 srcmini
srcmini本文概述

聚类是一种无监督的学习技术。任务是将一组对象组合在一起, 以使同一群集中的对象彼此之间的相似性高于其他群集中的对象。相似度是反映两个数据对象之间关系强度的量。聚类主要用于探索性数据挖掘。它用于许多领域, 例如机器学习, 模式识别, 图像分析, 信息检索, 生物信息学, 数据压缩和计算机图形学。
在本教程中, 你将看到:
- 首先, 你将了解不同类型的集群:硬集群和软集群
- 接下来, 你将研究聚类方法的类型, 例如基于连接性, 质心, 分布和密度的聚类。
- 然后, 你将了解k-means聚类算法, 这是基于质心的聚类示例。你将进行案例研究, 以了解使用R在Uber数据集上的k均值的工作情况。该数据集是免费提供的, 其中包含有关Uber取件的原始数据, 以及诸如日期, 旅行时间以及经度-纬度信息。你可以在此数据集上应用聚类, 以识别纽约内的不同行政区。
确保检查出srcmini的R课程无监督学习。该课程深入探讨了使用R进行无监督学习的概念。你将深入了解k均值和层次聚类。你还将学习主成分分析(PCA), 这是机器学习中降维的常用方法。
聚类:类型
聚类可以大致分为两个子组:
- 硬群集:在硬群集中, 每个数据对象或点都完全属于或不属于某个群集。例如, 在Uber数据集中, 每个位置都属于一个区或另一个区。
- 软聚类:在软聚类中, 一个数据点可以属于多个具有一定概率或似然值的聚类。例如, 你可以将某些位置标识为属于两个或多个行政区的边界点。
聚类算法
可以基于聚类算法的聚类模型对聚类算法进行分类, 聚类算法基于聚类算法如何形成聚类或组。本教程仅重点介绍一些杰出的聚类算法。
- 基于连接的群集:此群集的主要思想是, 数据空间中较近的数据点比远处的数据点更相关(相似)。通过根据数据点的距离连接数据点来形成群集。在不同的距离处, 将形成不同的聚类并且可以使用树状图表示, 这揭示了为什么它们通常也被称为”层次聚类”。这些方法不会产生数据集的唯一分区, 而是会产生层次结构, 用户仍然需要从层次结构中选择想要聚类的级别来选择适当的聚类。它们对异常值的鲁棒性也不强, 这些异常值可能会显示为其他群集, 甚至导致其他群集合并。
- 基于质心的聚类:在这种类型的聚类中, 聚类由中心向量或质心表示。此质心可能不一定是数据集的成员。这是一种迭代聚类算法, 其中相似性的概念是通过数据点与聚类的质心的接近程度得出的。 k-means是基于质心的聚类, 你将在本教程的后面部分更详细地了解此主题。
- 基于分布的聚类:此聚类与统计非常相关:分布建模。聚类基于这样的概念, 即数据点属于某个分布(例如高斯分布)的可能性有多大。群集中的数据点属于同一分布。这些模型具有强大的理论基础, 但是它们经常遭受过度拟合的困扰。使用期望最大化算法的高斯混合模型是一种著名的基于分布的聚类方法。
- 基于密度的方法在数据空间中搜索数据点密度不同的区域。群集定义为与其他区域相比数据空间内密度更高的区域。稀疏区域中的数据点通常被认为是噪声和/或边界点。这些方法的缺点是它们期望某种密度指导或参数来检测聚类边界。 DBSCAN和OPTICS是一些基于密度的突出聚类。
一种统治一切的算法
既然你已经看到了各种类型的聚类算法, 那么最大的问题是:”如何识别要使用的正确算法?”
好吧, 很抱歉, 但是没有一种算法可以全部统治。错误的警报!
“在旁观者眼中就是集群!”
聚类是一项主观任务, 可以有多个正确的聚类算法。每种算法都遵循一套不同的规则来定义数据点之间的”相似性”。经常需要通过实验选择针对特定问题的最合适的聚类算法, 除非出于数学原因更倾向于使用一种聚类算法而不是另一种。算法在特定数据集上可能效果很好, 但对于另一种数据集则失败。
K均值聚类
在本部分中, 你将使用Uber数据集, 其中包含Uber为纽约市生成的数据。 Uber Technologies Inc.是一个点对点的乘车共享平台。如果你对Uber不太了解, 请不要担心, 你所需要知道的就是Uber平台将你与(cab)驱动程序联系在一起, 这些驱动程序可以将你带到你的命运。该数据可在Kaggle上免费获得。数据集包含有关Uber皮卡的原始数据, 包括日期, 行程时间以及经纬度信息。
纽约市有五个行政区:布鲁克林, 皇后区, 曼哈顿, 布朗克斯和史泰登岛。在此微型项目的最后, 你将在数据集上应用k均值聚类, 以更好地探索数据集并识别纽约内的不同自治市镇。一直以来, 你还将学习在总体上从事数据科学项目时应采取的各种步骤。
问题理解
任何城市的交通流量中都存储着很多信息。在位置上挖掘时, 这些数据可以提供有关城市主要景点的信息, 可以帮助我们了解城市的各个区域, 例如居民区, 办公室/学校区域, 高速公路等。这可以帮助政府和其他机构进行规划该市更好并相应地执行适当的规章制度。例如, 与高速公路区域相比, 学校和住宅区的速度限制有所不同。
随时间监控的数据可以帮助我们识别高峰时间, 假期, 天气的影响等。这些知识可用于更好的计划和交通管理。这在很大程度上会影响城市的效率, 还有助于避免灾难, 或者至少在发生事故后更快地重定向交通流。
但是, 这都是一个更大的问题。本教程仅专注于尝试解决使用k-means算法识别纽约市五个行政区的问题, 以便在学习如何解决数据科学问题的过程中更好地理解算法。
了解数据
你只需要使用2014年以来的Uber数据即可。你可以在上述Kaggle链接中找到以下.csv文件:
- uber-raw-data-apr14.csv
- uber-raw-data-may14.csv
- uber-raw-data-jun14.csv
- uber-raw-data-jul14.csv
- uber-raw-data-aug14.csv
- uber-raw-data-sep14.csv
本教程利用各种库。请记住, 在本地工作时, 可能必须安装它们。你可以使用install.packages()轻松地做到这一点。
现在让我们加载数据:
# Load the .csv files
apr14 <- read.csv("https://raw.githubusercontent.com/fivethirtyeight/uber-tlc-foil-response/master/uber-trip-data/uber-raw-data-apr14.csv")
may14 <- read.csv("https://raw.githubusercontent.com/fivethirtyeight/uber-tlc-foil-response/master/uber-trip-data/uber-raw-data-may14.csv")
jun14 <- read.csv("https://raw.githubusercontent.com/fivethirtyeight/uber-tlc-foil-response/master/uber-trip-data/uber-raw-data-jun14.csv")
jul14 <- read.csv("https://raw.githubusercontent.com/fivethirtyeight/uber-tlc-foil-response/master/uber-trip-data/uber-raw-data-jul14.csv")
aug14 <- read.csv("https://raw.githubusercontent.com/fivethirtyeight/uber-tlc-foil-response/master/uber-trip-data/uber-raw-data-aug14.csv")
sep14 <- read.csv("https://raw.githubusercontent.com/fivethirtyeight/uber-tlc-foil-response/master/uber-trip-data/uber-raw-data-sep14.csv")
让我们将所有数据文件绑定为一个。为此, 可以使用R中dplyr库下的bind_rows()函数。
library(dplyr)
data14 <- bind_rows(apr14, may14, jun14, jul14, aug14, sep14)
到现在为止还挺好!让我们对数据进行汇总, 以了解你要处理的内容。
summary(data14)
Date.Time Lat Lon Base
Length:4534327 Min. :39.66 Min. :-74.93 B02512: 205673
Class :character 1st Qu.:40.72 1st Qu.:-74.00 B02598:1393113
Mode :character Median :40.74 Median :-73.98 B02617:1458853
Mean :40.74 Mean :-73.97 B02682:1212789
3rd Qu.:40.76 3rd Qu.:-73.97 B02764: 263899
Max. :42.12 Max. :-72.07
数据集包含以下列:
- Date.Time:Uber提车的日期和时间;
- 纬度:优步皮卡的纬度;
- 朗:优步皮卡的经度;
- Base:与Uber提货相关的TLC基本公司代码。
资料准备
此步骤包括清理和重新排列数据, 以便你可以更轻松地对其进行处理。首先考虑数据集的稀疏性并检查丢失的数据量是一个好主意。
# VIM library for using 'aggr'
library(VIM)
# 'aggr' plots the amount of missing/imputed values in each column
aggr(data14)

如你所见, 数据集没有缺失值。但是, 对于实际数据集, 情况并非总是如此, 你必须决定如何处理这些值。一些流行的方法包括删除特定的行/列或用值的平均值替换。
你可以看到第一列是Date.Time。为了能够使用这些值, 你需要将它们分开。因此, 我们可以这样做, 你可以使用lubridate库。 Lubridate使你可以轻松地确定日期中年, 月和日的显示顺序并进行操作。
library(lubridate)
# Separate or mutate the Date/Time columns
data14$Date.Time <- mdy_hms(data14$Date.Time)
data14$Year <- factor(year(data14$Date.Time))
data14$Month <- factor(month(data14$Date.Time))
data14$Day <- factor(day(data14$Date.Time))
data14$Weekday <- factor(wday(data14$Date.Time))
data14$Hour <- factor(hour(data14$Date.Time))
data14$Minute <- factor(minute(data14$Date.Time))
data14$Second <- factor(second(data14$Date.Time))
#data14$date_time
data14$Month
让我们检查一下前几行, 看看现在我们的数据是什么样子…。
head(data14, n=10)
| 约会时间 | 岁月 | 罐头 | 基础 | 年 | 月 | 天 | 平日 | 小时 | 分钟 | 第二 |
|---|---|---|---|---|---|---|---|---|---|---|
| 2014-04-01 00:11:00 | 40.7690 | -73.9549 | 025 | 025 | 2014 | 4 | 1 | 3 | 0 | 11 | 0 |
| 2014-04-01 00:17:00 | 40.7267 | -74.0345 | 025 | 025 | 2014 | 4 | 1 | 3 | 0 | 17 | 0 |
| 2014-04-01 00:21:00 | 40.7316 | -73.9873 | 025 | 025 | 2014 | 4 | 1 | 3 | 0 | 21 | 0 |
| 2014-04-01 00:28:00 | 40.7588 | -73.9776 | 025 | 025 | 2014 | 4 | 1 | 3 | 0 | 28 | 0 |
| 2014-04-01 00:33:00 | 40.7594 | -73.9722 | 025 | 025 | 2014 | 4 | 1 | 3 | 0 | 33 | 0 |
| 2014-04-01 00:33:00 | 40.7383 | -74.0403 | 025 | 025 | 2014 | 4 | 1 | 3 | 0 | 33 | 0 |
| 2014-04-01 00:39:00 | 40.7223 | -73.9887 | 025 | 025 | 2014 | 4 | 1 | 3 | 0 | 39 | 0 |
| 2014-04-01 00:45:00 | 40.7620 | -73.9790 | 025 | 025 | 2014 | 4 | 1 | 3 | 0 | 45 | 0 |
| 2014-04-01 00:55:00 | 40.7524 | -73.9960 | 025 | 025 | 2014 | 4 | 1 | 3 | 0 | 55 | 0 |
| 2014-04-01 01:01:00 | 40.7575 | -73.9846 | 025 | 025 | 2014 | 4 | 1 | 3 | 1 | 1 | 0 |
太棒了!
对于此案例研究, 这是你需要全面了解数据以及使用k-means聚类进行数据操作的唯一方法。
现在是将你的数据分为训练和测试集的好时机。这是每个数据科学项目中的重要一步, 它是在训练集中训练模型, 确定所需参数的值并最终在测试集中测试模型。例如, 使用聚类算法时, 需要进行此划分, 以便可以识别诸如k的参数, k是k均值聚类中的聚类数。但是, 对于此案例研究, 你已经知道预期的群集数量, 即5 –纽约市的行政区数量。因此, 你不应使用传统方法, 而应主要使用有关学习k均值聚类的方法。
查看srcmini的Python机器学习:Scikit-Learn教程, 该项目可指导你完成使用Python的数据科学(机器学习)项目的所有步骤。你还将在本教程中使用k-means算法。
现在, 在同样使用R代码之前, 让我们了解一下k均值聚类算法…
R的K均值聚类
K-均值聚类是将给定数据集划分为k个聚类的最常用的无监督机器学习算法。在此, k表示群集的数量, 必须由用户提供。对于Uber数据集, 你已经知道k, 它是5或自治市镇数。对于Uber 2014数据集, k-means是一个不错的算法选择, 因为你不知道使问题不受监督的目标标签, 并且有一个预先指定的k值。
在这里, 你将使用聚类将接送点分类为各个区。当你想了解有关数据集的更多信息时, 将使用聚类的一般情况。因此, 你可以运行几次集群, 研究有趣的集群并记下你获得的一些见解。聚类更多地是一种工具, 可帮助你浏览数据集, 并且不应总是用作对数据进行分类的自动方法。因此, 你可能并不总是针对实际生产场景部署聚类算法。它们通常太不可靠, 仅凭一个群集就无法为你提供可以从数据集中提取的所有信息。
k均值聚类背后的基本思想是定义聚类, 以使总集群内变化(称为总集群内变化)最小化。有几种可用的k均值算法。但是, 标准算法将总簇内变化定义为项与相应质心之间的平方距离欧几里德距离的平方和:
$ W(C_ {k})= ∑_ {x_ {i}∈C_{k}}(x_ {i}-μ_{k})^ 2 $
其中:
-
$ x_ {i} $是属于群集$ C_ {k} $的数据点
-
$μ_{k} $是分配给群集$ C_ {k} $的点的平均值
将每个观测值$ x_ {i} $分配给一个给定的聚类, 以使观测值与其分配的聚类中心$μ_{k} $的平方距离之和最小。
让我们更系统地完成这些步骤:
- 指定k-要创建的集群数。
- 从数据集中随机选择k个对象作为初始聚类中心。
- 根据对象和质心之间的欧几里得距离, 将每个观测值分配给它们最近的质心。
- 对于k个群集中的每个群集, 通过计算群集中所有数据点的新平均值重新计算群集质心。
- 迭代最小化平方和内的总数。重复步骤3和步骤4, 直到质心不变或达到最大迭代次数(R使用10作为最大迭代次数的默认值)。
平方和之内的总和或集群内的总变化被定义为:
$ ∑_ {k = 1} ^ {k} W(C_ {k})= ∑_ {k = 1} ^ {k} ∑_ {x_ {i}∈C_{k}}(x_ {i}- μ_{k})^ 2 $
这是项目及其对应质心之间的平方欧几里得距离的总和上所有聚类的总和。
现在你已经了解了理论, 让我们实现算法并查看结果!
你可以在R中使用kmeans()函数。k值将设置为5。此外, 还有一个nstart选项, 它尝试进行多个初始配置并报告kmeans函数中最佳的配置。种子允许你为随机生成的数字创建起点, 这样, 每次运行代码时, 都会生成相同的答案。
set.seed(20)
clusters <- kmeans(data14[, 2:3], 5)
# Save the cluster number in the dataset as column 'Borough'
data14$Borough <- as.factor(clusters$cluster)
# Inspect 'clusters'
str(clusters)
List of 9
$ cluster : int [1:4534327] 3 4 4 3 3 4 4 3 4 3 ...
$ centers : num [1:5, 1:2] 40.7 40.8 40.8 40.7 40.7 ...
..- attr(*, "dimnames")=List of 2
.. ..$ : chr [1:5] "1" "2" "3" "4" ...
.. ..$ : chr [1:2] "Lat" "Lon"
$ totss : num 22107
$ withinss : num [1:5] 1386 1264 948 2787 1029
$ tot.withinss: num 7414
$ betweenss : num 14692
$ size : int [1:5] 145109 217566 1797598 1802301 571753
$ iter : int 4
$ ifault : int 0
- attr(*, "class")= chr "kmeans"
上面的列表是kmeans()函数的输出。让我们仔细看看一些重要的:
- cluster:整型向量(从1:k开始), 指示每个点分配到的集群。
- 中心:集群中心的矩阵。
- insss:簇内平方和的矢量, 每簇一个分量。
- tot.withinss:集群内的总平方和。即, sum(withinss)。
- 大小:每个群集中的点数。
让我们绘制一些图表以可视化数据以及k均值聚类的结果。
library(ggmap)
NYCMap <- get_map("New York", zoom = 10)
ggmap(NYCMap) + geom_point(aes(x = Lon[], y = Lat[], colour = as.factor(Borough)), data = data14) +
ggtitle("NYC Boroughs using KMean")
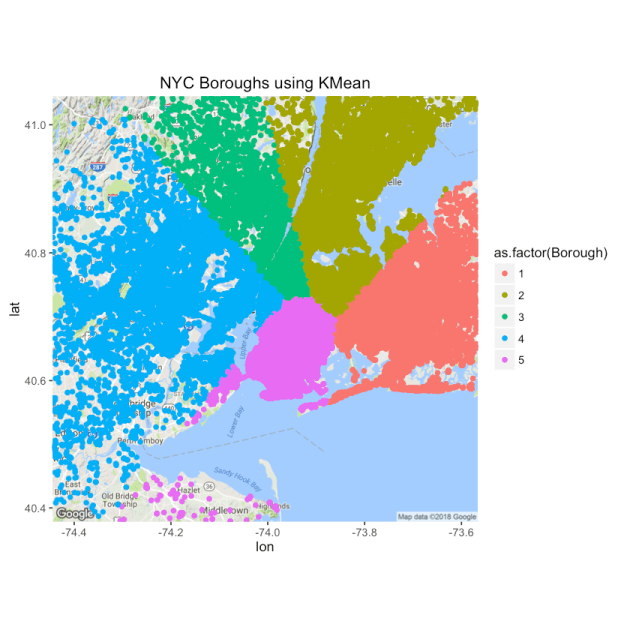
形成的区(集群)与真实区匹配。群集编号对应于以下自治市镇:
- 布朗克斯
- 曼哈顿
- 布鲁克林区
- 史泰登岛
- 皇后区
如你所见, 结果令人印象深刻。现在, 你已经使用k均值对拾取点进行了分类, 并将其他知识添加到了数据集中。让我们尝试使用这些新发现的知识来做一些事情。你可以使用自治市镇信息来查看Uber每个月在自治市镇内的增长情况。这是如何做…
library(DT)
data14$Month <- as.double(data14$Month)
month_borough_14 <- count_(data14, vars = c('Month', 'Borough'), sort = TRUE) %>%
arrange(Month, Borough)
datatable(month_borough_14)
让我们得到一个相同的图形视图…
library(dplyr)
monthly_growth <- month_borough_14 %>%
mutate(Date = paste("04", Month)) %>%
ggplot(aes(Month, n, colour = Borough)) + geom_line() +
ggtitle("Uber Monthly Growth - 2014")
monthly_growth

如你所见, k-means是一个很好的聚类算法。但是, 它有一些缺点。最大的缺点是它要求我们预先指定群集的数量(k)。但是, 对于Uber数据集, 你可以使用一些领域知识来告诉你纽约市的行政区数量。对于现实世界的数据集可能并非总是如此。分层集群是一种不需要特定选择集群的替代方法。 k均值的另一个缺点是, 它对异常值敏感, 如果更改数据的顺序, 则会出现不同的结果。
k-means是一个懒惰的学习者, 训练数据的泛化被延迟到对系统进行查询之前。这意味着k-means仅在你触发它时才开始起作用, 因此惰性学习方法可以针对每个遇到的查询为目标函数构造不同的近似值或结果。这是一种在线学习的好方法, 但是它可能需要大量的内存来存储数据, 并且每个请求都涉及从头开始识别本地模型。
做完了!
你了解了如何在使用k均值对拾取点进行分类以识别纽约市各个行政区时如何攻击数据科学项目的基本概述。你还使用了新发现的知识来进一步可视化各个市镇中Uber的增长。
你可以在无监督学习的情况下瞥见集群。分类是一项类似的任务, 但要进行监督学习。要了解更多信息, 请转到srcmini的R:分类学习课程。本课程涵盖四种最常见的分类算法。
评论前必须登录!
注册