123A", "71053", "84406B", "84029G", "84029E", "22752", "2173...
$ Description <chr> "WHITE HANGING HEART T-LIGHT HOLDER", "WHITE METAL LANTERN", "C...
$ Quantity <dbl> 6, 6, 8, 6, 6, 2, 6, 6, 6, 32, 6, 6, 8, 6, 6, 3, 2, 3, 3, 4, 4, ...
$ InvoiceDate <dttm> 2010-12-01 08:26:00, 2010-12-01 08:26:00, 2010-12-01 08:26:00, ...
$ UnitPrice <dbl> 2.55, 3.39, 2.75, 3.39, 3.39, 7.65, 4.25, 1.85, 1.85, 1.69, 2.1...
$ CustomerID <dbl> 17850, 17850, 17850, 17850, 17850, 17850, 17850, 17850, 17850, ...
$ Country <chr> "United Kingdom", "United Kingdom", "United Kingdom", "United K...
$ Date <date> 2010-12-01, 2010-12-01, 2010-12-01, 2010-12-01, 2010-12-01, 20...
现在, 数据框零售将包含10个属性, 以及两个附加属性Date和Time。
在应用MBA /关联规则挖掘之前, 我们需要将数据框转换为交易数据, 以使在一张发票中一起购买的所有物品都排成一行。你可以在瞥见的输出中看到, 每个事务都是原子形式的, 也就是说, 与关系数据库中一样, 属于一张发票的所有产品都是原子的。此格式也称为单打格式。
你需要做的是根据客户ID, 客户ID和日期对零售数据框中的数据进行分组, 或者也可以使用InvoiceNo和Date对数据进行分组。我们需要这种分组并对其应用一个函数, 并将输出存储在另一个数据帧中。可以通过ddply完成。
以下代码行将合并一个InvoiceNo和日期的所有产品, 并将该InvoiceNo和日期的所有产品合并为一行, 每个项目之间用,
library(plyr)
#ddply(dataframe, variables_to_be_used_to_split_data_frame, function_to_be_applied)
transactionData <- ddply(retail, c("InvoiceNo", "Date"), function(df1)paste(df1$Description, collapse = ", "))
#The R function paste() concatenates vectors to character and separated results using collapse=[any optional charcater string ]. Here ', ' is used
transactionData
注意:第1页, 共100页。
接下来, 由于InvoiceNo和Date在规则挖掘中将没有任何用处, 因此你可以将它们设置为NULL。
#set column InvoiceNo of dataframe transactionData
transactionData$InvoiceNo <- NULL
#set column Date of dataframe transactionData
transactionData$Date <- NULL
#Rename column to items
colnames(transactionData) <- c("items")
#Show Dataframe transactionData
transactionData
注意:第1页, 共100页。
交易数据的这种格式称为篮子格式。接下来, 你必须将此交易数据存储到.csv(逗号分隔值)文件中。为此, 请write.csv()
write.csv(transactionData, "D:/Documents/market_basket_transactions.csv", quote = FALSE, row.names = FALSE)
#transactionData: Data to be written
#"D:/Documents/market_basket.csv": location of file with file name to be written to
#quote: If TRUE it will surround character or factor column with double quotes. If FALSE nothing will be quoted
#row.names: either a logical value indicating whether the row names of x are to be written along with x, or a character vector of row names to be written.
查看你的交易数据格式是否正确:

接下来, 你必须将此交易数据加载到交易类的对象中。这是通过使用arules包的R函数read.transactions完成的。
以下代码行将采用篮子格式的交易数据文件D:/Documents/market_basket_transactions.csv并将其转换为交易类的对象。
tr <- read.transactions('D:/Documents/market_basket_transactions.csv', format = 'basket', sep=', ')
#sep tell how items are separated. In this case you have separated using ', '
当你运行上述代码行时, 输出中的带引号的字符串中可能会包含很多EOF, 请不要担心。
如果数据帧中已经有交易数据, 请使用以下代码行将其转换为交易对象:
`trObj<-as(dataframe.dat, "transactions")`
查看tr事务对象:
tr
transactions in sparse format with
22191 transactions (rows) and
30066 items (columns)
summary(tr)
transactions in sparse format with
22191 transactions (rows) and
7876 items (columns)
transactions as itemMatrix in sparse format with
22191 rows (elements/itemsets/transactions) and
7876 columns (items) and a density of 0.001930725
most frequent items:
WHITE HANGING HEART T-LIGHT HOLDER REGENCY CAKESTAND 3 TIER
1803 1709
JUMBO BAG RED RETROSPOT PARTY BUNTING
1460 1285
ASSORTED COLOUR BIRD ORNAMENT (Other)
1250 329938
element (itemset/transaction) length distribution:
sizes
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
3598 1594 1141 908 861 758 696 676 663 593 624 537 516 531 551 522 464
18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34
441 483 419 395 315 306 272 238 253 229 213 222 215 170 159 138 142
35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51
134 109 111 90 113 94 93 87 88 65 63 67 63 60 59 49 64
52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68
40 41 49 43 36 29 39 30 27 28 17 25 25 20 27 24 22
69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85
15 20 19 13 16 16 11 15 12 7 9 14 15 12 8 9 11
86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102
11 14 8 6 5 6 11 6 4 4 3 6 5 2 4 2 4
103 104 105 106 107 108 109 110 111 112 113 114 116 117 118 120 121
4 3 2 2 6 3 4 3 2 1 3 1 3 3 3 1 2
122 123 125 126 127 131 132 133 134 140 141 142 143 145 146 147 150
2 1 3 2 2 1 1 2 1 1 2 2 1 1 2 1 1
154 157 168 171 177 178 180 202 204 228 236 249 250 285 320 400 419
3 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.00 3.00 10.00 15.21 21.00 419.00
includes extended item information - examples:
labels
1 1 HANGER
2 10 COLOUR SPACEBOY PEN
3 12 COLOURED PARTY BALLOONS
summary(tr)是非常有用的命令, 可为我们提供有关交易对象的信息。让我们看一下上面的输出内容:
- 有22191个事务(行)和7876个项目(列)。注意, 7876是数据集中涉及的产品描述, 22191交易是这些项目的集合。
- 密度表示稀疏矩阵中非零像元的百分比。你可以说是购买的商品总数除以该矩阵中的可能商品数。你可以使用密度计算购买了多少物品:22191x7876x0.001930725 = 337445
信息!稀疏矩阵:稀疏矩阵或稀疏数组是其中大多数元素为零的矩阵。相反, 如果大多数元素都不为零, 则矩阵被认为是密集的。零值元素的数量除以元素的总数称为矩阵的稀疏度(等于1减去矩阵的密度)。
- 摘要还可以告诉你最常出现的项目。
- 元素(项目集/事务)长度分布:告诉你1项目集, 2项目集等的事务数。第一行告诉你一些项目, 第二行告诉你交易的数量。
例如, 一项只有3598笔交易, 两项只有1594笔交易, 而一笔交易中有419笔交易最长。
你可以生成itemFrequencyPlot来创建项目频率条形图, 以查看基于itemMatrix的对象分布(例如, >交易或>项目集和>规则中的项目)。
# Create an item frequency plot for the top 20 items
if (!require("RColorBrewer")) {
# install color package of R
install.packages("RColorBrewer")
#include library RColorBrewer
library(RColorBrewer)
}
itemFrequencyPlot(tr, topN=20, type="absolute", col=brewer.pal(8, 'Pastel2'), main="Absolute Item Frequency Plot")
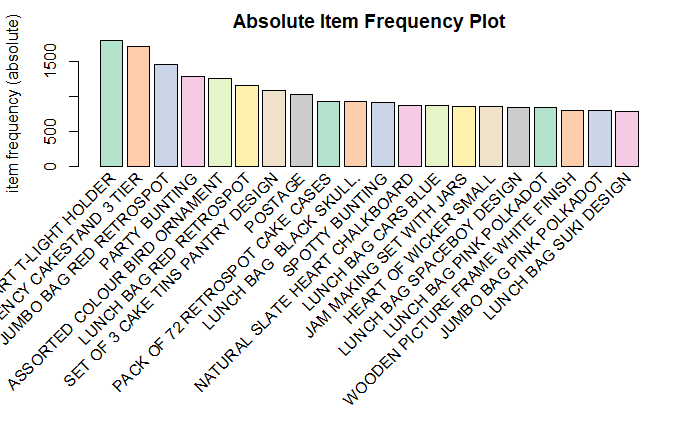
在itemFrequencyPlot(tr, topN = 20, type =” absolute”)中, 第一个参数是要绘制的事务对象tr。 topN允许你绘制前N个频率最高的项目。 type可以是type =” absolute”或type =” relative”。如果是绝对值, 它将独立绘制每个项目的数字频率。如果是相对的, 它将绘制这些项目与其他项目相比出现了多少次。
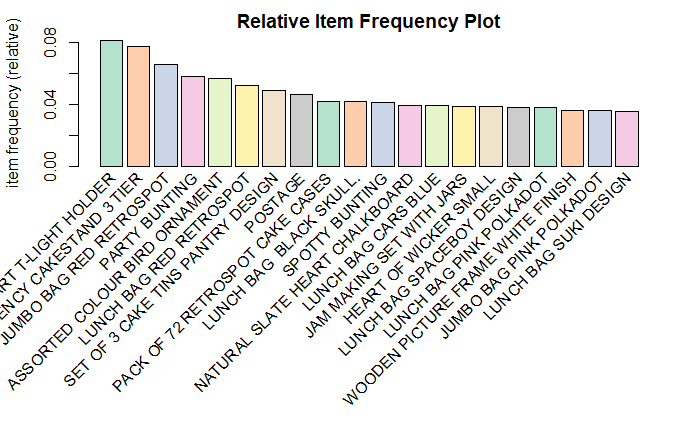
itemFrequencyPlot(tr, topN=20, type="relative", col=brewer.pal(8, 'Pastel2'), main="Relative Item Frequency Plot")
该图显示了”白色悬挂式心型T灯支架”和” REGENCY CAKESTAND 3层”的销量最高。因此, 要增加” 3个蛋糕罐的门廊设计”的销售, 零售商可以将其放在” REGENCY CAKESTAND 3 TIER”附近。
你可以在此处探索itemFrequencyPlot的其他选项。
生成规则!
下一步是使用APRIORI算法挖掘规则。函数apriori()来自包规则。
# Min Support as 0.001, confidence as 0.8.
association.rules <- apriori(tr, parameter = list(supp=0.001, conf=0.8, maxlen=10))
Apriori
Parameter specification:
confidence minval smax arem aval originalSupport maxtime support minlen maxlen target
0.8 0.1 1 none FALSE TRUE 5 0.001 1 10 rules
ext
FALSE
Algorithmic control:
filter tree heap memopt load sort verbose
0.1 TRUE TRUE FALSE TRUE 2 TRUE
Absolute minimum support count: 22
set item appearances ...[0 item(s)] done [0.00s].
set transactions ...[30066 item(s), 22191 transaction(s)] done [0.11s].
sorting and recoding items ... [2324 item(s)] done [0.02s].
creating transaction tree ... done [0.02s].
checking subsets of size 1 2 3 4 5 6 7 8 9 10
Mining stopped (maxlen reached). Only patterns up to a length of 10 returned!
done [0.70s].
writing ... [49122 rule(s)] done [0.06s].
creating S4 object ... done [0.06s].
set of 49122 rules
rule length distribution (lhs + rhs):sizes
2 3 4 5 6 7 8 9 10
105 2111 6854 16424 14855 6102 1937 613 121
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.000 5.000 5.000 5.499 6.000 10.000
summary of quality measures:
support confidence lift count
Min. :0.001036 Min. :0.8000 Min. : 9.846 Min. : 23.00
1st Qu.:0.001082 1st Qu.:0.8333 1st Qu.: 22.237 1st Qu.: 24.00
Median :0.001262 Median :0.8788 Median : 28.760 Median : 28.00
Mean :0.001417 Mean :0.8849 Mean : 64.589 Mean : 31.45
3rd Qu.:0.001532 3rd Qu.:0.9259 3rd Qu.: 69.200 3rd Qu.: 34.00
Max. :0.015997 Max. :1.0000 Max. :715.839 Max. :355.00
mining info:
data ntransactions support confidence
tr 22191 0.001 0.8
先验将以tr作为要在其上进行挖掘的交易对象。参数将允许你设置min_sup和min_confidence。参数的默认值为最小支持0.1, 最小置信度0.8, 最大10个项目(最大)。
summary(association.rules)显示以下内容:
- 参数规范:min_sup = 0.001和min_confidence = 0.8的值, 规则中最多10个项目。
- 规则总数:49122条规则集
- 规则长度的分布:5个项目的长度具有最多的规则:16424和2个项目的长度具有最小的规则数量:105
- 质量度量摘要:支撑, 信心和提升的最小值和最大值。
- 用于创建规则的信息:我们提供给算法的数据, 支持和置信度。
既然有49122条规则, 我们就只打印前10条:
inspect(association.rules[1:10])
lhs rhs support confidence lift count
[1] {WOBBLY CHICKEN} => {METAL} 0.001261773 1 443.82000 28
[2] {WOBBLY CHICKEN} => {DECORATION} 0.001261773 1 443.82000 28
[3] {DECOUPAGE} => {GREETING CARD} 0.001036456 1 389.31579 23
[4] {BILLBOARD FONTS DESIGN} => {WRAP} 0.001306836 1 715.83871 29
[5] {WOBBLY RABBIT} => {METAL} 0.001532153 1 443.82000 34
[6] {WOBBLY RABBIT} => {DECORATION} 0.001532153 1 443.82000 34
[7] {FUNK MONKEY} => {ART LIGHTS} 0.001712406 1 583.97368 38
[8] {ART LIGHTS} => {FUNK MONKEY} 0.001712406 1 583.97368 38
[9] {BLACK TEA} => {SUGAR JARS} 0.002072912 1 238.61290 46
[10] {BLACK TEA} => {COFFEE} 0.002072912 1 69.34687 46
使用以上输出, 你可以进行如下分析:
- 购买” WOBBLY CHICKEN”的客户中100%也购买了” METAL”。
- 购买”黑茶”的顾客中100%还购买了糖” JARS”。
限制规则的数量和大小
你如何限制生成的规则的大小和数量?你可以通过先验设置参数来实现。你可以设置这些参数来调整将要获得的规则数量。如果需要更强的规则, 则可以增加conf的值, 而更多扩展的规则可以为maxlen赋予更高的值。
shorter.association.rules <- apriori(tr, parameter = list(supp=0.001, conf=0.8, maxlen=3))
删除冗余规则
你可以删除作为较大规则子集的规则。使用以下代码删除此类规则:
subset.rules <- which(colSums(is.subset(association.rules, association.rules)) > 1) # get subset rules in vector
length(subset.rules) #> 3913
[1] 44014
subset.association.rules. <- association.rules[-subset.rules] # remove subset rules.
- which()返回向量中元素值为TRUE的位置。
- colSums()形成数据帧和数字数组的行和列总和。
- is.subset()确定一个向量的元素是否包含另一个向量的所有元素
查找与给定项目相关的规则
有时, 你想处理特定的产品。如果你想找出影响购买X物品的原因, 可以在apriori命令中使用外观选项。外观为我们提供了设置规则的LHS(IF部分)和RHS(THEN部分)的选项。
例如, 要在购买” METAL”之前查找客户购买的商品, 请运行以下代码:
metal.association.rules <- apriori(tr, parameter = list(supp=0.001, conf=0.8), appearance = list(default="lhs", rhs="METAL"))
Apriori
Parameter specification:
confidence minval smax arem aval originalSupport maxtime support minlen maxlen target
0.8 0.1 1 none FALSE TRUE 5 0.001 1 10 rules
ext
FALSE
Algorithmic control:
filter tree heap memopt load sort verbose
0.1 TRUE TRUE FALSE TRUE 2 TRUE
Absolute minimum support count: 22
set item appearances ...[1 item(s)] done [0.00s].
set transactions ...[30066 item(s), 22191 transaction(s)] done [0.21s].
sorting and recoding items ... [2324 item(s)] done [0.02s].
creating transaction tree ... done [0.02s].
checking subsets of size 1 2 3 4 5 6 7 8 9 10
Mining stopped (maxlen reached). Only patterns up to a length of 10 returned!
done [0.63s].
writing ... [5 rule(s)] done [0.07s].
creating S4 object ... done [0.02s].
# Here lhs=METAL because you want to find out the probability of that in how many customers buy METAL along with other items
inspect(head(metal.association.rules))
lhs rhs support confidence lift count
[1] {WOBBLY CHICKEN} => {METAL} 0.001261773 1 443.82 28
[2] {WOBBLY RABBIT} => {METAL} 0.001532153 1 443.82 34
[3] {DECORATION} => {METAL} 0.002253166 1 443.82 50
[4] {DECORATION, WOBBLY CHICKEN} => {METAL} 0.001261773 1 443.82 28
[5] {DECORATION, WOBBLY RABBIT} => {METAL} 0.001532153 1 443.82 34
同样, 要找到问题的答案, 购买METAL的客户也购买了…., 你将保持METAL的生命:
metal.association.rules <- apriori(tr, parameter = list(supp=0.001, conf=0.8), appearance = list(lhs="METAL", default="rhs"))
Apriori
Parameter specification:
confidence minval smax arem aval originalSupport maxtime support minlen maxlen target
0.8 0.1 1 none FALSE TRUE 5 0.001 1 10 rules
ext
FALSE
Algorithmic control:
filter tree heap memopt load sort verbose
0.1 TRUE TRUE FALSE TRUE 2 TRUE
Absolute minimum support count: 22
set item appearances ...[1 item(s)] done [0.00s].
set transactions ...[30066 item(s), 22191 transaction(s)] done [0.10s].
sorting and recoding items ... [2324 item(s)] done [0.02s].
creating transaction tree ... done [0.02s].
checking subsets of size 1 2 done [0.01s].
writing ... [1 rule(s)] done [0.00s].
creating S4 object ... done [0.01s].
# Here lhs=METAL because you want to find out the probability of that in how many customers buy METAL along with other items
inspect(head(metal.association.rules))
lhs rhs support confidence lift count
[1] {METAL} => {DECORATION} 0.002253166 1 443.82 50
可视化关联规则
由于将基于数据生成数百或数千条规则, 因此你需要两种方法来展示你的发现。上面已经讨论了ItemFrequencyPlot, 这也是获得畅销商品的好方法。
这里将讨论以下可视化:
- 散点图
- 交互式散点图
- 个别规则表示
散点图
关联规则的直观直观显示是通过arulesViz软件包的plot()使用散点图。它在轴上使用支持和置信度。此外, 默认情况下, 第三小节”提升”用于标记点的颜色(灰色级别)。
# Filter rules with confidence greater than 0.4 or 40%
subRules<-association.rules[quality(association.rules)$confidence>0.4]
#Plot SubRules
plot(subRules)
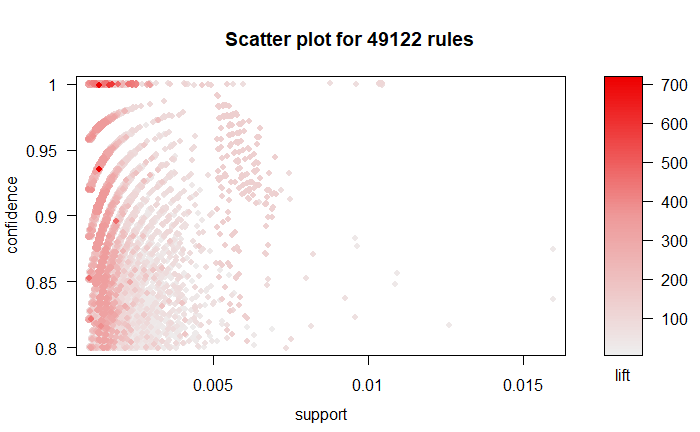
上图显示, 提升率较高的规则支持较低。你可以将以下选项用于绘图:
绘图(rulesObject, 度量, 明暗度, 方法)
- rulesObject:要绘制的规则对象
- 度量:规则趣味性的度量。可以是支持, 信心, 提升或这些的组合, 具体取决于方法值。
- 阴影:用于给点着色的度量(支撑, 置信度, 提升)。默认值为”提升”。
- 方法:要使用的可视化方法(散点图, 两键图和matrix3D)。
plot(subRules, method="two-key plot")
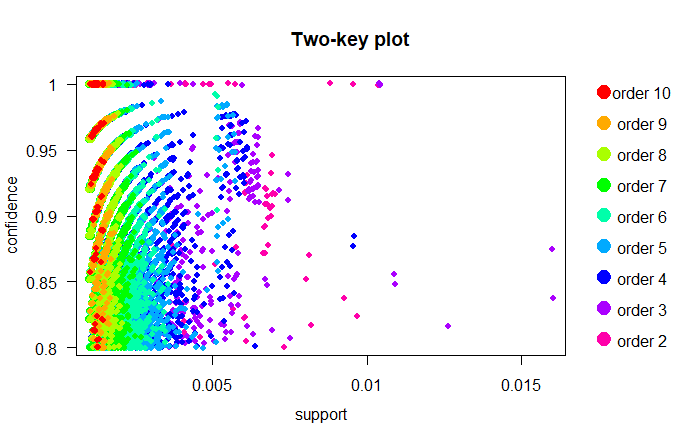
两键绘图分别在x和y轴上使用支持和置信度。它使用顺序进行着色。顺序是规则中的项目数。
交互式散点图
可以使用令人惊叹的交互式绘图来展示使用arulesViz和plotly的规则。你可以将鼠标悬停在每个规则上, 并查看所有质量指标(支持, 信心和提升)。
plotly_arules(subRules)
'plotly_arules' is deprecated.
Use 'plot' instead.
See help("Deprecated")plot: Too many rules supplied. Only plotting the best 1000 rules using measure lift (change parameter max if needed)To reduce overplotting, jitter is added! Use jitter = 0 to prevent jitter.
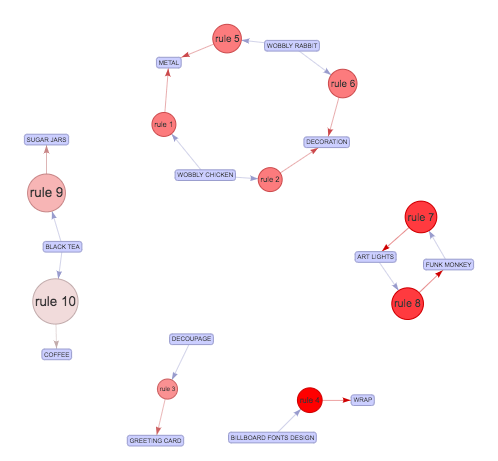
基于图的可视化
基于图的技术使用顶点和边来可视化关联规则, 其中顶点用项目名称标记, 并且项目集或规则表示为第二组顶点。使用定向箭头将项目与项目集/规则关联。从项指向规则顶点的箭头表示LHS项, 从规则指向项的箭头表示RHS。顶点的大小和颜色通常代表兴趣度量。
图形图是可视化规则的好方法, 但是随着规则数量的增加, 它会变得很拥挤。因此, 最好使用基于图的可视化来可视化较少的规则。
让我们从具有最高置信度的subRules中选择10条规则。
top10subRules <- head(subRules, n = 10, by = "confidence")
现在, 绘制一个交互式图形:
注意:你可以使用plot中的engine = htmlwidget参数使所有绘图具有交互性
plot(top10subRules, method = "graph", engine = "htmlwidget")
从arulesViz中, 关联规则集的图形可以GraphML格式导出, 也可以作为Graphviz点文件导出, 以便在Gephi之类的工具中进行浏览。例如, 通过以下方式导出具有最高提升的1000条规则:
saveAsGraph(head(subRules, n = 1000, by = "lift"), file = "rules.graphml")
个别规则表示
此表示也称为平行坐标图。可视化哪些产品以及哪些项目会导致什么样的销售。
如上所述, RHS是必需品或我们建议客户购买的物品;这些位置在LHS中, 其中2个是我们购物篮中最近添加的商品, 而1个是我们之前拥有的商品。
# Filter top 20 rules with highest lift
subRules2<-head(subRules, n=20, by="lift")
plot(subRules2, method="paracoord")
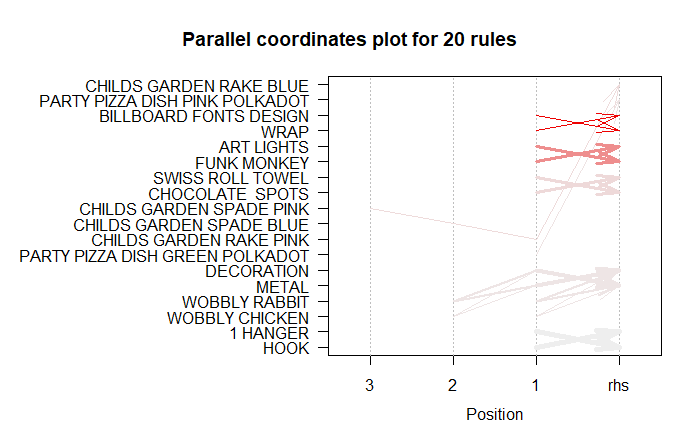
查看最上方的箭头。它表明, 当我的购物车中有”儿童花园粉红色”和”儿童花园粉红色”时, 我也可能会同时购买”儿童花园粉红色”。
总结
恭喜你!你已经了解了APRIORI, 它是数据挖掘中最常用的算法之一。你已经了解了关联规则挖掘, 其应用程序以及其在零售中称为”市场篮子分析”的所有应用程序。你现在还可以在R中实施”市场篮子分析”, 并以一些精美的图样展示关联规则!学习愉快!
参考文献:
- https://datascienceplus.com/a-gentle-introduction-on-market-basket-analysis%E2%80%8A-%E2%80%8Aassociation-rules/
- https://en.wikipedia.org/wiki/Sparse_matrix
- https://cran.r-project.org/web/packages/arulesViz/vignettes/arulesViz.pdf
如果你想了解有关R的更多信息, 请参加srcmini的”导入和管理财务数据”课程。
评论前必须登录!
注册