 srcmini
srcmini在我先前关于模型可解释性的文章中, 我概述了用于研究机器学习模型的常用技术。在此博客文章中, 我将提供有关LIME的更详尽的说明。
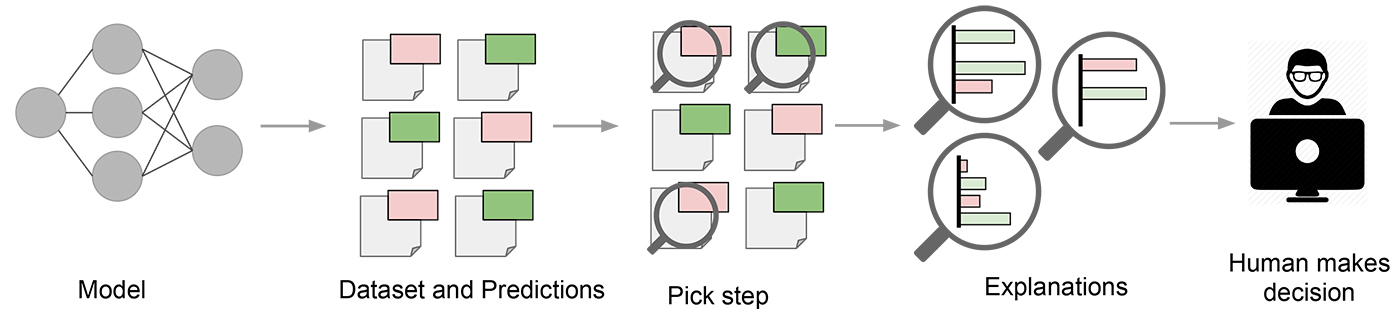
LIME在数据样本级别解释了模型预测。它允许最终用户解释这些预测并根据这些预测采取行动。资源
为什么需要理解可解释性方法?
如果你相信一种可以解释模型预测的技术, 那么了解该技术的基本机制以及与之相关的任何潜在陷阱就很重要。可解释性技术不能证明是错误的, 并且如果没有对该方法的充分理解, 你很可能会将你的假设基于虚假事实。
在以下有关随机森林重要性的博客文章中, 进行了类似但明显更彻底的调查。特征重要性通常用于确定哪些特征在模型预测中起重要作用。随机森林提供了一种开箱即用的方法来确定数据集中最重要的特征, 许多人依赖这些特征的重要性, 将其解释为数据集的”基本事实”。
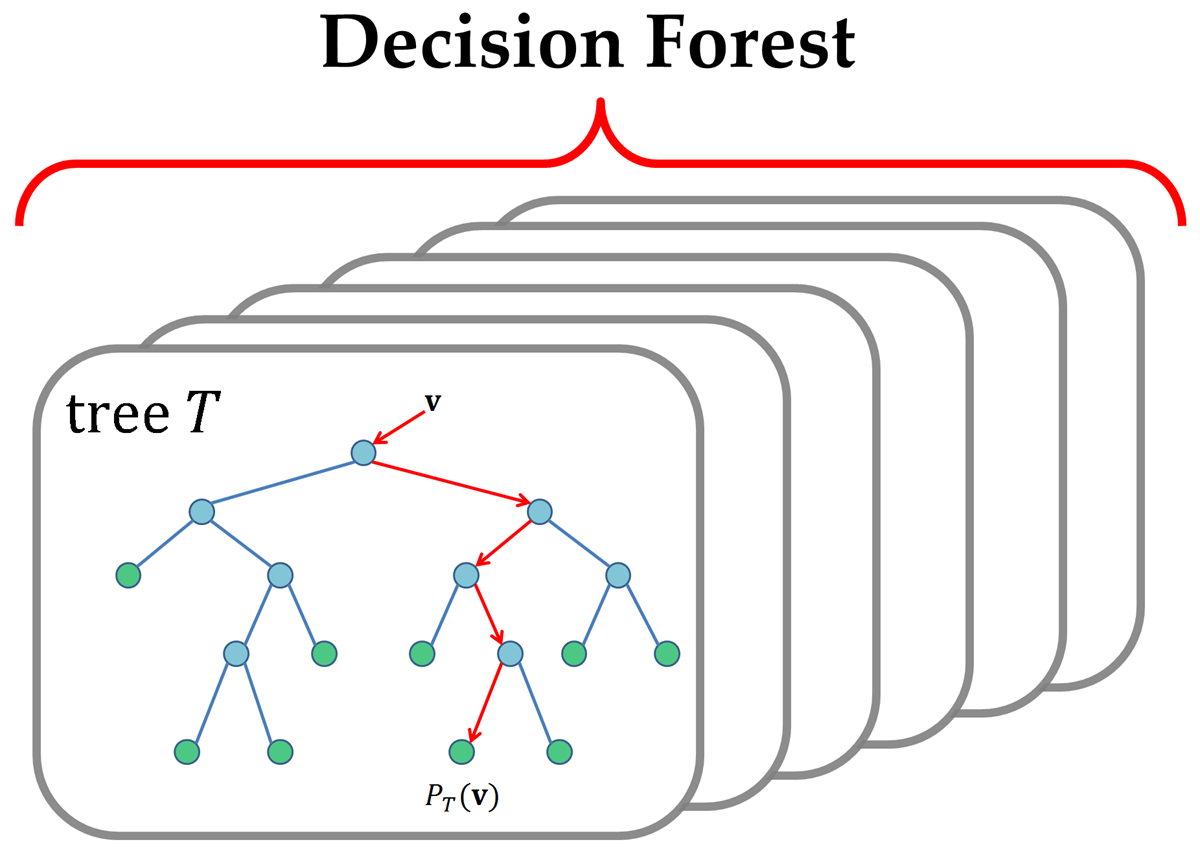
一个决策或随机森林由多个决策树组成。通过研究用于构建”最佳”树的要素, 可以估算要素的重要性。资源
作者研究了两种随机森林(RF)实施方案以及它们提供的功能重要性的标准度量。作者表明, 与随机森林重要性相比, 当变量具有高度相关性时, 排列重要性提供了更可靠的估计。我强烈建议阅读他们的博客文章, 以全面了解调查结果。
LIME
LIME与模型无关, 这意味着它可以应用于任何机器学习模型。该技术试图通过扰动数据样本的输入并理解预测的变化来理解模型。

LIME假设一个黑匣子机器学习模型, 并研究由模型表示的输入和输出之间的关系。
特定于模型的方法旨在通过分析内部组件及其相互作用来了解黑色模型机器学习模型。在深度学习模型中, 例如可以研究激活单元并将内部激活链接回输入。这需要对网络有透彻的了解, 并且不能扩展到其他模型。
LIME提供本地模型的可解释性。 LIME通过调整特征值来修改单个数据样本, 并观察结果对输出的影响。通常, 这也与人类在观察模型输出时感兴趣的内容有关。最常见的问题可能是:为什么要进行此预测, 或者是由哪些变量引起的预测?
其他模型可解释性技术仅从整个数据集的角度回答上述问题。功能重要性在数据集级别上说明哪些功能很重要。它使你可以验证假设以及模型是否过拟合噪声, 但是很难诊断特定的模型预测。
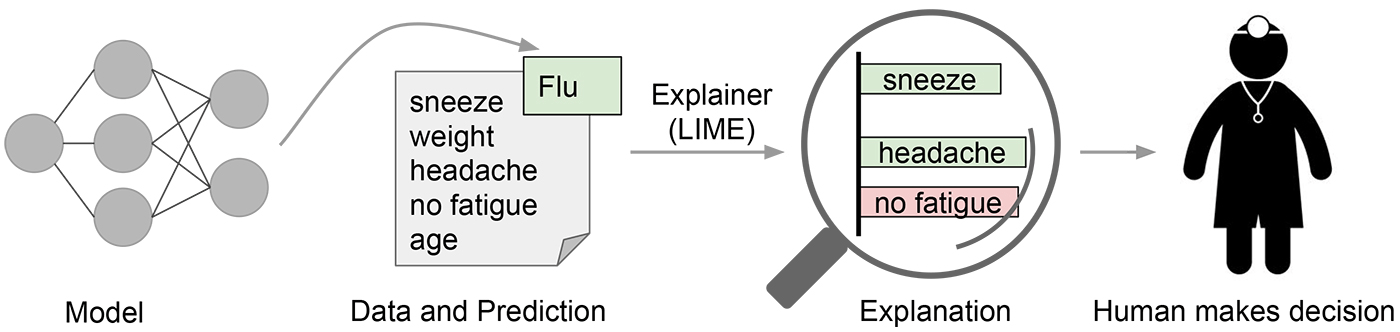
LIME试图扮演”解释者”的角色, 解释每个数据样本的预测。资源
LIME背后的直觉
LIME的一个关键要求是使用人类可以理解的可解释的输入表示形式。可解释表示的例子是例如NLP的BoW向量, 或计算机视觉的图像。另一方面, 密集的嵌入或无法解释, 而应用LIME可能不会提高解释性。
LIME的输出是一个解释列表, 反映了每个功能对数据样本预测的贡献。这提供了局部可解释性, 并且还允许确定哪些特征更改将对预测产生最大影响。

LIME应用于经典分类问题的示例。资源
通过使用可解释的模型在本地近似基础模型来创建一种解释。可解释的模型例如具有强正则化, 决策树等的线性模型。可解释模型是对原始实例的小扰动进行训练的, 仅应提供良好的局部逼近度。 “数据集”是由为连续特征添加噪点, 删除单词或隐藏图像的一部分。通过仅局部(在数据样本附近)近似黑匣子, 任务得到了显着简化。
潜在的陷阱
尽管LIME的一般想法听起来很简单, 但是有两个潜在的缺点。
在当前的实现中, 仅使用线性模型来近似局部行为。在某种程度上, 当查看数据样本周围很小的区域时, 此假设是正确的。但是, 通过扩展该区域, 线性模型可能不够强大, 无法解释原始模型的行为。对于那些需要复杂的, 不可解释的模型的数据集, 局部区域会发生非线性。无法在这些情况下应用LIME是一个重大陷阱。
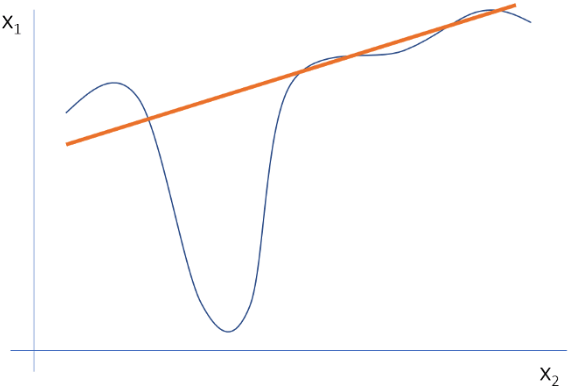
两个特征的局部行为的线性近似不能很好地表示, 也无法捕获模型的高度非线性行为。
其次, 需要对数据进行修改以获得正确解释的类型通常是特定于使用案例的。作者在其论文中提供了以下示例:例如, 无法通过超像素的存在来解释预测棕褐色图像将逆转的模型。
通常, 简单的干扰是不够的。理想情况下, 扰动将由数据集中观察到的变化驱动。手动操纵另一个扰动可能不是一个好主意, 因为它很可能会在模型说明中引入偏差。
总结
LIME是解释机器学习分类器(或模型)正在做什么的一个很好的工具。它与模型无关, 利用简单易懂的想法, 无需花费很多精力即可运行。与往常一样, 即使使用LIME, 正确解释输出也很重要。
如果你对机器学习的可解释性有任何疑问, 欢迎在评论中阅读。如果你想接收我的博客文章的更新, 请在Medium或Twitter上关注我!
如果你有兴趣学习有关建模的更多信息, 请参加srcmini的R统计课程。
评论前必须登录!
注册