 srcmini
srcmini本文概述
- 导入模块
- 了解脑MRI 3T和7T数据集
- 定义初始化器
- 加载数据
- 数据预处理
- 合并连接
- 多解码器
- 损失函数
- 模型定义与编译
- 训练模型
- 测试验证数据
- 保存输入, 地面真相和解码:定量结果
- 导入模块
- 了解脑MRI 3T和7T数据集
- 定义初始化器
- 加载测试卷
- 数据预处理
- 该模型!
- 损失函数
- 三个自动编码器中的型号定义和负载权重!
- 测试量的模型预测:定量和定性结果!
在本教程中,您将使用Keras中的Python实现一个医学图像。
在”训练脚本”部分中, 你将使用新颖的深度学习体系结构来解决图像超分辨率问题。当前的任务是从低视场3-Tesla脑部MR图像到高视场7-Tesla脑部MR图像进行非线性映射。在”测试脚本”部分中, 你将使用在第1部分中训练的权重, 并根据看不见的训练数据进行预测。你还将学习如何最终将2D图像保存为组合体积。
本教程分为两个部分, 第一部分将引导你完成训练过程, 第二部分将涵盖测试过程。
- 第1部分:训练脚本
- 第2部分:测试脚本
注意:如果是这样, 你可能会对阅读本文感兴趣, 你可以在这里找到该文章。
简而言之, 你将在本教程的第1部分中解决以下主题:
- 首先, 导入所需的模块以训练深度学习模型,
- 然后将向你介绍3T和7T MRI数据集,
- 然后, 你将定义初始化程序并加载3T和7T数据集, 同时加载数据时, 你还将即时调整图像的大小,
- 接下来, 你将预处理加载的数据:将训练列表和测试列表转换为numpy矩阵, 将矩阵类型转换为float32, 使用max-min策略重新缩放矩阵, 调整数组的形状, 最后将数据拆分为80%的训练并剩下20 %进入验证集,
- 然后, 你将创建1-Encoder-3-Decoder Architecture:由合并连接和多解码器组成,
- 接下来, 你将定义损失函数, 定义三个不同的模型, 最后进行编译,
- 最后, 你将需要训练合并和多解码器模型, 在验证数据上对其进行测试并最终计算定量结果。
Python模块依赖性
在开始学习本教程之前, 请确保你具有与下面所述完全相同的模块版本:
- 硬== 2.0.4
- tensorflow == 1.8.0
- scipy == 0.19.0
- numpy == 1.14.5
- 枕头== 4.1.1
- nibabel == 2.1.0
- scikit_learn == 0.18.1
注意:开始之前, 请注意, 该模型将在配备32GB RAM的Nvidia 1080 Ti GPU Xeon e5 GeForce处理器的系统上进行训练。如果你正在使用Jupyter Notebook, 则将需要再添加三行代码, 在其中使用称为os的模块指定CUDA设备顺序和CUDA可见设备。
在下面的代码中, 使用os.environ在笔记本中设置环境变量。在初始化Keras以限制Keras后端TensorFlow使用第一个GPU之前, 最好执行以下操作。如果你要在其上训练的机器的GPU为0, 请确保使用0而不是1。你可以通过在终端上运行一个简单的命令来进行检查:例如nvidia-smi
import os
os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"]="0" #model will be trained on GPU
导入模块
首先, 导入所有必需的模块(例如tensorflow, numpy和最重要的是keras)以及必需的函数或层(例如Input, Conv2D, MaxPooling2D等), 因为你将使用所有这些框架来训练模型!
为了读取nifti格式的图像, 你还必须导入一个名为nibabel的模块。
import os
import numpy as np
import math
import tensorflow as tf
import nibabel as nib
import numpy as np
from keras.layers import Input, Dense, merge, Reshape, Conv2D, MaxPooling2D, UpSampling2D
from keras.layers.normalization import BatchNormalization
from keras.models import Model, Sequential
from keras.callbacks import ModelCheckpoint
from keras.optimizers import RMSprop
from keras import backend as K
import scipy.misc
from sklearn.utils import shuffle
from sklearn.cross_validation import train_test_split
import matplotlib.pyplot as plt
from keras.models import model_from_json
Using TensorFlow backend.
/usr/local/lib/python3.5/dist-packages/sklearn/cross_validation.py:41: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. Also, note that the interface of the new CV iterators is different from that of this module. This module will be removed in 0.20.
"This module will be removed in 0.20.", DeprecationWarning)
了解脑MRI 3T和7T数据集
大脑MRI 3T和7T数据集由3D体积组成, 每个体积在不同的大脑切片上拍摄的MRI图像总数为207个切片/图像。每个切片的尺寸为173 x173。图像是单通道灰度图像。共有39个对象, 每个对象都包含患者的MRI扫描。图像格式不是jpeg, png等, 而是nifti格式。你将在后面的章节中看到如何读取nifti格式的图像。
该数据集由T1模态MR图像组成, 传统上认为T1序列可用于评估解剖结构。你今天将要使用的数据集包括3T和7T脑部MRI。
该数据集是公开的, 可以从此源下载。
28个科目用于训练, 其余11个科目用于测试。
定义初始化器
首先定义数据的维度。你将在数据读取部分中将图像尺寸从173×173调整为176×176。在这里, 你还将定义数据目录, 用于训练模型的批处理大小, 通道数, Input()层, 训练和测试矩阵作为列表, 最后为了进行重新缩放, 你将加载文本文件, 该文件应具有最小的数量。和MRI数据集的最大值。
注意:对于重新缩放, 由于没有maxANDmin.txt文件, 因此也可以采用数据集的最大值和最小值。
x, y = 173, 173
full_z = 207
resizeTo=176
batch_size = 32
inChannel = outChannel = 1
input_shape=(x, y, inChannel)
input_img = Input(shape = (resizeTo, resizeTo, inChannel))
inp = "ground3T/"
out = "ground7T/"
train_matrix = []
test_matrix = []
min_max = np.loadtxt('maxANDmin.txt')
加载数据
接下来, 你使用nibabel库加载mri数据, 并通过在x和y维度上填充零将图像的大小从173 x 173调整为176 x 176。
请注意, 当你加载Nifti格式卷时, Nibabel不会加载图像阵列。它一直等到你要求数组数据。要求数组数据的标准方法是调用get_data()方法。
由于你希望使用2D切片而不是3D, 因此将使用之前初始化的训练和测试列表。每次阅读卷时, 你都将遍历3D卷的全部207个切片, 并将每个切片一个接一个地追加到列表中。
folder = os.listdir(inp)
首先加载3T数据。
for f in folder:
temp = np.zeros([resizeTo, full_z, resizeTo])
a = nib.load(inp + f)
a = a.get_data()
temp[3:, :, 3:] = a
a = temp
for j in range(full_z):
train_matrix.append(a[:, j, :])
然后, 加载7T数据, 并且由于3T和7T MR卷的数量相等, 因此也使用相同的文件夹变量来加载7T数据。
for f in folder:
temp = np.zeros([resizeTo, full_z, resizeTo])
b = nib.load(out + f)
b = b.get_data()
temp[3:, :, 3:] = b
b = temp
for j in range(full_z):
test_matrix.append(b[:, j, :])
数据预处理
由于训练矩阵和测试矩阵是列表, 因此你将使用numpy模块将列表转换为numpy数组。
此外, 你将把numpy数组的类型转换为float32, 并重新缩放输入和地面实况。
train_matrix = np.asarray(train_matrix)
train_matrix = train_matrix.astype('float32')
m = min_max[0]
mi = min_max[1]
train_matrix = (train_matrix - mi) / (m - mi)
test_matrix = np.asarray(test_matrix)
test_matrix = test_matrix.astype('float32')
test_matrix = (test_matrix - mi) / (m - mi)
让我们快速打印train_matrix(3T)和test_matrix(7T)矩阵的形状。它们总共应具有28 x 207 = 5796张图像, 每张图像的尺寸为176 x 176。
train_matrix.shape
(5796, 176, 176)
test_matrix.shape
(5796, 176, 176)
接下来, 你将创建形状火车和测试矩阵的两个新变量增强的图像(3T / input)和Haugmented_images(7T /地面真相)。这将是一个4D矩阵, 其中第一个维度将是图像的总数, 第二个和第三个维度是每个图像的维度, 最后一个维度是通道数, 在这种情况下是一个。”
augmented_images=np.zeros(shape=[(train_matrix.shape[0]), (train_matrix.shape[1]), (train_matrix.shape[2]), (1)])
Haugmented_images=np.zeros(shape=[(train_matrix.shape[0]), (train_matrix.shape[1]), (train_matrix.shape[2]), (1)])
然后, 你将一个接一个地遍历所有图像, 每次将火车和测试矩阵的形状重新调整为176 x 176并将其分别附加到extendeded_images(3T / input)和Haugmented_images(7T / ground true)之后。
for i in range(train_matrix.shape[0]):
augmented_images[i, :, :, 0] = train_matrix[i, :, :].reshape(resizeTo, resizeTo)
Haugmented_images[i, :, :, 0] = test_matrix[i, :, :].reshape(resizeTo, resizeTo)
完成所有这些之后, 对数据进行分区很重要。为了使模型更好地泛化, 你将数据分为两部分:训练和验证集。你将在80%的数据上训练模型, 并在剩余训练数据的20%上验证模型。
这也将帮助你减少过度拟合的机会, 因为你将根据训练阶段未看到的数据来验证模型。
你可以使用在开始时定义的scikit-learn的train_test_split模块正确地分割数据:
data, Label = shuffle(augmented_images, Haugmented_images, random_state=2)
X_train, X_test, y_train, y_test = train_test_split(data, Label, test_size=0.2, random_state=2)
X_test = np.array(X_test)
y_test = np.array(y_test)
X_test = X_test.astype('float32')
y_test = y_test.astype('float32')
X_train = np.array(X_train)
y_train = np.array(y_train)
X_train = X_train.astype('float32')
y_train = y_train.astype('float32')
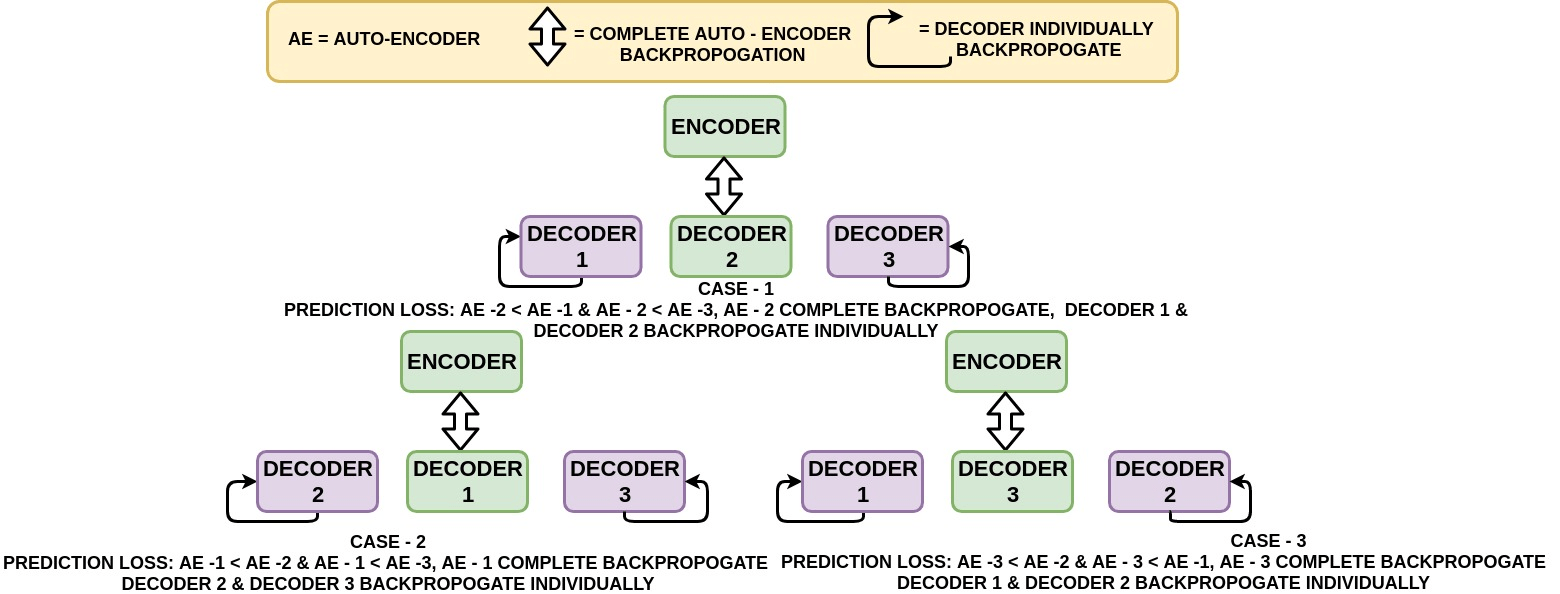
图:选择性自动编码器反向传播
图片取自本文。
合并连接
接下来, 在下一个单元中显示的编码器部分中, 使用随后的过滤器层块和最大池化层块定义所提出的体系结构。为了在输出时重构图像的原始大小, 在解码器的每个块中都引入了上采样层。在上采样时, 由于缺少解码器的下采样输入中的细节, 可能会引入一些伪像。因此, 你可以将解码器的输入与其来自编码器的升频版本连接起来, 以便提供升频细节的性质, 以便在解码器中进行升采样时更好地进行重构。实际上, 添加合并连接将显着提高PSNR(大约5db)。本文的灵感来自于我们的架构设置。
多解码器
所提出的方法采用具有单个通道输入的单个编码器和多个解码器体系结构。在一个编码器和所有三个解码器的每个块中使用三个卷积层, 然后使用批处理归一化层以保持数值稳定性。
编码器中的第一个卷积块有32个滤波器, 每个卷积块之后滤波器的数量加倍。在所有解码器中, 第一个卷积块具有256个滤波器, 每个块之后的滤波器数量减半。你将在所有卷积块中使用3×3的过滤器大小。
整流线性单位(ReLU)将在除最后一层之外的所有层中用作激活函数。由于数据在0到1之间归一化, 因此在最后一层使用了Sigmoid激活函数。
众所周知, 各种尺度的局部图像细节在图像重建中起着重要作用。所提出的体系结构考虑使用分层结构分别在编码器和解码器中进行下采样(最大池化)和上采样(每个因子为2)的不同比例的图像。经过三个下采样操作后获得的编码表示将数据从高维输入带到潜在空间表示。
编码器
def encoder(input_img):
conv1 = Conv2D(32, (3, 3), activation='relu', padding='same')(input_img)
conv1 = BatchNormalization()(conv1)
conv1 = Conv2D(32, (3, 3), activation='relu', padding='same')(conv1)
conv1 = BatchNormalization()(conv1)
conv1 = Conv2D(32, (3, 3), activation='relu', padding='same')(conv1)
conv1 = BatchNormalization()(conv1)
pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
conv2 = Conv2D(64, (3, 3), activation='relu', padding='same')(pool1)
conv2 = BatchNormalization()(conv2)
conv2 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv2)
conv2 = BatchNormalization()(conv2)
conv2 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv2)
conv2 = BatchNormalization()(conv2)
pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
conv3 = Conv2D(128, (3, 3), activation='relu', padding='same')(pool2)
conv3 = BatchNormalization()(conv3)
conv3 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv3)
conv3 = BatchNormalization()(conv3)
conv3 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv3)
conv3 = BatchNormalization()(conv3)
pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
conv4 = Conv2D(256, (3, 3), activation='relu', padding='same')(pool3)
conv4 = BatchNormalization()(conv4)
conv4 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv4)
conv4 = BatchNormalization()(conv4)
conv4 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv4)
conv4 = BatchNormalization()(conv4)
conv5 = Conv2D(512, (3, 3), activation='relu', padding='same')(conv4)
conv5 = BatchNormalization()(conv5)
conv5 = Conv2D(512, (3, 3), activation='relu', padding='same')(conv5)
conv5 = BatchNormalization()(conv5)
conv5 = Conv2D(512, (3, 3), activation='sigmoid', padding='same')(conv5)
conv5 = BatchNormalization()(conv5)
return conv5, conv4, conv3, conv2, conv1
解码器1
def decoder_1(conv5, conv4, conv3, conv2, conv1):
up6 = merge([conv5, conv4], mode='concat', concat_axis=3)
conv6 = Conv2D(256, (3, 3), activation='relu', padding='same')(up6)
conv6 = BatchNormalization()(conv6)
conv6 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv6)
conv6 = BatchNormalization()(conv6)
conv6 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv6)
conv6 = BatchNormalization()(conv6)
up7 = UpSampling2D((2, 2))(conv6)
up7 = merge([up7, conv3], mode='concat', concat_axis=3)
conv7 = Conv2D(128, (3, 3), activation='relu', padding='same')(up7)
conv7 = BatchNormalization()(conv7)
conv7 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv7)
conv7 = BatchNormalization()(conv7)
conv7 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv7)
conv7 = BatchNormalization()(conv7)
up8 = UpSampling2D((2, 2))(conv7)
up8 = merge([up8, conv2], mode='concat', concat_axis=3)
conv8 = Conv2D(64, (3, 3), activation='relu', padding='same')(up8)
conv8 = BatchNormalization()(conv8)
conv8 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv8)
conv8 = BatchNormalization()(conv8)
conv8 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv8)
conv8 = BatchNormalization()(conv8)
up9 = UpSampling2D((2, 2))(conv8)
up9 = merge([up9, conv1], mode='concat', concat_axis=3)
conv9 = Conv2D(32, (3, 3), activation='relu', padding='same')(up9)
conv9 = BatchNormalization()(conv9)
conv9 = Conv2D(32, (3, 3), activation='relu', padding='same')(conv9)
conv9 = BatchNormalization()(conv9)
conv9 = Conv2D(32, (3, 3), activation='relu', padding='same')(conv9)
conv9 = BatchNormalization()(conv9)
decoded_1 = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(conv9)
return decoded_1
解码器2
def decoder_2(conv5, conv4, conv3, conv2, conv1):
up6 = merge([conv5, conv4], mode='concat', concat_axis=3)
conv6 = Conv2D(256, (3, 3), activation='relu', padding='same')(up6)
conv6 = BatchNormalization()(conv6)
conv6 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv6)
conv6 = BatchNormalization()(conv6)
conv6 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv6)
conv6 = BatchNormalization()(conv6)
up7 = UpSampling2D((2, 2))(conv6)
up7 = merge([up7, conv3], mode='concat', concat_axis=3)
conv7 = Conv2D(128, (3, 3), activation='relu', padding='same')(up7)
conv7 = BatchNormalization()(conv7)
conv7 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv7)
conv7 = BatchNormalization()(conv7)
conv7 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv7)
conv7 = BatchNormalization()(conv7)
up8 = UpSampling2D((2, 2))(conv7)
up8 = merge([up8, conv2], mode='concat', concat_axis=3)
conv8 = Conv2D(64, (3, 3), activation='relu', padding='same')(up8)
conv8 = BatchNormalization()(conv8)
conv8 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv8)
conv8 = BatchNormalization()(conv8)
conv8 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv8)
conv8 = BatchNormalization()(conv8)
up9 = UpSampling2D((2, 2))(conv8)
up9 = merge([up9, conv1], mode='concat', concat_axis=3)
conv9 = Conv2D(32, (3, 3), activation='relu', padding='same')(up9)
conv9 = BatchNormalization()(conv9)
conv9 = Conv2D(32, (3, 3), activation='relu', padding='same')(conv9)
conv9 = BatchNormalization()(conv9)
conv9 = Conv2D(32, (3, 3), activation='relu', padding='same')(conv9)
conv9 = BatchNormalization()(conv9)
decoded_2 = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(conv9)
return decoded_2
解码器3
def decoder_3(conv5, conv4, conv3, conv2, conv1):
up6 = merge([conv5, conv4], mode='concat', concat_axis=3)
conv6 = Conv2D(256, (3, 3), activation='relu', padding='same')(up6)
conv6 = BatchNormalization()(conv6)
conv6 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv6)
conv6 = BatchNormalization()(conv6)
conv6 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv6)
conv6 = BatchNormalization()(conv6)
up7 = UpSampling2D((2, 2))(conv6)
up7 = merge([up7, conv3], mode='concat', concat_axis=3)
conv7 = Conv2D(128, (3, 3), activation='relu', padding='same')(up7)
conv7 = BatchNormalization()(conv7)
conv7 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv7)
conv7 = BatchNormalization()(conv7)
conv7 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv7)
conv7 = BatchNormalization()(conv7)
up8 = UpSampling2D((2, 2))(conv7)
up8 = merge([up8, conv2], mode='concat', concat_axis=3)
conv8 = Conv2D(64, (3, 3), activation='relu', padding='same')(up8)
conv8 = BatchNormalization()(conv8)
conv8 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv8)
conv8 = BatchNormalization()(conv8)
conv8 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv8)
conv8 = BatchNormalization()(conv8)
up9 = UpSampling2D((2, 2))(conv8)
up9 = merge([up9, conv1], mode='concat', concat_axis=3)
conv9 = Conv2D(32, (3, 3), activation='relu', padding='same')(up9)
conv9 = BatchNormalization()(conv9)
conv9 = Conv2D(32, (3, 3), activation='relu', padding='same')(conv9)
conv9 = BatchNormalization()(conv9)
conv9 = Conv2D(32, (3, 3), activation='relu', padding='same')(conv9)
conv9 = BatchNormalization()(conv9)
decoded_3 = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(conv9)
return decoded_3
在上面的四个单元格中, 你定义了四个功能。一个用于编码器, 其余三个用于解码器。由于它们是函数, 因此你可以定义define()函数并调用三遍, 但是为了更好地理解, 你将对其定义三遍并避免三个解码器的随机性问题。
损失函数
接下来, 你将采用均方误差, 其中将排除地面真实值y_t和y_p都等于零的值(像素)。
def root_mean_sq_GxGy(y_t, y_p):
a1=1
where = tf.not_equal(y_t, 0)
a_t=tf.boolean_mask(y_t, where, name='boolean_mask')
a_p=tf.boolean_mask(y_p, where, name='boolean_mask')
return a1*(K.sqrt(K.mean((K.square(a_t-a_p)))))
模型定义与编译
首先, 将输入传递给编码器函数。由于你在体系结构中使用合并连接, 因此编码器功能将返回五个卷积层的输出, 然后分别与所有三个解码器输出合并。
conv5, conv4, conv3, conv2, conv1 = encoder(input_img)
autoencoder_1 = Model(input_img, decoder_1(conv5, conv4, conv3, conv2, conv1))
autoencoder_1.compile(loss=root_mean_sq_GxGy, optimizer = RMSprop())
autoencoder_2 = Model(input_img, decoder_2(conv5, conv4, conv3, conv2, conv1))
autoencoder_2.compile(loss=root_mean_sq_GxGy, optimizer = RMSprop())
autoencoder_3 = Model(input_img, decoder_3(conv5, conv4, conv3, conv2, conv1))
autoencoder_3.compile(loss=root_mean_sq_GxGy, optimizer = RMSprop())
/usr/local/lib/python3.5/dist-packages/ipykernel_launcher.py:2: UserWarning: The `merge` function is deprecated and will be removed after 08/2017. Use instead layers from `keras.layers.merge`, e.g. `add`, `concatenate`, etc.
/usr/local/lib/python3.5/dist-packages/keras/legacy/layers.py:460: UserWarning: The `Merge` layer is deprecated and will be removed after 08/2017. Use instead layers from `keras.layers.merge`, e.g. `add`, `concatenate`, etc.
name=name)
/usr/local/lib/python3.5/dist-packages/ipykernel_launcher.py:10: UserWarning: The `merge` function is deprecated and will be removed after 08/2017. Use instead layers from `keras.layers.merge`, e.g. `add`, `concatenate`, etc.
# Remove the CWD from sys.path while we load stuff.
/usr/local/lib/python3.5/dist-packages/ipykernel_launcher.py:18: UserWarning: The `merge` function is deprecated and will be removed after 08/2017. Use instead layers from `keras.layers.merge`, e.g. `add`, `concatenate`, etc.
/usr/local/lib/python3.5/dist-packages/ipykernel_launcher.py:26: UserWarning: The `merge` function is deprecated and will be removed after 08/2017. Use instead layers from `keras.layers.merge`, e.g. `add`, `concatenate`, etc.
WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/keras/backend/tensorflow_backend.py:1257: calling reduce_mean (from tensorflow.python.ops.math_ops) with keep_dims is deprecated and will be removed in a future version.
Instructions for updating:
keep_dims is deprecated, use keepdims instead
训练模型
仅当验证数据上的峰值信噪比提高时, 才保存权重。因此, 为此你将定义一个psnr_gray_channel列表, 其中将默认值附加为1, 因此将附加1, 因为你需要使用随机数初始化该列表, 并且即使在训练的初始阶段, PSNR也将远远大于该值。 , 这将只是一个虚拟数字。
你将学习速率初始化为1e-3, 并使用学习速率衰减策略, 即每20个周期将学习速率从当前值降低10%!
psnr_gray_channel = []
psnr_gray_channel.append(1)
learning_rate = 0.001
j=0
注意:下一个完整的代码需要在一个完整的单元中运行, 但是为了更好地理解整个训练过程, 它将被分成几个小单元。
该模型训练了500个纪元。初始学习率是1e-3, 如上一个单元格所定义。你还将在每次7T预测之后保存PSNR, MSE值。你将使用K.set_value函数将所有三个模型的学习率更改为10%, 但每20个周期后更改一次。
for jj in range(500):
myfile_valid_psnr_7T = open('../1_encoder_3_decoders_complete_slices_single_channel/validation_psnr7T_1encoder_3decoders.txt', 'a')
myfile_valid_mse_7T = open('../1_encoder_3_decoders_complete_slices_single_channel/validation_mse7T_1encoder_3decoders.txt', 'a')
K.set_value(autoencoder_1.optimizer.lr, learning_rate)
K.set_value(autoencoder_2.optimizer.lr, learning_rate)
K.set_value(autoencoder_3.optimizer.lr, learning_rate)
接下来, 你可以对输入的3T和地面真实7T图像进行混洗, 以避免网络过度拟合, 因为不进行混洗将使模型在每个历元之后以相同的顺序查看样本。然后, 你将根据之前定义的batch_size计算将要创建的批次数量。最后, 你开始遍历num_batches。
train_X, train_Y = shuffle(X_train, y_train)
print ("Epoch is: %d\n" % j)
print ("Number of batches: %d\n" % int(len(train_X)/batch_size))
num_batches = int(len(train_X)/batch_size)
for batch in range(num_batches):
除了存储PSNR值外, 你还将分别存储所有三个自动编码器和三个解码器的损耗。
myfile_ae1_loss = open('../1_encoder_3_decoders_complete_slices_single_channel/ae1_train_loss_1encoder_3decoders.txt', 'a')
myfile_ae2_loss = open('../1_encoder_3_decoders_complete_slices_single_channel/ae2_train_loss_1encoder_3decoders.txt', 'a')
myfile_ae3_loss = open('../1_encoder_3_decoders_complete_slices_single_channel/ae3_train_loss_1encoder_3decoders.txt', 'a')
myfile_dec1_loss = open('../1_encoder_3_decoders_complete_slices_single_channel/dec1_train_loss_1encoder_3decoders.txt', 'a')
myfile_dec2_loss = open('../1_encoder_3_decoders_complete_slices_single_channel/dec2_train_loss_1encoder_3decoders.txt', 'a')
myfile_dec3_loss = open('../1_encoder_3_decoders_complete_slices_single_channel/dec3_train_loss_1encoder_3decoders.txt', 'a')
由于在每个批次中, 你都希望模型可以查看下32个(batch_size)样本, 因此下一个单元将为你完成该工作!
batch_train_X = train_X[batch*batch_size:min((batch+1)*batch_size, len(train_X)), :]
batch_train_Y = train_Y[batch*batch_size:min((batch+1)*batch_size, len(train_Y)), :]
接下来, 我们的最小自动编码器策略将起作用, 在每个时期之后, 你都将使用Keras test_on_batch函数对训练数据进行测试, 这将分别给你带来三项损失, 最后将它们打印出来。
loss_1 = autoencoder_1.test_on_batch(batch_train_X, batch_train_Y)
loss_2 = autoencoder_2.test_on_batch(batch_train_X, batch_train_Y)
loss_3 = autoencoder_3.test_on_batch(batch_train_X, batch_train_Y)
print ('epoch_num: %d batch_num: %d Test_loss_1: %f\n' % (j, batch, loss_1))
print ('epoch_num: %d batch_num: %d Test_loss_2: %f\n' % (j, batch, loss_2))
print ('epoch_num: %d batch_num: %d Test_loss_3: %f\n' % (j, batch, loss_3))
你的网络中可能存在六种情况:
loss_1:自动编码器1丢失
loss_2:自动编码器2丢失
loss_3:自动编码器3损失
loss_1可以大于loss_2和loss_3。如果是这样, 则仅使用自动编码器1进行训练。将自动编码器2和自动编码器3编码器部分设置为False, 并且仅训练其解码器, 最后, 将所有损失写入文本文件中。
loss_2可能大于loss_1和loss_3。如果是这样, 则仅使用自动编码器2进行训练。将自动编码器1和自动编码器3编码器部分设置为False, 并且仅训练其解码器, 最后, 将所有损失写入文本文件中。
loss_3可以大于loss_1和loss_2。如果是这样, 则仅使用自动编码器3进行训练。将自动编码器1和自动编码器2编码器的部分设置为False, 并且仅训练其解码器, 最后, 将所有损失写入文本文件中。
loss_1可以等于loss_2。如果是这样, 那么你将使用自动编码器1或2进行训练。将自动编码器3编码器部分与未在1和2之间选择的自动编码器一起设置为False, 并仅训练其解码器, 最后, 你将编写所有文本文件中的损失。
loss_2可以等于loss_3。如果这是真的, 那么你将使用自动编码器2或3进行训练。将自动编码器1编码器部分与未在2和3之间选择的自动编码器一起设置为False, 并仅训练其解码器, 最后, 你将编写所有文本文件中的损失。
loss_3可以等于loss_1。如果为true, 则使用Autoencoder 3或1进行训练。将Autoencoder 2 Encoder的部分设为False, 以及未在3和1之间选择的Autoencoder, 仅训练其解码器, 然后最后, 你将所有损失写入文本文件。
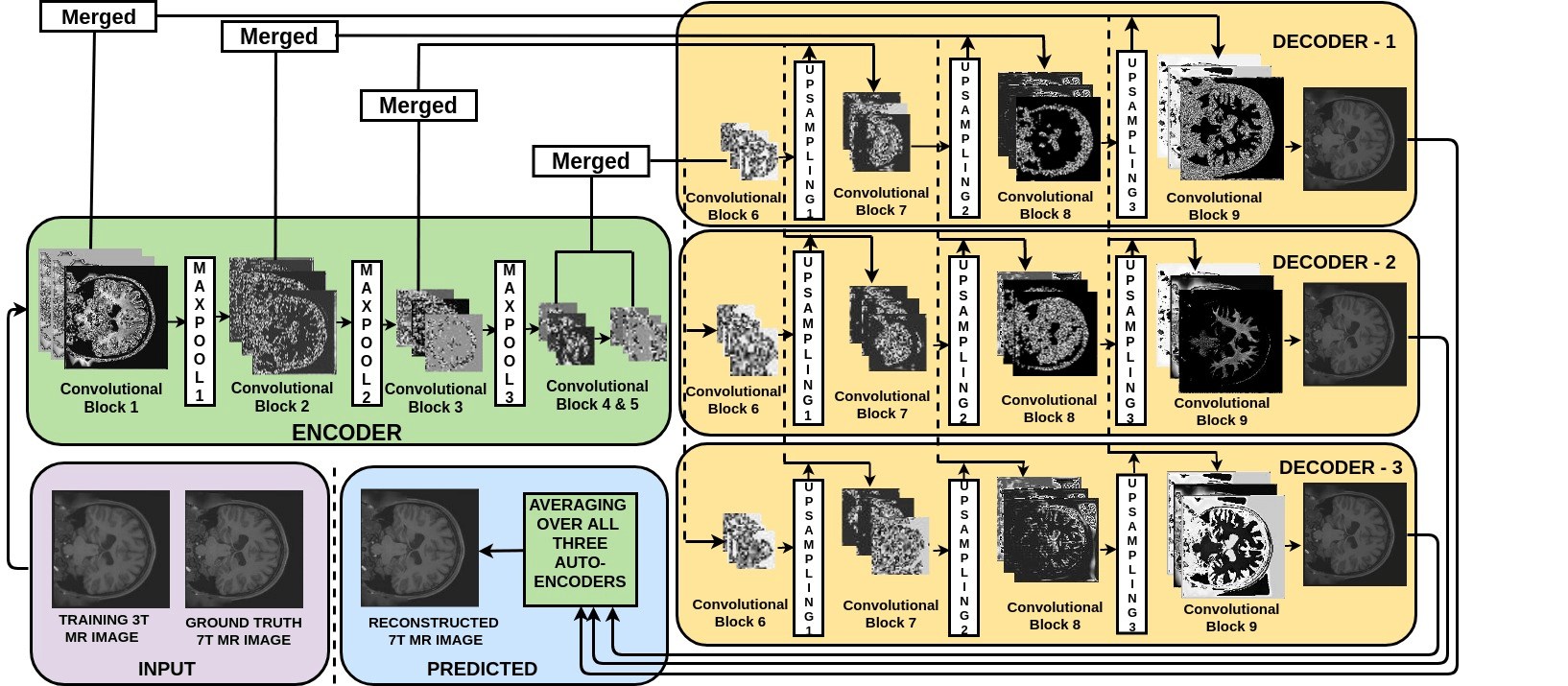
图:模型的架构
图片取自本文。
if loss_1 < loss_2 and loss_1 < loss_3:
train_1 = autoencoder_1.train_on_batch(batch_train_X, batch_train_Y)
myfile_ae1_loss.write("%f \n" % (train_1))
print ('epoch_num: %d batch_num: %d AE_Train_loss_1: %f\n' % (j, batch, train_1))
#myfile.write('epoch_num: %d batch_num: %d AE_Train_loss_1: %f\n' % (j, batch, train_1))
for layer in autoencoder_2.layers[:34]:
layer.trainable = False
for layer in autoencoder_3.layers[:34]:
layer.trainable = False
#autoencoder_2.summary()
#autoencoder_3.summary()
train_2 = autoencoder_2.train_on_batch(batch_train_X, batch_train_Y)
train_3 = autoencoder_3.train_on_batch(batch_train_X, batch_train_Y)
myfile_dec2_loss.write("%f \n" % (train_2))
myfile_dec3_loss.write("%f \n" % (train_3))
print ('epoch_num: %d batch_num: %d Decoder_Train_loss_2: %f\n' % (j, batch, train_2))
print ('epoch_num: %d batch_num: %d Decoder_loss_3: %f\n' % (j, batch, train_3))
#myfile.write('epoch_num: %d batch_num: %d Decoder_Train_loss_2: %f\n' % (j, batch, train_2))
#myfile.write('epoch_num: %d batch_num: %d Decoder_loss_3: %f\n' % (j, batch, train_3))
elif loss_2 < loss_1 and loss_2 < loss_3:
train_2 = autoencoder_2.train_on_batch(batch_train_X, batch_train_Y)
myfile_ae2_loss.write("%f \n" % (train_2))
print ('epoch_num: %d batch_num: %d AE_Train_loss_2: %f\n' % (j, batch, train_2))
#myfile.write('epoch_num: %d batch_num: %d AE_Train_loss_2: %f\n' % (j, batch, train_2))
for layer in autoencoder_1.layers[:34]:
layer.trainable = False
for layer in autoencoder_3.layers[:34]:
layer.trainable = False
#autoencoder_1.summary()
#autoencoder_3.summary()
train_1 = autoencoder_1.train_on_batch(batch_train_X, batch_train_Y)
train_3 = autoencoder_3.train_on_batch(batch_train_X, batch_train_Y)
myfile_dec1_loss.write("%f \n" % (train_1))
myfile_dec3_loss.write("%f \n" % (train_3))
print ('epoch_num: %d batch_num: %d Decoder_Train_loss_1: %f\n' % (j, batch, train_1))
print ('epoch_num: %d batch_num: %d Decoder_Train_loss_3: %f\n' % (j, batch, train_3))
#myfile.write('epoch_num: %d batch_num: %d Decoder_Train_loss_1: %f\n' % (j, batch, train_1))
#myfile.write('epoch_num: %d batch_num: %d Decoder_Train_loss_3: %f\n' % (j, batch, train_3))
elif loss_3 < loss_1 and loss_3 < loss_2:
train_3 = autoencoder_3.train_on_batch(batch_train_X, batch_train_Y)
myfile_ae3_loss.write("%f \n" % (train_3))
print ('epoch_num: %d batch_num: %d AE_Train_loss_3: %f\n' % (j, batch, train_3))
#myfile.write('epoch_num: %d batch_num: %d AE_Train_loss_3: %f\n' % (j, batch, train_3))
for layer in autoencoder_1.layers[:34]:
layer.trainable = False
for layer in autoencoder_2.layers[:34]:
layer.trainable = False
#autoencoder_1.summary()
#autoencoder_2.summary()
train_1 = autoencoder_1.train_on_batch(batch_train_X, batch_train_Y)
train_2 = autoencoder_2.train_on_batch(batch_train_X, batch_train_Y)
myfile_dec1_loss.write("%f \n" %(train_1))
myfile_dec2_loss.write("%f \n" % (train_2))
print ('epoch_num: %d batch_num: %d Decoder_Train_loss_1: %f\n' % (j, batch, train_1))
print ('epoch_num: %d batch_num: %d Decoder_Train_loss_2: %f\n' % (j, batch, train_2))
#myfile.write('epoch_num: %d batch_num: %d Decoder_Train_loss_1: %f\n' % (j, batch, train_1))
#myfile.write('epoch_num: %d batch_num: %d Decoder_Train_loss_2: %f\n' % (j, batch, train_2))
elif loss_1 == loss_2:
train_1 = autoencoder_1.train_on_batch(batch_train_X, batch_train_Y)
myfile_ae1_loss.write("%f \n" % (train_1))
print ('epoch_num: %d batch_num: %d AE_Train_loss_1_equal_state: %f\n' % (j, batch, train_1))
#myfile.write('epoch_num: %d batch_num: %d AE_Train_loss_1_equal_state: %f\n' % (j, batch, train_1))
for layer in autoencoder_3.layers[:34]:
layer.trainable = False
for layer in autoencoder_2.layers[:34]:
layer.trainable = False
#autoencoder_2.summary()
#autoencoder_3.summary()
train_2 = autoencoder_2.train_on_batch(batch_train_X, batch_train_Y)
train_3 = autoencoder_3.train_on_batch(batch_train_X, batch_train_Y)
myfile_dec2_loss.write("%f \n" % (train_2))
myfile_dec3_loss.write("%f \n" % (train_3))
print ('epoch_num: %d batch_num: %d Decoder_Train_loss_2_equal_state: %f\n' % (j, batch, train_2))
print ('epoch_num: %d batch_num: %d Decoder_Train_loss_3_equal_state: %f\n' % (j, batch, train_3))
#myfile.write('epoch_num: %d batch_num: %d Decoder_Train_loss_2_equal_state: %f\n' % (j, batch, train_2))
#myfile.write('epoch_num: %d batch_num: %d Decoder_Train_loss_3_equal_state: %f\n' % (j, batch, train_3))
elif loss_2 == loss_3:
train_2 = autoencoder_2.train_on_batch(batch_train_X, batch_train_Y)
myfile_ae2_loss.write("%f \n" % (train_2))
print ('epoch_num: %d batch_num: %d AE_Train_loss_2_equal_state: %f\n' % (j, batch, train_2))
#myfile.write('epoch_num: %d batch_num: %d AE_Train_loss_2_equal_state: %f\n' % (j, batch, train_2))
for layer in autoencoder_1.layers[:34]:
layer.trainable = False
for layer in autoencoder_3.layers[:34]:
layer.trainable = False
#autoencoder_2.summary()
#autoencoder_3.summary()
train_1 = autoencoder_1.train_on_batch(batch_train_X, batch_train_Y)
train_3 = autoencoder_3.train_on_batch(batch_train_X, batch_train_Y)
myfile_dec1_loss.write("%f \n" % (train_1))
myfile_dec3_loss.write("%f \n" % (train_3))
print ('epoch_num: %d batch_num: %d Decoder_Train_loss_1_equal_state: %f\n' % (j, batch, train_1))
print ('epoch_num: %d batch_num: %d Decoder_Train_loss_3_equal_state: %f\n' % (j, batch, train_3))
#myfile.write('epoch_num: %d batch_num: %d Decoder_Train_loss_1_equal_state: %f\n' % (j, batch, train_1))
#myfile.write('epoch_num: %d batch_num: %d Decoder_Train_loss_3_equal_state: %f\n' % (j, batch, train_3))
elif loss_3 == loss_1:
train_1 = autoencoder_1.train_on_batch(batch_train_X, batch_train_Y)
myfile_ae1_loss.write("%f \n" % (train_1))
print ('epoch_num: %d batch_num: %d AE_Train_loss_1_equal_state: %f\n' % (j, batch, train_1))
#myfile.write('epoch_num: %d batch_num: %d AE_Train_loss_1_equal_state: %f\n' % (j, batch, train_1))
for layer in autoencoder_2.layers[:34]:
layer.trainable = False
for layer in autoencoder_3.layers[:34]:
layer.trainable = False
#autoencoder_2.summary()
#autoencoder_3.summary()
train_2 = autoencoder_2.train_on_batch(batch_train_X, batch_train_Y)
train_3 = autoencoder_3.train_on_batch(batch_train_X, batch_train_Y)
myfile_dec2_loss.write("%f \n" % (train_2))
myfile_dec3_loss.write("%f \n" % (train_3))
print ('epoch_num: %d batch_num: %d Decoder_Train_loss_2_equal_state: %f\n' % (j, batch, train_2))
print ('epoch_num: %d batch_num: %d Decoder_Train_loss_3_equal_state: %f\n' % (j, batch, train_3))
#myfile.write('epoch_num: %d batch_num: %d Decoder_Train_loss_2_equal_state: %f\n' % (j, batch, train_2))
#myfile.write('epoch_num: %d batch_num: %d Decoder_Train_loss_3_equal_state: %f\n' % (j, batch, train_3))
myfile_ae1_loss.close()
myfile_ae2_loss.close()
myfile_ae3_loss.close()
myfile_dec1_loss.close()
myfile_dec2_loss.close()
myfile_dec3_loss.close()
这是必不可少的步骤, 因为你在上述条件下将几层设为False, 需要将这些层设为True, 以便所有自动编码器层都可以用于test_on_batch函数, 并且你不希望在整个过程中都将它们保持False。训练。
for layer in autoencoder_1.layers[:34]:
layer.trainable = True
for layer in autoencoder_2.layers[:34]:
layer.trainable = True
for layer in autoencoder_3.layers[:34]:
layer.trainable = True
你将以三种不同的方式节省重量, 以下是其中两种。一个, 你将在每100个周期后保存权重, 第二个, 你将在每个周期后保存权重。基本上, 它们在每个时期后都会被覆盖。
if jj % 100 ==0:
autoencoder_1.save_weights("../Model/CROSSVAL1/CROSSVAL1_AE1_" + str(jj)+".h5")
autoencoder_2.save_weights("../Model/CROSSVAL1/CROSSVAL1_AE2_" + str(jj)+".h5")
autoencoder_3.save_weights("../Model/CROSSVAL1/CROSSVAL1_AE3_" + str(jj)+".h5")
autoencoder_1.save_weights("../Model/CROSSVAL1/CROSSVAL1_AE1.h5")
autoencoder_2.save_weights("../Model/CROSSVAL1/CROSSVAL1_AE2.h5")
autoencoder_3.save_weights("../Model/CROSSVAL1/CROSSVAL1_AE3.h5")
测试验证数据
你将首先重新整理验证数据, 然后使用与上述相同的6种可能的条件。因此, 无论条件为True, 你都将使用该特定的自动编码器测试模型。
然后, 你可以计算decoded_imgs(预测的)与真实情况之间的两个指标MSE和PSNR。最后, 将它们保存在文本文件中。
X_test, y_test = shuffle(X_test, y_test)
if loss_1 < loss_2 and loss_1 < loss_3:
decoded_imgs = autoencoder_1.predict(X_test)
mse_7T= np.mean((y_test[:, :, :, 0] - decoded_imgs[:, :, :, 0]) ** 2)
check_7T = math.sqrt(mse_7T)
psnr_7T = 20 * math.log10( 1.0 / check_7T)
myfile_valid_psnr_7T.write("%f \n" % (psnr_7T))
myfile_valid_mse_7T.write("%f \n" % (mse_7T))
#print (check)
elif loss_2 < loss_1 and loss_2 < loss_3:
decoded_imgs = autoencoder_2.predict(X_test)
mse_7T= np.mean((y_test[:, :, :, 0] - decoded_imgs[:, :, :, 0]) ** 2)
check_7T = math.sqrt(mse_7T)
psnr_7T = 20 * math.log10( 1.0 / check_7T)
myfile_valid_psnr_7T.write("%f \n" % (psnr_7T))
myfile_valid_mse_7T.write("%f \n" % (mse_7T))
#print (check)
elif loss_3 < loss_2 and loss_3 < loss_1:
decoded_imgs = autoencoder_3.predict(X_test)
mse_7T= np.mean((y_test[:, :, :, 0] - decoded_imgs[:, :, :, 0]) ** 2)
check_7T = math.sqrt(mse_7T)
psnr_7T = 20 * math.log10( 1.0 / check_7T)
myfile_valid_psnr_7T.write("%f \n" % (psnr_7T))
myfile_valid_mse_7T.write("%f \n" % (mse_7T))
#print (check)
elif loss_1 == loss_2:
decoded_imgs = autoencoder_1.predict(X_test)
mse_7T= np.mean((y_test[:, :, :, 0] - decoded_imgs[:, :, :, 0]) ** 2)
check_7T = math.sqrt(mse_7T)
psnr_7T = 20 * math.log10( 1.0 / check_7T)
myfile_valid_psnr_7T.write("%f \n" % (psnr_7T))
myfile_valid_mse_7T.write("%f \n" % (mse_7T))
elif loss_2 == loss_3:
decoded_imgs = autoencoder_2.predict(X_test)
mse_7T= np.mean((y_test[:, :, :, 0] - decoded_imgs[:, :, :, 0]) ** 2)
check_7T = math.sqrt(mse_7T)
psnr_7T = 20 * math.log10( 1.0 / check_7T)
myfile_valid_psnr_7T.write("%f \n" % (psnr_7T))
myfile_valid_mse_7T.write("%f \n" % (mse_7T))
elif loss_3 == loss_1:
decoded_imgs = autoencoder_3.predict(X_test)
mse_7T= np.mean((y_test[:, :, :, 0] - decoded_imgs[:, :, :, 0]) ** 2)
check_7T = math.sqrt(mse_7T)
psnr_7T = 20 * math.log10( 1.0 / check_7T)
myfile_valid_psnr_7T.write("%f \n" % (psnr_7T))
myfile_valid_mse_7T.write("%f \n" % (mse_7T))
在此, 仅当预测的7T与地面真实情况(7T)之间的PSNR与psnr_gray_channel列表中存储的先前PSNR值相比最大时, 才保存权重。
if max(psnr_gray_channel) < psnr_7T:
autoencoder_1.save_weights("../Model/CROSSVAL1/CROSSVAL1_AE1_" + str(jj)+".h5")
autoencoder_2.save_weights("../Model/CROSSVAL1/CROSSVAL1_AE2_" + str(jj)+".h5")
autoencoder_3.save_weights("../Model/CROSSVAL1/CROSSVAL1_AE3_" + str(jj)+".h5")
psnr_gray_channel.append(psnr_7T)
保存输入, 地面真相和解码:定量结果
你将定义一个numpy矩阵temp, 其大小为176 x 528, 因为将在一行中保存3张图像, 每张图像的尺寸为176 x176。你将保存所有验证3T, 7T中的任何图像并预测并乘以255, 因为图像在0和1之间按比例缩小。
最后使用scipy功能, 你将保存图像。
temp = np.zeros([resizeTo, resizeTo*3])
temp[:resizeTo, :resizeTo] = X_test[0, :, :, 0]
temp[:resizeTo, resizeTo:resizeTo*2] = y_test[0, :, :, 0]
temp[:resizeTo, 2*resizeTo:] = decoded_imgs[0, :, :, 0]
temp = temp*255
scipy.misc.imsave('../Results/1_encoder_3_decoders_complete_slices_single_channel/' + str(j) + '.jpg', temp)
j +=1
最后, 让我们关闭PSNR和MSE文件。
myfile_valid_psnr_7T.close()
myfile_valid_mse_7T.close()
最后, 最后, 你将每隔20个周期将学习率降低为其当前值的10%。
if jj % 20 ==0:
learning_rate = learning_rate - learning_rate * 0.10
你将在本教程的第2部分中解决以下主题:
- 首先, 导入所需的模块以训练深度学习模型,
- 然后将向你介绍3T和7T MRI数据集,
- 然后, 你将定义初始化器并加载3T和7T测试数据集, 同时在加载数据的同时还将动态调整图像的大小,
- 接下来, 你将预处理加载的数据:将训练列表和测试列表转换为numpy矩阵, 将矩阵类型转换为float32, 使用max-min策略重新缩放矩阵, 调整数组的形状, 最后将数据拆分为80%的训练和剩余的20%进入验证集
- 然后, 你将创建1-Encoder-3-Decoder Architecture:由合并连接和多解码器组成,
- 接下来, 你将定义:损失函数, 三种不同的模型, 最后加载训练后的权重,
- 最后, 你可以使用合并和多解码器模型对看不见的数据进行预测, 并保存定量和定性结果。你还将学习如何使用nibabel将2D图像保存为组合体积。
Python模块依赖性
在开始学习本教程之前, 请确保你具有与下面所述完全相同的模块版本:
- 硬== 2.0.4
- tensorflow == 1.8.0
- scipy == 0.19.0
- numpy == 1.14.5
- 枕头== 4.1.1
- nibabel == 2.1.0
- scikit_learn == 0.18.1
注意:开始之前, 请注意, 该模型将在配备32GB RAM的Nvidia 1080 Ti GPU Xeon e5 GeForce处理器的系统上进行训练。如果你正在使用Jupyter Notebook, 则将需要再添加三行代码, 在其中使用称为os的模块指定CUDA设备顺序和CUDA可见设备。
在下面的代码中, 你基本上使用os.environ在笔记本中设置了环境变量。在初始化Keras以限制Keras后端TensorFlow使用第一个GPU之前, 最好执行以下操作。如果你要在其上训练的机器的GPU为0, 请确保使用0而不是1。你可以通过在终端上运行一个简单的命令来进行检查:例如nvidia-smi
import os
os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"]="0" #model will be trained on GPU
导入模块
首先, 导入所有必需的模块(如tensorflow, numpy和最重要的是keras)以及必需的函数或层(如Input, Conv2D, MaxPooling2D等), 因为你将使用所有这些框架来训练模型!
要读取nifti格式的图像, 你还必须导入一个名为nibabel的模块。
import os
from keras.layers import Input, Dense, Flatten, Dropout, merge, Reshape, Conv2D, MaxPooling2D, UpSampling2D
from keras.layers.normalization import BatchNormalization
from keras.models import Model, Sequential
from keras.callbacks import ModelCheckpoint
from keras.optimizers import Adadelta, RMSprop, SGD, Adam
from keras import regularizers
from keras import backend as K
import numpy as np
import scipy.misc
import numpy.random as rng
from sklearn.utils import shuffle
import nibabel as nib
from sklearn.cross_validation import train_test_split
import math
了解脑MRI 3T和7T数据集
大脑MRI 3T和7T数据集由3D体积组成, 每个体积在不同的大脑切片上拍摄的MRI图像总数为207个切片/图像。每个切片的尺寸为173 x173。图像是单通道灰度图像。共有39个对象, 每个对象都包含患者的MRI扫描。图像格式不是jpeg, png等, 而是nifti格式。你将在后面的章节中看到如何读取nifti格式的图像。
该数据集由T1模态MR图像组成, 传统上认为T1序列可用于评估解剖结构。你今天将要使用的数据集包括3T和7T脑部MRI。
该数据集是公开的, 可以从此源下载。
定义初始化器
首先定义数据的维度。你将在数据读取部分中将图像尺寸从173×173调整为176×176。在这里, 我们还定义了数据目录, 用于训练模型的批处理大小, 多个通道, 一个Input()层, 作为列表的训练和测试矩阵, 最后为了重新缩放, 我们加载了具有最小和最大值的文本文件MRI数据集的值。
x, y = 173, 173
full_z = 207
resizeTo=176
inChannel = outChannel = 1
input_shape=(x, y, inChannel)
input_img = Input(shape = (resizeTo, resizeTo, inChannel))
train_matrix = []
test_matrix = []
ff = os.listdir("../test_crossval1")
save = "../Result_nii_crossval1/"
folder_ground = os.listdir("../test_g_crossval1")
ToPredict_images=[]
predict_matrix=[]
ground_images=[]
ground_matrix=[]
min_max=np.loadtxt('../maxANDmin.txt')
加载测试卷
接下来, 我们使用nibabel库加载mri数据, 并通过在x和y维度上填充零将图像的大小从173 x 173调整为176 x 176。
请注意, 当你加载Nifti格式卷时, Nibabel不会加载图像阵列。它一直等到你要求数组数据。要求数组数据的标准方法是调用get_data()方法。
由于你希望使用2D切片而不是3D, 因此将使用之前初始化的训练和测试列表。每次阅读卷时, 你都将遍历3D卷的全部207个切片, 并将每个切片一个接一个地追加到列表中。
for f in ff:
temp = np.zeros([resizeTo, full_z, resizeTo])
a = nib.load("../test_crossval1/" + f)
affine = a.affine
a = a.get_data()
temp[3:, :, 3:] = a
a = temp
for j in range(full_z):
predict_matrix.append(a[:, j, :])
for f in ff:
temp = np.zeros([resizeTo, full_z, resizeTo])
a = nib.load("../test_g_crossval1/" + f)
affine = a.affine
a = a.get_data()
temp[3:, :, 3:] = a
a = temp
for j in range(full_z):
ground_matrix.append(a[:, j, :])
数据预处理
由于3t和7T测试矩阵是一个列表, 因此你将使用numpy模块将列表转换为numpy数组。
此外, 你将把numpy数组的类型转换为float32, 并重新缩放输入和地面实况。
ToPredict_images = np.asarray(predict_matrix)
ToPredict_images = ToPredict_images.astype('float32')
mx = min_max[0]
mn = min_max[1]
ToPredict_images[:, :, :, 0] = (ToPredict_images[:, :, :, 0] - mn ) / (mx - mn)
ground_images = np.asarray(ground_matrix)
ground_images = ground_images.astype('float32')
ground_images[:, :, :, 0] = (ground_images[:, :, :, 0] - mn ) / (mx - mn)
接下来, 你将创建形状火车和测试矩阵的两个新变量ToPredict_images(3T测试/输入)和ground_images(7T测试/地面真实)。这将是一个4D矩阵, 其中第一个维度将是图像的总数, 第二个和第三个维度是每个图像的维度, 最后一个维度是通道数, 在这种情况下是一个。”
ToPredict_images=np.zeros(shape=[(ToPredict_images.shape[0]), (ToPredict_images.shape[1]), (ToPredict_images.shape[2]), (1)])
ground_images=np.zeros(shape=[(ground_images.shape[0]), (ground_images.shape[1]), (ground_images.shape[2]), (1)])
然后, 你将一个接一个地遍历所有图像, 每次将训练图和测试矩阵重塑为176 x 176并将其分别附加到ToPredict_images(3T测试/输入)和ground_images(7T测试/地面真相)时。
for i in range(ToPredict_images.shape[0]):
ToPredict_images[i, :, :, 0] = ToPredict_images[i, :, :].reshape(resizeTo, resizeTo)
for i in range(ground_images.shape[0]):
ground_images[i, :, :, 0] = ground_images[i, :, :].reshape(resizeTo, resizeTo)
该模型!
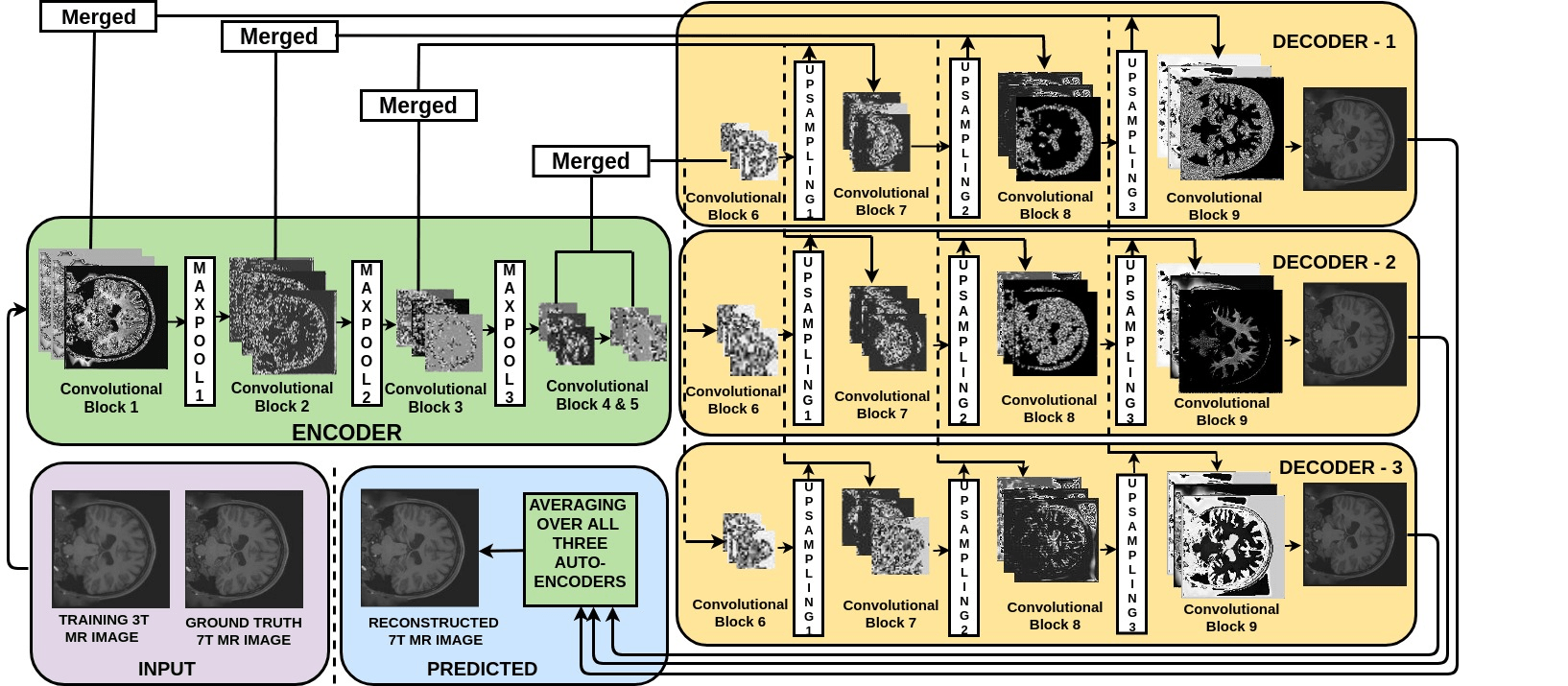
图:模型的架构
图片取自本文。
编码器
def encoder(input_img):
conv1 = Conv2D(32, (3, 3), activation='relu', padding='same')(input_img)
conv1 = BatchNormalization()(conv1)
conv1 = Conv2D(32, (3, 3), activation='relu', padding='same')(conv1)
conv1 = BatchNormalization()(conv1)
conv1 = Conv2D(32, (3, 3), activation='relu', padding='same')(conv1)
conv1 = BatchNormalization()(conv1)
pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
conv2 = Conv2D(64, (3, 3), activation='relu', padding='same')(pool1)
conv2 = BatchNormalization()(conv2)
conv2 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv2)
conv2 = BatchNormalization()(conv2)
conv2 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv2)
conv2 = BatchNormalization()(conv2)
pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
conv3 = Conv2D(128, (3, 3), activation='relu', padding='same')(pool2)
conv3 = BatchNormalization()(conv3)
conv3 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv3)
conv3 = BatchNormalization()(conv3)
conv3 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv3)
conv3 = BatchNormalization()(conv3)
pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
conv4 = Conv2D(256, (3, 3), activation='relu', padding='same')(pool3)
conv4 = BatchNormalization()(conv4)
conv4 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv4)
conv4 = BatchNormalization()(conv4)
conv4 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv4)
conv4 = BatchNormalization()(conv4)
conv5 = Conv2D(512, (3, 3), activation='relu', padding='same')(conv4)
conv5 = BatchNormalization()(conv5)
conv5 = Conv2D(512, (3, 3), activation='relu', padding='same')(conv5)
conv5 = BatchNormalization()(conv5)
conv5 = Conv2D(512, (3, 3), activation='sigmoid', padding='same')(conv5)
conv5 = BatchNormalization()(conv5)
return conv5, conv4, conv3, conv2, conv1
解码器
def decoder(conv5, conv4, conv3, conv2, conv1):
up6 = merge([conv5, conv4], mode='concat', concat_axis=3)
conv6 = Conv2D(256, (3, 3), activation='relu', padding='same')(up6)
conv6 = BatchNormalization()(conv6)
conv6 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv6)
conv6 = BatchNormalization()(conv6)
conv6 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv6)
conv6 = BatchNormalization()(conv6)
up7 = UpSampling2D((2, 2))(conv6)
up7 = merge([up7, conv3], mode='concat', concat_axis=3)
conv7 = Conv2D(128, (3, 3), activation='relu', padding='same')(up7)
conv7 = BatchNormalization()(conv7)
conv7 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv7)
conv7 = BatchNormalization()(conv7)
conv7 = Conv2D(128, (3, 3), activation='relu', padding='same')(conv7)
conv7 = BatchNormalization()(conv7)
up8 = UpSampling2D((2, 2))(conv7)
up8 = merge([up8, conv2], mode='concat', concat_axis=3)
conv8 = Conv2D(64, (3, 3), activation='relu', padding='same')(up8)
conv8 = BatchNormalization()(conv8)
conv8 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv8)
conv8 = BatchNormalization()(conv8)
conv8 = Conv2D(64, (3, 3), activation='relu', padding='same')(conv8)
conv8 = BatchNormalization()(conv8)
up9 = UpSampling2D((2, 2))(conv8)
up9 = merge([up9, conv1], mode='concat', concat_axis=3)
conv9 = Conv2D(32, (3, 3), activation='relu', padding='same')(up9)
conv9 = BatchNormalization()(conv9)
conv9 = Conv2D(32, (3, 3), activation='relu', padding='same')(conv9)
conv9 = BatchNormalization()(conv9)
conv9 = Conv2D(32, (3, 3), activation='relu', padding='same')(conv9)
conv9 = BatchNormalization()(conv9)
decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(conv9)
return decoded
损失函数
接下来, 你将采用均方误差, 其中将排除等于零的地面真实值y_t和y_p的值(像素)。
def root_mean_sq_GxGy(y_t, y_p):
a1=1
zero = tf.constant(0, dtype=tf.float32)
where = tf.not_equal(y_t, zero)
a_t=tf.boolean_mask(y_t, where, name='boolean_mask')
a_p=tf.boolean_mask(y_p, where, name='boolean_mask')
return a1*(K.sqrt(K.mean((K.square(a_t-a_p)))))
三个自动编码器中的型号定义和负载权重!
首先, 我们将输入传递给编码器函数。由于在体系结构中使用合并连接, 因此编码器功能将返回五个卷积层的输出, 然后将它们与所有三个解码器输出分别合并。
conv5, conv4, conv3, conv2, conv1 = encoder(input_img)
现在, 让我们创建三个不同的模型, 并将三个训练有素的模型权重加载到其中。
autoencoder_1 = Model(input_img, decoder(conv5, conv4, conv3, conv2, conv1))
autoencoder_1.load_weights("../Model/CROSSVAL1/CROSSVAL1_AE1.h5")
autoencoder_2 = Model(input_img, decoder(conv5, conv4, conv3, conv2, conv1))
autoencoder_2.load_weights("../Model/CROSSVAL1/CROSSVAL1_AE2.h5")
autoencoder_3 = Model(input_img, decoder(conv5, conv4, conv3, conv2, conv1))
autoencoder_3.load_weights("../Model/CROSSVAL1/CROSSVAL1_AE3.h5")
测试量的模型预测:定量和定性结果!
让我们快速初始化两个numpy数组, 每个数组的大小为11 x 3 x 1, 其中第一个维表示用于测试模型的卷数。第二维表示介于以下之间的MSE和PSNR:预测输出7T MR图像和地面真实7T MR图像, 预测输出和输入3T MR图像, 输入3T MR图像和地面真实7T MR图像;第三维代表将输入模型的通道数!
mse= np.zeros([11, 3, 1])
psnr= np.zeros([11, 3, 1])
i=0 #for iterating over the slices of all the 11 volumes
在单元的下一部分, 你将一个接一个地遍历所有11个卷。在每次迭代中, 你将使用所有三个自动编码器预测每个音量, 并最终对预测进行平均。
在每个卷中, 你将遍历该卷的通道数, 并如上所述计算三种不同情况的PSNR和MSE。
然后使用nibabel库, 将预测的输出, 输入(3T)和地面真实情况(7T)保存为.nii格式文件:11个卷中的每一个都包含207个切片。
最后, 你将使用numpy库将PSNR矩阵保存在文本文件中。
如该论文所述, 对预测输出进行平均有助于减少噪声影响, 但保留了重建图像中的局部特征, 因此, PSNR优于单个解码器输出。
for j in range(11):
decoded_imgs_1 = autoencoder_1.predict(ToPredict_images[i:i+207, :, :, :])
decoded_imgs_2 = autoencoder_2.predict(ToPredict_images[i:i+207, :, :, :])
decoded_imgs_3 = autoencoder_3.predict(ToPredict_images[i:i+207, :, :, :])
decoded_imgs = np.mean( np.array([ decoded_imgs_1, decoded_imgs_2, decoded_imgs_3 ]), axis=0 )
for channel in range(1):
mse[j, 0, channel]= np.mean((ground_images[i:i+207, :, :, channel] - decoded_imgs[:, :, :, channel]) ** 2)
psnr[j, 0, channel] = 20 * math.log10( 1.0 / math.sqrt(mse[j, 0, channel]))
mse[j, 1, channel]= np.mean((ground_images[i:i+207, :, :, channel] - ToPredict_images[i:i+207, :, :, channel])** 2)
psnr[j, 1, channel] = 20 * math.log10( 1.0 / math.sqrt(mse[j, 1, channel]))
mse[j, 2, channel] = np.mean((ToPredict_images[i:i+207, :, :, channel] - decoded_imgs[:, :, :, channel]) ** 2)
checklt = math.sqrt(mse[j, 2, channel])
psnr[j, 2, channel] = 20 * math.log10( 1.0 / math.sqrt(mse[j, 2, channel]))
obj = nib.Nifti1Image(decoded_imgs, affine)
string =str(j)+'_crossval1.nii'
nib.save(obj, save + string)
obj = nib.Nifti1Image(ground_images[i:i+207, :, :, :], affine)
string =str(j)+'_ground_images_crossval1.nii'
nib.save(obj, save + string)
obj = nib.Nifti1Image(ToPredict_images[i:i+207, :, :, :], affine)
string =str(j)+'_ToPredict_images_crossval1.nii'
nib.save(obj, save + string)
i=i+207
np.savetxt('psnr_all_slices.txt', psnr[:, :, 0])
如果你想了解有关Python的更多信息, 请参加srcmini的”使用Python进行数据可视化入门”课程。
评论前必须登录!
注册