 srcmini
srcmini本文概述
K最近邻(K Nearest Neighbor, KNN)是一种非常简单, 易于理解, 通用且是最顶级的机器学习算法之一。 KNN用于各种应用程序, 例如金融, 医疗保健, 政治学, 手写检测, 图像识别和视频识别。在信用评级中, 金融机构将预测客户的信用评级。在贷款支付中, 银行机构将预测贷款是安全还是有风险。在政治学中, 将潜在选民分为两类将投票或不会投票。 KNN算法用于分类和回归问题。基于特征相似度的KNN算法。
在本教程中, 你将涵盖以下主题:
- K最近邻算法
- KNN算法如何工作?
- 渴望与懒惰的学习者
- 你如何确定KNN中的邻数量?
- 维度诅咒
- Scikit-learn中的分类器构建
- 利弊
- 如何提高KNN性能?
- 总结
K最近邻

KNN是一种非参数的惰性学习算法。非参数意味着没有基础数据分布的假设。换句话说, 模型结构是从数据集中确定的。这在大多数现实世界数据集不遵循数学理论假设的实践中将非常有帮助。惰性算法意味着它不需要任何训练数据点即可生成模型。测试阶段使用的所有培训数据。这使得培训更快, 而测试阶段又慢又昂贵。昂贵的测试阶段意味着时间和内存。在最坏的情况下, KNN需要更多的时间来扫描所有数据点, 并且扫描所有数据点将需要更多的内存来存储训练数据。
KNN算法如何工作?
在KNN中, K是最近邻的数量。邻数量是核心决定因素。如果类数为2, 则K通常为奇数。当K = 1时, 该算法称为最近邻算法。这是最简单的情况。假设P1是标签需要预测的点。首先, 找到最接近P1的一个点, 然后找到分配给P1的最近点的标签。
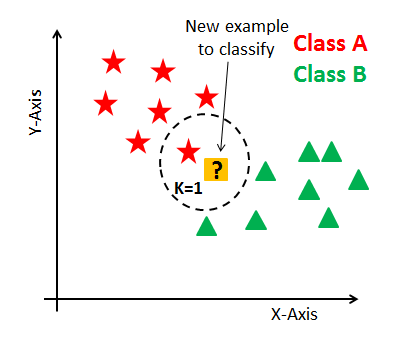
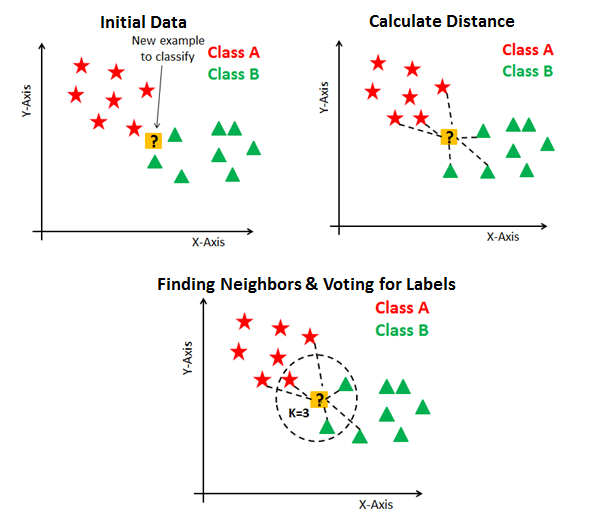
假设P1是标签需要预测的点。首先, 找到最接近P1的k个点, 然后按其k个邻的多数票对点进行分类。每个对象为他们的班级投票, 并以投票数最多的班级作为预测。为了找到最接近的相似点, 你可以使用诸如欧几里得距离, 汉明距离, 曼哈顿距离和明可夫斯基距离之类的距离度量来找到点之间的距离。 KNN具有以下基本步骤:
- 计算距离
- 寻找最近的邻
- 投票给标签
渴望与懒惰的学习者
热切的学习者意味着, 在给定的新训练点进行分类之前, 何时给定的训练点将构建通用模型。你可以将这样的学习者视为已经准备好, 活跃并且渴望对未观察到的数据点进行分类。
惰性学习意味着无需学习或训练模型以及预测时使用的所有数据点。懒惰的学习者要等到最后一分钟才能对任何数据点进行分类。懒惰学习者仅存储训练数据集, 并等待直到需要执行分类。仅当看到测试元组时, 它才根据其与存储的训练元组的相似性执行泛化以对元组进行分类。与渴望学习的方法不同, 懒惰的学习者在训练阶段所做的工作更少, 而在测试阶段进行的工作更多, 从而可以进行分类。懒惰学习者也称为基于实例的学习者, 因为懒惰学习者存储训练点或实例, 并且所有学习均基于实例。
维度诅咒
与大量特征相比, KNN在具有较少特征的情况下表现更好。你可以说, 当功能数量增加时, 它需要更多的数据。尺寸增加还导致过度装配的问题。为避免过度拟合, 所需的数据将随着你增加尺寸数而成倍增长。这个更高维度的问题被称为”维度诅咒”。
为了解决维数诅咒的问题, 你需要在应用任何机器学习算法之前执行主成分分析, 或者也可以使用特征选择方法。研究表明, 在大尺度上, 欧几里得距离不再有用。因此, 你可以选择余弦相似度之类的其他度量, 这些度量受高维的影响明显较小。
你如何确定KNN中的邻数量?
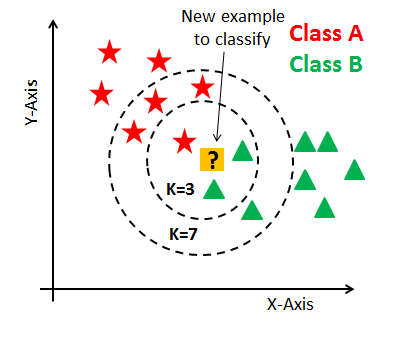
现在, 你了解了KNN算法的工作机制。此时, 出现了一个问题, 即如何选择最佳邻数?对分类器有什么影响? KNN中的近邻数(K)是在模型构建时需要选择的超参数。你可以将K视为预测模型的控制变量。
研究表明, 没有最佳的邻数量适合所有类型的数据集。每个数据集都有其自己的要求。在邻数量少的情况下, 噪声将对结果产生更大的影响, 并且邻数量很多使得计算量大。研究还表明, 少数邻是最灵活的拟合, 这将具有较低的偏见但方差高, 而大量邻的决策边界将更平滑, 这意味着方差较小但偏见较高。
通常, 如果类别数是偶数, 则数据科学家会选择一个奇数。你还可以通过在k的不同值上生成模型来检查并检查其性能。你也可以在这里尝试弯头方法。
Scikit-learn中的分类器构建
KNN分类器
定义数据集
首先创建你自己的数据集。在这里, 你需要数据中的两种属性或列:特征和标签。出现两种类型的列的原因是” KNN算法的监督性质”。
# Assigning features and label variables
# First Feature
weather=['Sunny', 'Sunny', 'Overcast', 'Rainy', 'Rainy', 'Rainy', 'Overcast', 'Sunny', 'Sunny', 'Rainy', 'Sunny', 'Overcast', 'Overcast', 'Rainy']
# Second Feature
temp=['Hot', 'Hot', 'Hot', 'Mild', 'Cool', 'Cool', 'Cool', 'Mild', 'Cool', 'Mild', 'Mild', 'Mild', 'Hot', 'Mild']
# Label or target varible
play=['No', 'No', 'Yes', 'Yes', 'Yes', 'No', 'Yes', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'No']
在此数据集中, 你具有两个功能(天气和温度)和一个标签(播放)。
编码数据列
各种机器学习算法都需要数字输入数据, 因此你需要在数字列中表示分类列。
为了对该数据进行编码, 可以将每个值映射到一个数字。例如多云:0, 阴雨:1, 晴天:2。
此过程称为标签编码, 而sklearn可以方便地使用Label Encoder为你完成此过程。
# Import LabelEncoder
from sklearn import preprocessing
#creating labelEncoder
le = preprocessing.LabelEncoder()
# Converting string labels into numbers.
weather_encoded=le.fit_transform(weather)
print(weather_encoded)
[2 2 0 1 1 1 0 2 2 1 2 0 0 1]
在这里, 你导入了预处理模块并创建了Label Encoder对象。使用此LabelEncoder对象, 你可以将”天气”列拟合并转换为数字列。
同样, 你可以对温度进行编码并在数字列中进行标签。
# converting string labels into numbers
temp_encoded=le.fit_transform(temp)
label=le.fit_transform(play)
组合功能
在这里, 你将使用” zip”功能将多个列或要素组合为一组数据
#combinig weather and temp into single listof tuples
features=list(zip(weather_encoded, temp_encoded))
产生模型
让我们构建KNN分类器模型。
首先, 导入KNeighborsClassifier模块, 并通过在KNeighborsClassifier()函数中传递邻的参数编号来创建KNN分类器对象。
然后, 使用fit()将模型拟合到训练集上, 并使用predict()对测试集执行预测。
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=3)
# Train the model using the training sets
model.fit(features, label)
#Predict Output
predicted= model.predict([[0, 2]]) # 0:Overcast, 2:Mild
print(predicted)
[1]
在上面的示例中, 你输入了[0, 2], 其中0表示阴天, 2表示温和。模型预测[1], 这意味着游戏。
具有多个标签的KNN
到目前为止, 你已经学习了如何使用scikit-learn在python中为两个创建KNN分类器。现在, 你将通过多个课程学习KNN。
在模型构建部分中, 你可以使用wine数据集, 这是一个非常著名的多类分类问题。该数据是使用三个不同品种对意大利同一地区种植的葡萄酒进行化学分析的结果。分析确定了三种葡萄酒中每种所含13种成分的数量。
数据集包含13个特征(“酒精”, “苹果酸”, “灰分”, “alcalinity_of_ash”, “镁”, “总酚”, “类黄酮”, “非类黄烷酚”, “原花青素”, “色强度”, “色相”, “ ‘od280 / od315_of_diluted_wines’, ‘脯氨酸’)和目标(品种类型)。
该数据具有三种类型的品种类别:” class_0″, ” class_1″和” class_2″。在这里, 你可以建立一个模型来对品种类型进行分类。该数据集在scikit-learn库中可用, 或者你也可以从UCI机器学习库中下载它。
加载数据中
让我们首先从scikit-learn数据集中加载所需的wine数据集。
#Import scikit-learn dataset library
from sklearn import datasets
#Load dataset
wine = datasets.load_wine()
探索数据
加载数据集后, 你可能想了解更多有关它的信息。你可以检查功能和目标名称。
# print the names of the features
print(wine.feature_names)
['alcohol', 'malic_acid', 'ash', 'alcalinity_of_ash', 'magnesium', 'total_phenols', 'flavanoids', 'nonflavanoid_phenols', 'proanthocyanins', 'color_intensity', 'hue', 'od280/od315_of_diluted_wines', 'proline']
# print the label species(class_0, class_1, class_2)
print(wine.target_names)
['class_0' 'class_1' 'class_2']
让我们检查功能集的前5条记录。
# print the wine data (top 5 records)
print(wine.data[0:5])
[[ 1.42300000e+01 1.71000000e+00 2.43000000e+00 1.56000000e+01
1.27000000e+02 2.80000000e+00 3.06000000e+00 2.80000000e-01
2.29000000e+00 5.64000000e+00 1.04000000e+00 3.92000000e+00
1.06500000e+03]
[ 1.32000000e+01 1.78000000e+00 2.14000000e+00 1.12000000e+01
1.00000000e+02 2.65000000e+00 2.76000000e+00 2.60000000e-01
1.28000000e+00 4.38000000e+00 1.05000000e+00 3.40000000e+00
1.05000000e+03]
[ 1.31600000e+01 2.36000000e+00 2.67000000e+00 1.86000000e+01
1.01000000e+02 2.80000000e+00 3.24000000e+00 3.00000000e-01
2.81000000e+00 5.68000000e+00 1.03000000e+00 3.17000000e+00
1.18500000e+03]
[ 1.43700000e+01 1.95000000e+00 2.50000000e+00 1.68000000e+01
1.13000000e+02 3.85000000e+00 3.49000000e+00 2.40000000e-01
2.18000000e+00 7.80000000e+00 8.60000000e-01 3.45000000e+00
1.48000000e+03]
[ 1.32400000e+01 2.59000000e+00 2.87000000e+00 2.10000000e+01
1.18000000e+02 2.80000000e+00 2.69000000e+00 3.90000000e-01
1.82000000e+00 4.32000000e+00 1.04000000e+00 2.93000000e+00
7.35000000e+02]]
让我们检查目标集的记录。
# print the wine labels (0:Class_0, 1:Class_1, 2:Class_3)
print(wine.target)
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
让我们进一步探索它。你也可以使用shape检查数据集的形状。
# print data(feature)shape
print(wine.data.shape)
(178, 13)
# print target(or label)shape
print(wine.target.shape)
(178, )
分割数据
为了了解模型的性能, 将数据集分为训练集和测试集是一个很好的策略。
让我们使用函数train_test_split()拆分数据集。你需要传递3个参数功能, 目标和test_set大小。此外, 你可以使用random_state随机选择记录。
# Import train_test_split function
from sklearn.model_selection import train_test_split
# Split dataset into training set and test set
X_train, X_test, y_train, y_test = train_test_split(wine.data, wine.target, test_size=0.3) # 70% training and 30% test
K = 5的生成模型
让我们为k = 5建立KNN分类器模型。
#Import knearest neighbors Classifier model
from sklearn.neighbors import KNeighborsClassifier
#Create KNN Classifier
knn = KNeighborsClassifier(n_neighbors=5)
#Train the model using the training sets
knn.fit(X_train, y_train)
#Predict the response for test dataset
y_pred = knn.predict(X_test)
k = 5的模型评估
让我们估计一下分类器或模型预测品种的准确程度。
可以通过比较实际测试设置值和预测值来计算准确性。
#Import scikit-learn metrics module for accuracy calculation
from sklearn import metrics
# Model Accuracy, how often is the classifier correct?
print("Accuracy:", metrics.accuracy_score(y_test, y_pred))
Accuracy: 0.685185185185
嗯, 你的分类率为68.51%, 被认为是不错的准确性。
为了进一步评估, 你还可以为不同数量的邻创建模型。
K = 7的重新生成模型
让我们为k = 7构建KNN分类器模型。
#Import knearest neighbors Classifier model
from sklearn.neighbors import KNeighborsClassifier
#Create KNN Classifier
knn = KNeighborsClassifier(n_neighbors=7)
#Train the model using the training sets
knn.fit(X_train, y_train)
#Predict the response for test dataset
y_pred = knn.predict(X_test)
k = 7的模型评估
让我们再次估计, 对于k = 7, 分类器或模型可以多么准确地预测品种的类型。
#Import scikit-learn metrics module for accuracy calculation
from sklearn import metrics
# Model Accuracy, how often is the classifier correct?
print("Accuracy:", metrics.accuracy_score(y_test, y_pred))
Accuracy: 0.777777777778
好吧, 你的分类率为77.77%, 被认为是不错的准确性。
在这里, 你增加了模型中的邻数量, 并且提高了准确性。但是, 对于许多邻的增加可以提高准确性的情况, 这并不是必需的。要对其进行更详细的了解, 可以参考”如何确定邻数?”部分。本教程。
优点
与其他分类算法相比, K近邻分类的训练阶段要快得多。无需训练用于泛化的模型, 这就是为什么KNN被称为简单的基于实例的学习算法的原因。在非线性数据的情况下, KNN可能很有用。它可以与回归问题一起使用。对象的输出值由k个最邻近值的平均值计算得出。
缺点
就时间和内存而言, K近邻分类的测试阶段较慢且较昂贵。它需要大的内存来存储整个训练数据集以进行预测。 KNN需要缩放数据, 因为KNN使用两个数据点之间的欧式距离来找到最近的邻。欧氏距离对大小敏感。高幅度的特征比低幅度的特征权重更大。 KNN也不适用于大尺寸数据。
如何改善KNN?
为了获得更好的结果, 强烈建议对数据进行相同比例的标准化。通常, 归一化范围在0到1之间。KNN不适合大尺寸数据。在这种情况下, 需要减小尺寸以提高性能。此外, 处理缺失的值将有助于我们改善结果。
总结
恭喜, 你已完成本教程的结尾!
在本教程中, 你学习了K最近邻算法。它是一个工作正常, 渴望而又懒惰的学习者, 它使用Python Scikit-learn包对葡萄酒数据集进行了维数诅咒, 模型构建和评估。此外, 还讨论了其优点, 缺点和性能改进建议。
我期待听到任何反馈或问题。你可以通过发表评论来提出问题, 我会尽力回答。
评论前必须登录!
注册