 srcmini
srcminiWeb抓取是一个术语, 用于描述使用程序或算法从Web提取和处理大量数据的过程。无论你是数据科学家, 工程师, 还是任何分析大量数据集的人员, 从网络中抓取数据的能力都是一项有用的技能。假设你是从网络上找到数据的, 没有直接下载的方法, 使用Python进行网络抓取是一项技巧, 你可以用来将数据提取成可以导入的有用形式。
在本教程中, 你将了解以下内容:
•使用Python的Beautiful Soup模块从网上提取数据
•使用Python的Pandas库进行数据处理和清理
•使用Python的Matplotlib库进行数据可视化
本教程中使用的数据集摘自2017年6月在俄勒冈州希尔斯伯勒举行的10K竞赛。具体地说, 你将分析10K赛跑者的表现并回答以下问题:
•跑步者的平均完成时间是多少?
•选手的完成时间是否服从正态分布?
•不同年龄段的男性和女性之间的表现是否存在差异?
使用Jupyter Notebook, 你应该首先导入必要的模块(pandas, numpy, matplotlib.pyplot, seaborn)。如果你没有安装Jupyter Notebook, 建议你使用Internet上可用的Anaconda Python发行版进行安装。要轻松显示图, 请确保包含行%matplotlib内联, 如下所示。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
要进行网页抓取, 你还应该导入如下所示的库。 urllib.request模块用于打开URL。 Beautiful Soup包用于从html文件提取数据。 Beautiful Soup库的名称是bs4, 代表Beautiful Soup版本4。
from urllib.request import urlopen
from bs4 import BeautifulSoup
导入必要的模块后, 你应指定包含数据集的URL, 并将其传递给urlopen()以获取页面的html。
url = "http://www.hubertiming.com/results/2017GPTR10K"
html = urlopen(url)
获取页面的html只是第一步。下一步是从html创建一个Beautiful Soup对象。这是通过将html传递给BeautifulSoup()函数来完成的。 Beautiful Soup包用于解析html, 即获取原始html文本并将其分解为Python对象。第二个参数” lxml”是html解析器, 你现在无需担心其详细信息。
soup = BeautifulSoup(html, 'lxml')
type(soup)
bs4.BeautifulSoup
通过汤对象, 你可以提取有关要剪贴的网站的有趣信息, 例如获取页面标题, 如下所示。
# Get the title
title = soup.title
print(title)
<title>2017 Intel Great Place to Run 10K \ Urban Clash Games Race Results</title>
你还可以获取网页文本并快速将其打印出来, 以检查其是否符合你的期望。
# Print out the text
text = soup.get_text()
#print(soup.text)
你可以通过右键单击网页上的任意位置并选择”检查”来查看网页的html。这就是结果的样子。
你可以使用汤的find_all()方法在网页中提取有用的html标签。有用的标签示例包括<a>(用于超链接), <table>(用于表), <tr>(用于表行), <th>(用于表头)和<td>(用于表单元格)。下面的代码显示了如何提取网页中的所有超链接。
soup.find_all('a')
[<a class="btn btn-primary btn-lg" href="/results/2017GPTR" role="button">5K</a>, <a href="http://hubertiming.com/">Huber Timing Home</a>, <a href="#individual">Individual Results</a>, <a href="#team">Team Results</a>, <a href="mailto:timing@hubertiming.com">timing@hubertiming.com</a>, <a href="#tabs-1" style="font-size: 18px">Results</a>, <a name="individual"></a>, <a name="team"></a>, <a href="http://www.hubertiming.com/"><img height="65" src="/sites/all/themes/hubertiming/images/clockWithFinishSign_small.png" width="50"/>Huber Timing</a>, <a href="http://facebook.com/hubertiming/"><img src="/results/FB-f-Logo__blue_50.png"/></a>]
从上面的输出中可以看到, html标记有时带有class, src等属性。这些属性提供有关html元素的其他信息。你可以使用for循环和get(‘” href”)方法仅提取和打印超链接。
all_links = soup.find_all("a")
for link in all_links:
print(link.get("href"))
/results/2017GPTR
http://hubertiming.com/
#individual
#team
mailto:timing@hubertiming.com
#tabs-1
None
None
http://www.hubertiming.com/
http://facebook.com/hubertiming/
要仅打印出表行, 请在soup.find_all()中传递’tr’参数。
# Print the first 10 rows for sanity check
rows = soup.find_all('tr')
print(rows[:10])
[<tr><td>Finishers:</td><td>577</td></tr>, <tr><td>Male:</td><td>414</td></tr>, <tr><td>Female:</td><td>163</td></tr>, <tr class="header">
<th>Place</th>
<th>Bib</th>
<th>Name</th>
<th>Gender</th>
<th>City</th>
<th>State</th>
<th>Chip Time</th>
<th>Chip Pace</th>
<th>Gender Place</th>
<th>Age Group</th>
<th>Age Group Place</th>
<th>Time to Start</th>
<th>Gun Time</th>
<th>Team</th>
</tr>, <tr>
<td>1</td>
<td>814</td>
<td>JARED WILSON</td>
<td>M</td>
<td>TIGARD</td>
<td>OR</td>
<td>00:36:21</td>
<td>05:51</td>
<td>1 of 414</td>
<td>M 36-45</td>
<td>1 of 152</td>
<td>00:00:03</td>
<td>00:36:24</td>
<td></td>
</tr>, <tr>
<td>2</td>
<td>573</td>
<td>NATHAN A SUSTERSIC</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:36:42</td>
<td>05:55</td>
<td>2 of 414</td>
<td>M 26-35</td>
<td>1 of 154</td>
<td>00:00:03</td>
<td>00:36:45</td>
<td>INTEL TEAM F</td>
</tr>, <tr>
<td>3</td>
<td>687</td>
<td>FRANCISCO MAYA</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:37:44</td>
<td>06:05</td>
<td>3 of 414</td>
<td>M 46-55</td>
<td>1 of 64</td>
<td>00:00:04</td>
<td>00:37:48</td>
<td></td>
</tr>, <tr>
<td>4</td>
<td>623</td>
<td>PAUL MORROW</td>
<td>M</td>
<td>BEAVERTON</td>
<td>OR</td>
<td>00:38:34</td>
<td>06:13</td>
<td>4 of 414</td>
<td>M 36-45</td>
<td>2 of 152</td>
<td>00:00:03</td>
<td>00:38:37</td>
<td></td>
</tr>, <tr>
<td>5</td>
<td>569</td>
<td>DEREK G OSBORNE</td>
<td>M</td>
<td>HILLSBORO</td>
<td>OR</td>
<td>00:39:21</td>
<td>06:20</td>
<td>5 of 414</td>
<td>M 26-35</td>
<td>2 of 154</td>
<td>00:00:03</td>
<td>00:39:24</td>
<td>INTEL TEAM F</td>
</tr>, <tr>
<td>6</td>
<td>642</td>
<td>JONATHON TRAN</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:39:49</td>
<td>06:25</td>
<td>6 of 414</td>
<td>M 18-25</td>
<td>1 of 34</td>
<td>00:00:06</td>
<td>00:39:55</td>
<td></td>
</tr>]
本教程的目的是从网页中获取表格并将其转换为数据框, 以便使用Python轻松进行操作。为此, 你应该首先以列表形式获取所有表行, 然后将该列表转换为数据框。下面是一个for循环, 它循环遍历表行并打印出行的单元格。
for row in rows:
row_td = row.find_all('td')
print(row_td)
type(row_td)
[<td>14TH</td>, <td>INTEL TEAM M</td>, <td>04:43:23</td>, <td>00:58:59 - DANIELLE CASILLAS</td>, <td>01:02:06 - RAMYA MERUVA</td>, <td>01:17:06 - PALLAVI J SHINDE</td>, <td>01:25:11 - NALINI MURARI</td>]
bs4.element.ResultSet
上面的输出显示每行都打印有嵌入在每行中的html标签。这不是你想要的。你可以使用Beautiful Soup或正则表达式删除html标签。
删除html标签的最简单方法是使用Beautiful Soup, 并且只需一行代码即可完成此操作。将感兴趣的字符串传递给BeautifulSoup()并使用get_text()方法提取不带有html标签的文本。
str_cells = str(row_td)
cleantext = BeautifulSoup(str_cells, "lxml").get_text()
print(cleantext)
[14TH, INTEL TEAM M, 04:43:23, 00:58:59 - DANIELLE CASILLAS, 01:02:06 - RAMYA MERUVA, 01:17:06 - PALLAVI J SHINDE, 01:25:11 - NALINI MURARI]
不建议使用正则表达式, 因为它需要几行代码, 而且很容易出错。它需要导入re(对于正则表达式)模块。下面的代码显示如何构建一个正则表达式, 以查找<td> html标记内的所有字符, 并为每个表行将它们替换为空字符串。首先, 通过传递与re.compile()匹配的字符串来编译正则表达式。点, 星号和问号(。*?)将与左尖括号匹配, 后跟任何内容, 再后跟右尖括号。它以非贪婪的方式匹配文本, 即, 它匹配最短的字符串。如果省略问号, 它将匹配第一个打开的尖括号和最后一个关闭的尖括号之间的所有文本。编译正则表达式后, 可以使用re.sub()方法查找与正则表达式匹配的所有子字符串, 并将它们替换为空字符串。下面的完整代码生成一个空列表, 在每行的html标记之间提取文本, 并将其附加到分配的列表中。
import re
list_rows = []
for row in rows:
cells = row.find_all('td')
str_cells = str(cells)
clean = re.compile('<.*?>')
clean2 = (re.sub(clean, '', str_cells))
list_rows.append(clean2)
print(clean2)
type(clean2)
[14TH, INTEL TEAM M, 04:43:23, 00:58:59 - DANIELLE CASILLAS, 01:02:06 - RAMYA MERUVA, 01:17:06 - PALLAVI J SHINDE, 01:25:11 - NALINI MURARI]
str
下一步是将列表转换为数据框, 并使用Pandas快速查看前10行。
df = pd.DataFrame(list_rows)
df.head(10)
| 0 | |
|---|---|
| 0 | [Finishers :, 577] |
| 1 | [男:414] |
| 2 | [女:163] |
| 3 | [] |
| 4 | [1, 814, JARED WILSON, M, TIGARD, OR, 00:36:21 … |
| 5 | [2, 573, NATHAN A SUSTERSIC, M, 波特兰, 或, … |
| 6 | [3, 687, MAYA, M, PORTLAND, OR, 00:3 … |
| 7 | [4, 623, PAUL MORROW, M, BEAVERTON, OR, 00:38:… |
| 8 | [5, 569, DEREK G OSBORNE, M, HILLSBORO, OR, 00 … |
| 9 | [6, 642, JONATHON TRAN, M, PORTLAND, OR, 00:39 … |
数据框不是我们想要的格式。要清理它, 你应该在逗号位置将” 0″列拆分为多个列。这可以通过使用str.split()方法来完成。
df1 = df[0].str.split(', ', expand=True)
df1.head(10)
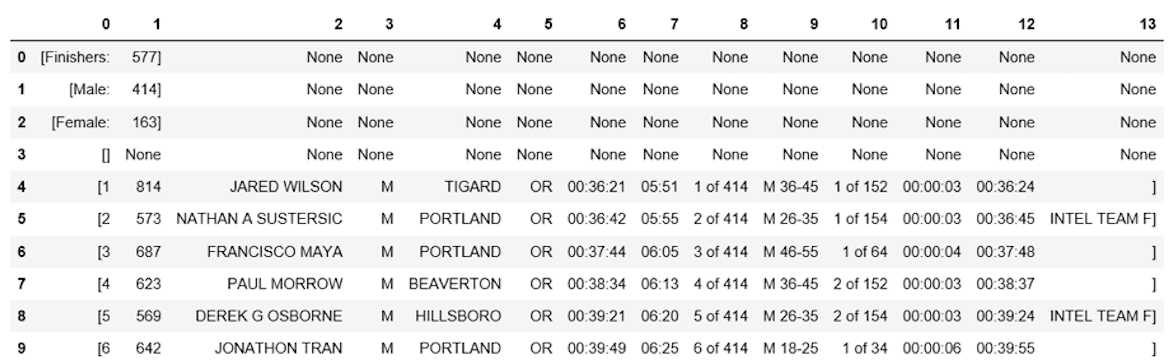
看起来好多了, 但仍有工作要做。数据框在每行周围都有多余的方括号。你可以使用strip()方法删除” 0″列上的方括号。
df1[0] = df1[0].str.strip('[')
df1.head(10)
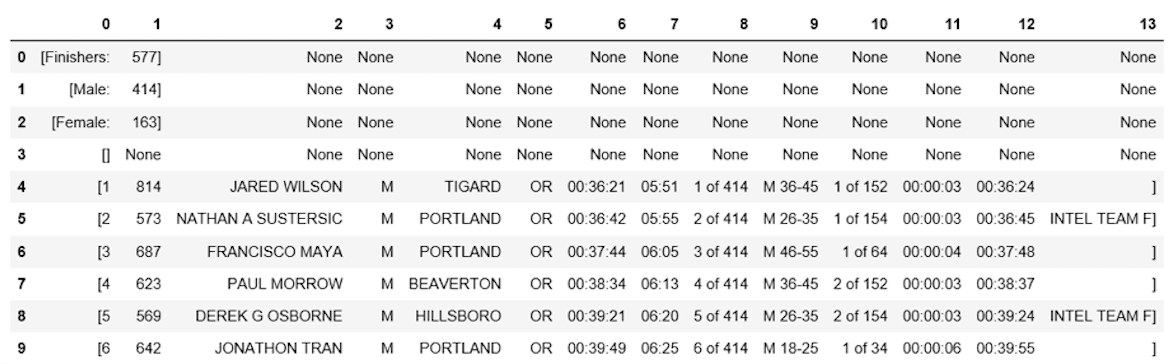
该表缺少表标题。你可以使用find_all()方法获取表头。
col_labels = soup.find_all('th')
与表格行类似, 你可以使用Beautiful Soup来提取表格标题的html标记之间的文本。
all_header = []
col_str = str(col_labels)
cleantext2 = BeautifulSoup(col_str, "lxml").get_text()
all_header.append(cleantext2)
print(all_header)
['[Place, Bib, Name, Gender, City, State, Chip Time, Chip Pace, Gender Place, Age Group, Age Group Place, Time to Start, Gun Time, Team]']
然后, 你可以将标头列表转换为pandas数据框。
df2 = pd.DataFrame(all_header)
df2.head()
| 0 | |
|---|---|
| 0 | [地点, 围兜, 姓名, 性别, 城市, 州, 芯片… |
同样, 你可以在所有行的逗号位置将” 0″列拆分为多列。
df3 = df2[0].str.split(', ', expand=True)
df3.head()

可以使用concat()方法将两个数据帧连接为一个, 如下所示。
frames = [df3, df1]
df4 = pd.concat(frames)
df4.head(10)
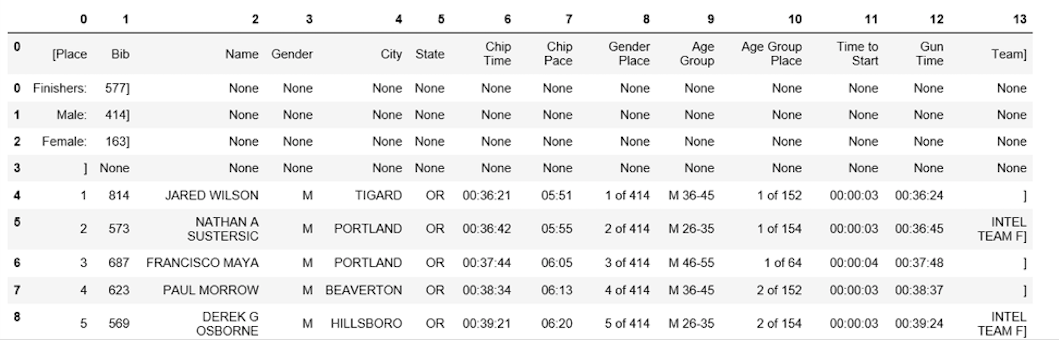
下面显示了如何将第一行分配为表标题。
df5 = df4.rename(columns=df4.iloc[0])
df5.head()

此时, 该表的格式几乎正确。为了进行分析, 你可以首先获取数据概述, 如下所示。
df5.info()
df5.shape
<class 'pandas.core.frame.DataFrame'>
Int64Index: 597 entries, 0 to 595
Data columns (total 14 columns):
[Place 597 non-null object
Bib 596 non-null object
Name 593 non-null object
Gender 593 non-null object
City 593 non-null object
State 593 non-null object
Chip Time 593 non-null object
Chip Pace 578 non-null object
Gender Place 578 non-null object
Age Group 578 non-null object
Age Group Place 578 non-null object
Time to Start 578 non-null object
Gun Time 578 non-null object
Team] 578 non-null object
dtypes: object(14)
memory usage: 70.0+ KB
(597, 14)
该表有597行和14列。你可以删除所有缺少任何值的行。
df6 = df5.dropna(axis=0, how='any')
另外, 请注意如何将表头复制为df5中的第一行。可以使用以下代码行将其删除。
df7 = df6.drop(df6.index[0])
df7.head()
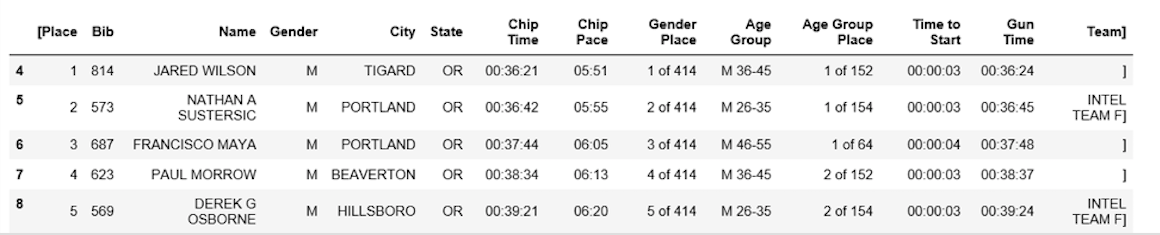
你可以通过重命名[[Place]和’Team]列来执行更多数据清理。 Python对空间非常挑剔。确保在”团队”中的引号后包括空格。
df7.rename(columns={'[Place': 'Place'}, inplace=True)
df7.rename(columns={' Team]': 'Team'}, inplace=True)
df7.head()

最后的数据清理步骤涉及删除”团队”列中单元格的右括号。
df7['Team'] = df7['Team'].str.strip(']')
df7.head()

花了一段时间才到达这里, 但是此时, 数据帧处于所需的格式。现在, 你可以继续进行令人兴奋的部分, 开始绘制数据并计算有趣的统计数据。
要回答的第一个问题是, 跑步者的平均完成时间(以分钟为单位)是多少?你需要将” Chip Time”一栏转换为几分钟。一种方法是首先将列转换为列表以进行操作。
time_list = df7[' Chip Time'].tolist()
# You can use a for loop to convert 'Chip Time' to minutes
time_mins = []
for i in time_list:
h, m, s = i.split(':')
math = (int(h) * 3600 + int(m) * 60 + int(s))/60
time_mins.append(math)
#print(time_mins)
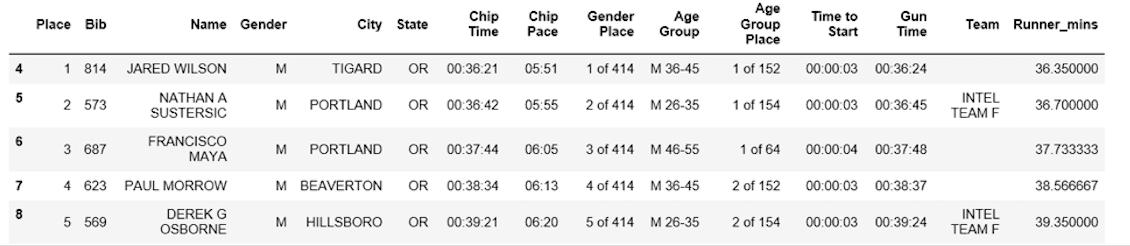
下一步是将列表转换回数据帧, 并创建新的列(” Runner_mins”), 以分钟为单位表示流道筹码时间。
df7['Runner_mins'] = time_mins
df7.head()
下面的代码显示了如何仅在数据框中计算数字列的统计信息。
df7.describe(include=[np.number])
| Runner_mins | |
|---|---|
| 计数 | 577.000000 |
| 意思 | 60.035933 |
| 小时 | 11.970623 |
| 我 | 36.350000 |
| 25% | 51.000000 |
| 50% | 59.016667 |
| 75% | 67.266667 |
| 最大值 | 101.300000 |
有趣的是, 所有选手的平均筹码时间约为60分钟。最快的10K跑者在36.35分钟内完成, 最慢的跑者在101.30分钟内完成。
箱线图是另一个有用的工具, 用于可视化摘要统计信息(最大值, 最小值, 中等, 第一四分位数, 第三四分位数, 包括异常值)。以下是箱形图中显示的跑步者的数据摘要统计信息。为了进行数据可视化, 首先从matplotlib随附的pylab模块中导入参数, 然后为所有图形设置相同的大小, 以避免对每个图形都这样做是很方便的。
from pylab import rcParams
rcParams['figure.figsize'] = 15, 5
df7.boxplot(column='Runner_mins')
plt.grid(True, axis='y')
plt.ylabel('Chip Time')
plt.xticks([1], ['Runners'])
([<matplotlib.axis.XTick at 0x570dd106d8>], <a list of 1 Text xticklabel objects>)

要回答的第二个问题是:跑步者的完成时间是否服从正态分布?
下面是使用seaborn库绘制的跑步者筹码时间分布图。该分布看起来几乎是正常的。
x = df7['Runner_mins']
ax = sns.distplot(x, hist=True, kde=True, rug=False, color='m', bins=25, hist_kws={'edgecolor':'black'})
plt.show()

第三个问题涉及各个年龄段的男性和女性之间是否存在性能差异。以下是男性和女性的筹码时间分布图。
f_fuko = df7.loc[df7[' Gender']==' F']['Runner_mins']
m_fuko = df7.loc[df7[' Gender']==' M']['Runner_mins']
sns.distplot(f_fuko, hist=True, kde=True, rug=False, hist_kws={'edgecolor':'black'}, label='Female')
sns.distplot(m_fuko, hist=False, kde=True, rug=False, hist_kws={'edgecolor':'black'}, label='Male')
plt.legend()
<matplotlib.legend.Legend at 0x570e301fd0>

分布表明, 女性平均比男性慢。你可以使用groupby()方法分别计算男性和女性的摘要统计信息, 如下所示。
g_stats = df7.groupby(" Gender", as_index=True).describe()
print(g_stats)
Runner_mins \
count mean std min 25% 50%
Gender
F 163.0 66.119223 12.184440 43.766667 58.758333 64.616667
M 414.0 57.640821 11.011857 36.350000 49.395833 55.791667
75% max
Gender
F 72.058333 101.300000
M 64.804167 98.516667
所有女性和男性的平均削片时间分别为〜66分钟和〜58分钟。以下是男性完成时间和女性完成时间的并排箱线图比较。
df7.boxplot(column='Runner_mins', by=' Gender')
plt.ylabel('Chip Time')
plt.suptitle("")
C:\Users\smasango\AppData\Local\Continuum\anaconda3\lib\site-packages\numpy\core\fromnumeric.py:57: FutureWarning: reshape is deprecated and will raise in a subsequent release. Please use .values.reshape(...) instead
return getattr(obj, method)(*args, **kwds)
Text(0.5, 0.98, '')

在本教程中, 你使用Python执行了Web抓取。你使用了Beautiful Soup库解析了html数据并将其转换为可用于分析的形式。你使用Python进行了数据清理并创建了有用的图(箱形图, 条形图和分布图), 以使用Python的matplotlib和seaborn库揭示有趣的趋势。学习完本教程后, 你应该能够使用Python轻松地从Web上抓取数据, 应用清理技术并从数据中提取有用的见解。
如果你想了解有关Python的更多信息, 请参加srcmini的免费的Python数据科学入门课程。
评论前必须登录!
注册