 srcmini
srcmini本文概述
- 适用于大数据和机器学习的Apache Spark和Python
- 安装Apache Spark
- PySpark基础:RDD
- 数据
- 加载和浏览数据
- 数据探索
- 数据预处理
- 使用Spark ML构建机器学习模型
- 评估模型
- 你走之前…
- 进一步推动大数据
适用于大数据和机器学习的Apache Spark和Python
Apache Spark被称为用于大数据处理的快速, 易于使用的通用引擎, 它具有用于流, SQL, 机器学习(ML)和图形处理的内置模块。对于数据工程师来说, 这项技术是一项必不可少的技能, 但是当进行探索性数据分析(EDA), 特征提取, 当然还有ML时, 数据科学家也可以从学习Spark中受益。
在本教程中, 你将通过PySpark将Spark与Python交互, PySpark是将Python编程模型公开给Python的Spark Python API。更具体地说, 你将专注于
- 在你的个人计算机上本地安装PySpark并进行设置, 以便你可以使用交互式Spark Shell来对数据进行一些快速的交互式分析。你会通过Spark下载页面了解如何使用pip, 自制软件来执行此操作。
- 了解如何使用Spark基础知识:你将了解如何创建RDD并对其执行基本操作。
- Jupyter Notebook中的PySpark入门并加载实际数据集。
- 第一步, 在DataFrames的帮助下浏览并预处理加载的数据, 这要求你使用Spark SQL, 该SQL允许你在Spark程序中查询结构化数据。
- 使用Spark ML创建线性回归模型以向其中输入数据, 之后你就可以进行预测了。最后,
- 评估你制作的机器学习模型。

如果你对将Spark与R结合使用很感兴趣, 则应该查看srcmini的免费Spark简介R中的Spark简介, 或下载PySpark SQL备忘单。
安装Apache Spark
安装Spark并使之正常工作可能是一个挑战。在本节中, 你将介绍一些步骤, 这些步骤将向你展示如何在PC上安装它。
你要做的第一件事是检查你是否满足先决条件。 Spark用Scala编程语言编写, 并在Java虚拟机(JVM)环境中运行。因此, 你需要检查是否已安装Java开发套件(JDK)。这样做是因为JDK将为你提供JVM的一个或多个实现。最好, 你要选择最新的, 在撰写本文时为JDK8。
接下来, 你正在阅读下载Spark!
用pip下载pyspark
然后, 你可以在pip的帮助下下载并安装PySpark。这相当容易, 并且很像安装其他任何软件包。你只需运行通常的命令即可为你完成繁重的工作:
$ pip install pyspark或者, 你也可以转到Spark下载页面。保留前三个步骤中的默认选项, 然后在步骤4中找到可下载的链接。单击该链接进行下载。对于本教程, 你将下载2.2.0 Spark版本和”为Apache Hadoop 2.7及更高版本预构建”软件包类型。
请注意, 下载可能需要一些时间才能完成!
使用Homebrew下载Spark
你还可以使用免费的开源软件包管理器Homebrew安装Spark。如果你使用的是macOS, 这尤其方便。
只需运行以下命令以搜索Spark, 以获取更多信息并将其最终安装在你的个人计算机上:
# Search for spark
$ brew search spark
# Get more information on apache-spark
$ brew info apache-spark
# Install apache-spark
$ brew install apache-spark下载并设置Spark
接下来, 确保解压缩显示在”下载”文件夹中的目录。通过双击spark-2.2.0-bin-hadoop2.7.tgz归档文件或打开终端并运行以下命令, 可以自动为你完成此操作:
$ tar xvf spark-2.2.0-bin-hadoop2.7.tgz接下来, 通过运行以下行将未解压缩的文件夹移动到/ usr / local / spark:
$ mv spark-2.1.0-bin-hadoop2.7 /usr/local/spark请注意, 如果收到错误消息, 表明拒绝将文件夹移动到新位置的权限, 则应在此命令前添加sudo。上面的行将变为$ sudo mv spark-2.1.0-bin-hadoop2.7 / usr / local / spark。系统将提示你输入密码, 通常是启动时用来解锁PC的密码:)
现在你已经准备就绪, 请在文件路径/ usr / local / spark中打开README文件。你可以通过执行
$ cd /usr/local/spark这会将你带到所需的文件夹。然后, 你可以开始检查文件夹并读取其中包含的README文件。
首先, 使用$ ls获取此spark文件夹中的文件和文件夹的列表。你会看到其中有一个README.md文件。你可以通过执行以下命令之一来打开它:
# Open and edit the file
$ nano README.md
# Just read the file
$ cat README.md提示你在输入文件名时使用键盘上的Tab键自动完成:)这样可以节省一些时间。
你会发现该自述文件为你提供了一些有关Spark, 在线文档, 构建Spark, Interactive Scala和Python Shell, 示例程序等的常规信息。
你最感兴趣的是关于如何构建Spark的部分, 但请注意, 只有在你未下载预构建版本的情况下, 这才特别重要。但是, 对于本教程, 你下载了预构建版本。你可以按CTRL + X退出自述文件, 这将你带回到spark文件夹。
如果你选择的版本尚未构建, 请确保你运行自述文件中列出的命令。在撰写本文时, 内容如下:
$ build/mvn -DskipTests clean package run请注意, 此命令可能需要一段时间才能运行。
PySpark基础:RDD
现在, 你已经成功安装了Spark和PySpark, 让我们首先开始探索交互式Spark Shell, 并确定想要入门时所需的一些基础知识。但是, 在本教程的其余部分中, 你将在Jupyter笔记本中使用PySpark。
Spark应用程序与Spark Shell
交互式外壳是Read-Eval(uate)-Print-Loop(REPL)环境的示例;这意味着你输入的内容都会被读取, 评估并打印出来, 以便你继续进行分析。这可能使你想起IPython, 这是一个功能强大的交互式Python shell, 你可能会从与Jupyter一起使用中了解到。如果你想了解更多信息, 请考虑阅读srcmini的IPython或Jupyter博客文章。
这意味着你可以使用外壳程序(该外壳程序可用于Python以及Scala)进行所需的所有交互式工作。
除此外壳程序外, 你还可以编写和部署Spark应用程序。与编写Spark应用程序相反, SparkSession已经为你创建, 因此你可以开始工作, 而不会浪费宝贵的时间来创建一个。
现在你可能想知道:什么是SparkSession?
好的, 这是Spark功能的主要切入点:它表示与Spark集群的连接, 你可以使用它来创建RDD并在该集群上广播变量。当你使用Spark时, 一切都以此SparkSession开始和结束。请注意, 在Spark 2.0.0之前, 三个主要的连接对象是SparkContext, SqlContext和HiveContext。
稍后, 你将看到更多有关此的内容。现在, 让我们只关注shell。
Python Spark Shell
在位于/ usr / local / spark的spark文件夹中, 可以运行
$ ./bin/pyspark首先, 你会看到一些文字。然后, 你将看到” Spark”出现, 如下所示:
Python 2.7.13 (v2.7.13:a06454b1afa1, Dec 17 2016, 12:39:47)
[GCC 4.2.1 (Apple Inc. build 5666) (dot 3)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
17/07/26 11:41:26 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/07/26 11:41:47 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_, _/_/ /_/\_\ version 2.2.0
/_/
Using Python version 2.7.13 (v2.7.13:a06454b1afa1, Dec 17 2016 12:39:47)
SparkSession available as 'spark'.
>>>看到此消息后, 便知道你已准备好开始在交互式外壳中进行实验!
提示:如果你更喜欢使用IPython Shell而不是Spark Shell, 则可以通过设置以下环境变量来做到这一点:
export PYSPARK_DRIVER_PYTHON="/usr/local/ipython/bin/ipython"创建RDD
现在, 让我们从小处做起, 制作一个RDD, 这是Spark的最基本构建块。 RDD只是代表数据, 而不是一个对象, 一组记录, 一个结果集或一个数据集。那是因为它是为驻留在多台计算机上的数据而设计的:一个RDD可以分布在数千个Java虚拟机(JVM)上, 因为Spark会自动在后台对数据进行分区以获得这种并行性。当然, 你可以调整并行度以获取更多分区。因此, RDD实际上是分区的集合。
你可以通过使用parallelize()函数并简单地向其中传递一些数据(可迭代的数据, 例如列表或集合)来轻松创建简单的RDD:
>>> rdd1 = spark.sparkContext.parallelize([('a', 7), ('a', 2), ('b', 2)])
>>> rdd2 = spark.sparkContext.parallelize([("a", ["x", "y", "z"]), ("b", ["p", "r"])])
>>> rdd3 = spark.sparkContext.parallelize(range(100))请注意, SparkSession对象具有SparkContext对象, 你可以使用spark.sparkContext访问该对象。出于向后兼容的原因, 仍然可以使用sc调用SparkContext, 例如rdd1 = sc.parallelize([‘a’, 7), (‘a’, 2), (‘b’, 2)])。
RDD操作
现在, 你已经创建了RDD, 可以使用rdd1和rdd2中的分布式数据进行并行操作。你有两种类型的操作:转换和操作。
现在, 为了直观地了解这两者之间的区别, 请考虑一些最常见的转换, 例如map(), filter(), flatMap(), sample(), randomSplit(), coalesce()和repartition(), 以及一些最常见的操作是reduce(), collect(), first(), take(), count()和saveAsHadoopFile()。
转换是对RDD的惰性操作, 它会创建一个或多个新的RDD, 而动作会产生非RDD值:它们返回结果集, 数字, 文件等。
例如, 你可以使用以下简单的lambda函数聚合rdd1的所有元素, 并将结果返回到驱动程序:
>>> rdd1.reduce(lambda a, b: a+b)执行此代码行将为你提供以下结果:(‘a’, 7, ‘a’, 2, ‘b’, 2)。转换的另一个示例是flatMapValues(), 你可以在键/值对RDD(例如rdd2)上运行。在这种情况下, 你可以通过flatMap函数传递键值对RDD rdd2中的每个值, 而无需更改键(这是下面定义的lambda函数), 然后通过用collect()收集结果来执行操作。
>>> rdd2.flatMapValues(lambda x: x).collect()
[('a', 'x'), ('a', 'y'), ('a', 'z'), ('b', 'p'), ('b', 'r')]数据
既然你已经了解了交互式Shell的一些基础知识, 那么该开始学习一些实际数据了。在本教程中, 你将利用”加利福尼亚住房”数据集。当然, 请注意, 这实际上是”小”数据, 在这种情况下使用Spark可能会过大。本教程仅用于教育目的, 旨在使你了解如何使用PySpark构建机器学习模型。
加载和浏览数据
即使你对数据有所了解, 也应该花点时间继续进行更彻底的研究;但是, 在执行此操作之前, 你将使用Spark设置Jupyter Notebook, 并将采取一些第一步来定义SparkContext。
Jupyter Notebook中的PySpark
在本教程的这一部分中, 你不会使用ishell, 但是会构建自己的应用程序。你将在Jupyter笔记本中执行此操作。你已经安装了所有需要的东西, 因此无需做很多事情即可让PySpark在Jupyter中工作。
你可以通过运行$ jupyter notebook像往常一样启动笔记本应用程序。然后, 制作一个新的笔记本, 你只需导入findspark库并使用init()函数。在这种情况下, 你将提供路径/ usr / local / spark到init(), 因为你可以确定这是安装Spark的路径。
# Import findspark
import findspark
# Initialize and provide path
findspark.init("/usr/local/spark")
# Or use this alternative
#findspark.init()提示:如果不知道你的路径设置正确还是在PC上安装了Spark的位置, 则始终可以使用findspark.find()自动检测Spark的安装位置。
如果你正在寻找在Jupyter中使用Spark的其他方法, 请查阅我们的Python Apache Apache Spark:入门指南。
现在你已经解决了所有问题, 你终于可以开始创建你的第一个Spark程序!
创建你的第一个Spark程序
你首先要做的是从pyspark包中导入SparkContext并对其进行初始化。请记住, 你之前不必这样做, 因为交互式Spark Shell自动为你创建并初始化了它!在这里, 你需要自己做一点工作:)
从pyspark.sql导入SparkSession模块, 并使用builder()方法构建一个SparkSession。然后, 你可以设置要连接的主URL, 应用程序名称, 添加一些其他配置(例如执行程序内存), 最后使用getOrCreate()获取当前的Spark会话, 或者在没有运行任何会话的情况下创建一个会话。
# Import SparkSession
from pyspark.sql import SparkSession
# Build the SparkSession
spark = SparkSession.builder \
.master("local") \
.appName("Linear Regression Model") \
.config("spark.executor.memory", "1gb") \
.getOrCreate()
sc = spark.sparkContext请注意, 如果在类似于此文件错误的地方出现FileNotFoundError错误:”没有这样的文件或目录:’/User/YourName/Downloads/spark-2.1.0-bin-hadoop2.7/./bin/spark-submit ‘”, 你知道必须(重新)设置Spark PATH。通过执行$ cd进入主目录, 然后通过运行$ nano .bash_profile编辑.bash_profile文件。
在文件底部添加如下内容
export SPARK_HOME="/usr/local/spark/"使用CTRL + X退出文件, 但还要输入Y确认更改, 以确保保存所做的调整。接下来, 不要忘记通过运行源代码.bash_profile来设置运动更改。
提示:如果需要, 你还可以设置其他环境变量。你可能不需要它们, 但是很高兴知道可以根据需要设置它们。请考虑以下示例:
# Set a fixed value for the hash seed secret
export PYTHONHASHSEED=0
# Set an alternate Python executable
export PYSPARK_PYTHON=/usr/local/ipython/bin/ipython
# Augment the default search path for shared libraries
export LD_LIBRARY_PATH=/usr/local/ipython/bin/ipython
# Augment the default search path for private libraries
export PYTHONPATH=$SPARK_HOME/python/lib/py4j-*-src.zip:$PYTHONPATH:$SPARK_HOME/python/还要注意, 现在你已经初始化了默认的SparkSession。但是, 在大多数情况下, 你需要对此进行进一步配置。你会发现在开始使用大数据时确实需要这样做。如果你想了解更多信息, 请查看此页面。
载入数据
本教程利用了加州住房数据集。它出现在1997年Pace, R.Kelley和Ronald Barry撰写的题为”稀疏空间自回归”的论文中, 并发表在《统计与概率快报》杂志上。研究人员使用1990年加州人口普查数据建立了该数据集。
数据每个普查区组包含一行。街区小组是美国人口普查局发布样本数据的最小地理单位(街区小组通常人口为600至3, 000人)。在此样本中, 一个街区组平均包含1425.5个居住在地理紧凑区域中的人。你可以从此网页或阅读上面提到的文章(在此处找到)收集这些信息。
这些空间数据包含20, 640个关于房价的观察结果, 其中包含9个经济变量:
- 经度是指每个块组在地球赤道以北或以南的地理位置的角距离;
- 纬度是指每个块组在地球赤道以东或以西的地理位置的角距离;
- 住房中位年龄是指某个街区人群的中位年龄。注意, 中值是位于观测值频率分布中点的值;
- 房间总数是每个街区组的房屋总数。
- 卧室总数是每个街区组房屋中卧室的总数;
- 人口是一个街区群体的居民人数;
- 住户是指每个街区组的房屋单位及其居住者;
- 收入中位数用于记录属于某个群体的人的收入中位数;和,
- 房屋中位数是因变量, 是指每个街区组的房屋中位数。
此外, 你还将了解到所有块组的条目均为零, 因为自变量和因变量已从数据中排除。
房屋中位数是因变量, 将在ML模型中分配给目标变量。
你可以在此处下载数据。查找houses.zip文件夹, 下载并解压缩它, 以便你可以访问数据文件夹。
接下来, 你将使用textFile()方法从将数据下载到RDD的文件夹中读取数据。此方法获取文件的URI(在本例中为你的计算机的本地路径), 并将其作为行的集合读取。为了方便起见, 你不仅要读取.data文件, 而且还要读取包含标头的.domain文件。这将允许你仔细检查变量的顺序。
# Load in the data
rdd = sc.textFile('/Users/yourName/Downloads/CaliforniaHousing/cal_housing.data')
# Load in the header
header = sc.textFile('/Users/yourName/Downloads/CaliforniaHousing/cal_housing.domain')数据探索
仅通过查看找到数据集的网页已经收集了很多信息, 但是在这种情况下, 最好借助Spark结合使用动手检查一下数据。
这里要了解的重要一点是, 由于Spark的执行是”惰性”执行, 因此尚未执行任何操作。你的数据尚未真正读入。rdd和header变量实际上只是你脑海中的概念。你必须推动Spark为你工作, 所以让我们使用collect()方法查看标题:
header.collect()collect()方法将整个RDD带到一台计算机上, 你将看到以下结果:
[u'longitude: continuous.', u'latitude: continuous.', u'housingMedianAge: continuous. ', u'totalRooms: continuous. ', u'totalBedrooms: continuous. ', u'population: continuous. ', u'households: continuous. ', u'medianIncome: continuous. ', u'medianHouseValue: continuous. ']提示:使用collect()时要小心!运行此行代码可能会导致驱动程序内存不足。这就是为什么如果你只想打印RDD的几个元素, 那么采用take()方法的以下方法会更安全。通常, 最好限制结果集, 就像使用SQL一样。
你将了解变量的顺序与上面在数据集表示中看到的顺序相同, 并且还将了解所有列均应具有连续值。让我们强迫Spark做更多工作, 并查看加州住房数据以确认这一点。
在RDD上调用take()方法:
rdd.take(2)通过执行上一行代码, 你可以获取RDD的前2个元素。结果与你预期的一样:因为使用textFile()函数读取了文件, 所以所有行都被一起读入。条目由单个逗号分隔, 行本身也由逗号分隔:
[u'-122.230000, 37.880000, 41.000000, 880.000000, 129.000000, 322.000000, 126.000000, 8.325200, 452600.000000', u'-122.220000, 37.860000, 21.000000, 7099.000000, 1106.000000, 2401.000000, 1138.000000, 8.301400, 358500.000000']你绝对需要解决此问题。现在, 你无需拆分条目, 但绝对需要确保数据行是单独的元素。为了解决这个问题, 你将使用map()函数, 在该函数中传递lambda函数以逗号分隔行。然后, 像以前一样, 通过使用take()方法运行同一行来检查结果:
请记住, lambda函数是在运行时创建的匿名函数。
# Split lines on commas
rdd = rdd.map(lambda line: line.split(", "))
# Inspect the first 2 lines
rdd.take(2)你将得到以下结果:
[[u'-122.230000', u'37.880000', u'41.000000', u'880.000000', u'129.000000', u'322.000000', u'126.000000', u'8.325200', u'452600.000000'], [u'-122.220000', u'37.860000', u'21.000000', u'7099.000000', u'1106.000000', u'2401.000000', u'1138.000000', u'8.301400', u'358500.000000']]另外, 你也可以使用以下功能检查数据:
# Inspect the first line
rdd.first()
# Take top elements
rdd.top(2)如果你习惯使用R中的Pandas或数据框, 则可能还希望看到标题, 但没有标题。为了使你的生活更轻松, 你将从RDD继续前进并将其转换为DataFrame。只要可以使用数据框, 它们就比RDD更为可取。尤其是在使用Python时, DataFrames的性能要优于RDD。
但是两者之间有什么区别?
当你要对非结构化数据执行低级转换和操作时, 可以使用RDD。这意味着你不必担心在按名称或列处理或访问属性时强加模式。引用之前关于性能的说法, 通过使用RDD, 你不一定想要DataFrames可以为(半)结构化数据提供性能优势。当你想使用功能性编程构造而非特定于域的表达式来操纵数据时, 请使用RDD。
概括地说, 你现在将切换到DataFrames以使用高级表达式, 执行SQL查询以进一步浏览数据并获得列访问。
因此, 让我们这样做。
第一步是使用模式创建RowRD对象或RDD对象。这是正常的, 因为就像DataFrame一样, 你最终希望遇到行和列的情况。每个条目都链接到一行, 并且某个列和某些列具有数据类型。
你将再次使用map()函数和另一个lambda函数, 在该函数中, 你将每个条目映射到行中的字段。为了使外观更直观, 请考虑以下第一行:
[u'-122.230000', u'37.880000', u'41.000000', u'880.000000', u'129.000000', u'322.000000', u'126.000000', u'8.325200', u'452600.000000']lambda函数表示你将在SchemaRDD中构造一行, 并且索引0处的元素将具有”经度”名称, 依此类推。
使用此SchemaRDD, 你可以使用toDF()方法轻松地将RDD转换为DataFrame。
# Import the necessary modules
from pyspark.sql import Row
# Map the RDD to a DF
df = rdd.map(lambda line: Row(longitude=line[0], latitude=line[1], housingMedianAge=line[2], totalRooms=line[3], totalBedRooms=line[4], population=line[5], households=line[6], medianIncome=line[7], medianHouseValue=line[8])).toDF()现在你有了DataFrame df, 可以使用之前也使用过的方法(即first()和take())以及head()和show()对其进行检查:
# Show the top 20 rows
df.show()你会立即发现, 这与你之前使用的RDD看起来有很大不同:
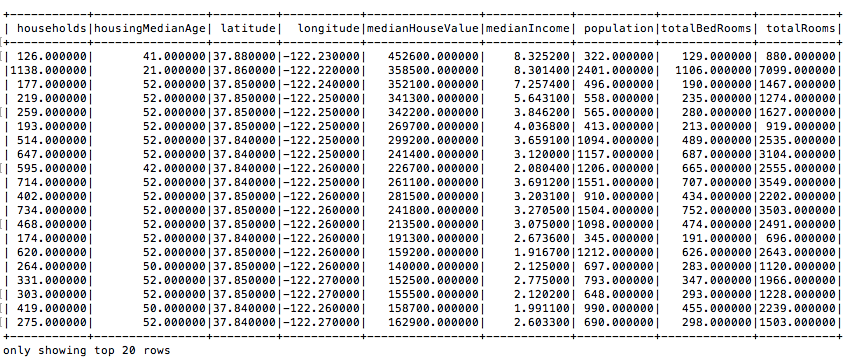
提示:使用df.columns返回DataFrame的列。
数据似乎都很好地按列排列, 但是数据类型呢?通过读入数据, Spark将尝试推断模式, 但这在这里成功了吗?使用df.dtypes或df.printSchema()可以了解有关DataFrame中包含的数据类型的更多信息。
# Print the data types of all `df` columns
# df.dtypes
# Print the schema of `df`
df.printSchema()因为你不执行第一行代码, 所以只会返回以下结果:
root
|-- households: string (nullable = true)
|-- housingMedianAge: string (nullable = true)
|-- latitude: string (nullable = true)
|-- longitude: string (nullable = true)
|-- medianHouseValue: string (nullable = true)
|-- medianIncome: string (nullable = true)
|-- population: string (nullable = true)
|-- totalBedRooms: string (nullable = true)
|-- totalRooms: string (nullable = true)所有列的数据类型仍然是字符串…令人失望!
如果要继续使用此DataFrame, 则需要纠正这种情况, 并为所有列分配”更好”或更准确的数据类型。你的演奏也将从中受益。直观地讲, 你可以采用以下解决方案, 在其中声明DataFrame df的每一列都应强制转换为FloatType():
from pyspark.sql.types import *
df = df.withColumn("longitude", df["longitude"].cast(FloatType())) \
.withColumn("latitude", df["latitude"].cast(FloatType())) \
.withColumn("housingMedianAge", df["housingMedianAge"].cast(FloatType())) \
.withColumn("totalRooms", df["totalRooms"].cast(FloatType())) \
.withColumn("totalBedRooms", df["totalBedRooms"].cast(FloatType())) \
.withColumn("population", df["population"].cast(FloatType())) \
.withColumn("households", df["households"].cast(FloatType())) \
.withColumn("medianIncome", df["medianIncome"].cast(FloatType())) \
.withColumn("medianHouseValue", df["medianHouseValue"].cast(FloatType()))但是这些重复的电话非常晦涩难懂, 不会出错, 看起来也不是很好。为什么不编写一个可以以更简洁的方式为你完成所有这些工作的函数?
以下用户定义函数(UDF)接受一个DataFrame, 列名以及你希望这些列具有的新数据类型。你说对于每个列名称, 你都将其取用, 然后将其强制转换为新的数据类型。然后, 你返回DataFrame:
# Import all from `sql.types`
from pyspark.sql.types import *
# Write a custom function to convert the data type of DataFrame columns
def convertColumn(df, names, newType):
for name in names:
df = df.withColumn(name, df[name].cast(newType))
return df
# Assign all column names to `columns`
columns = ['households', 'housingMedianAge', 'latitude', 'longitude', 'medianHouseValue', 'medianIncome', 'population', 'totalBedRooms', 'totalRooms']
# Conver the `df` columns to `FloatType()`
df = convertColumn(df, columns, FloatType())看起来已经好多了!就像之前一样, 你可以使用printSchema()方法快速检查df的数据类型。
现在你已经完成了所有工作, 现在该是真正开始进行数据探索的时候了。你已经看到, 列访问和SQL查询是使用DataFrames的两个优点。好吧, 现在是时候进一步深入探讨了。让我们从小处开始, 只需从df中选择两列, 你只希望看到10行:
df.select('population', 'totalBedRooms').show(10)该查询为你提供以下结果:
+----------+-------------+
|population|totalBedRooms|
+----------+-------------+
| 322.0| 129.0|
| 2401.0| 1106.0|
| 496.0| 190.0|
| 558.0| 235.0|
| 565.0| 280.0|
| 413.0| 213.0|
| 1094.0| 489.0|
| 1157.0| 687.0|
| 1206.0| 665.0|
| 1551.0| 707.0|
+----------+-------------+
only showing top 10 rows你还可以使查询更加复杂, 如以下示例所示:
df.groupBy("housingMedianAge").count().sort("housingMedianAge", ascending=False).show()得到以下结果:
+----------------+-----+
|housingMedianAge|count|
+----------------+-----+
| 52.0| 1273|
| 51.0| 48|
| 50.0| 136|
| 49.0| 134|
| 48.0| 177|
| 47.0| 198|
| 46.0| 245|
| 45.0| 294|
| 44.0| 356|
| 43.0| 353|
| 42.0| 368|
| 41.0| 296|
| 40.0| 304|
| 39.0| 369|
| 38.0| 394|
| 37.0| 537|
| 36.0| 862|
| 35.0| 824|
| 34.0| 689|
| 33.0| 615|
+----------------+-----+
only showing top 20 rows除了查询之外, 你还可以选择描述你的数据并获得一些摘要统计信息。这绝对会在之后为你提供帮助!
df.describe().show()
查看所有(数字)属性的最小值和最大值。你会看到多个属性具有广泛的值:你将需要规范化数据集。
数据预处理
借助从小型探索性数据分析中收集的所有这些信息, 你就足够了解预处理数据以将其馈送到模型中的能力。
- 你不应该担心缺少值;所有零值均已从数据集中排除。
- 你可能应该标准化数据, 因为你已经看到最小值和最大值的范围很大。
- 你可能会添加一些其他属性, 例如注册每个房间的卧室数或每个家庭的房间数的功能。
- 你的因变量也很大;为了让你的生活更轻松, 你必须稍微调整一下数值。
预处理目标值
首先, 让我们从中值HouseValue(你的因变量)开始。为了方便你使用目标值, 你将以100, 000为单位表示房屋价值。这意味着诸如452600.000000之类的目标应变为4.526:
# Import all from `sql.functions`
from pyspark.sql.functions import *
# Adjust the values of `medianHouseValue`
df = df.withColumn("medianHouseValue", col("medianHouseValue")/100000)
# Show the first 2 lines of `df`
df.take(2)当你查看take()方法的结果时, 你可以清楚地看到值已正确调整:
[Row(households=126.0, housingMedianAge=41.0, latitude=37.880001068115234, longitude=-122.2300033569336, medianHouseValue=4.526, medianIncome=8.325200080871582, population=322.0, totalBedRooms=129.0, totalRooms=880.0), Row(households=1138.0, housingMedianAge=21.0, latitude=37.86000061035156, longitude=-122.22000122070312, medianHouseValue=3.585, medianIncome=8.301400184631348, population=2401.0, totalBedRooms=1106.0, totalRooms=7099.0)]特征工程
现在, 你已经调整了位数房屋价值中的值, 你还可以添加上面阅读的其他变量。你将在数据集中添加以下列:
- 每户房间数是指每个街区组的家庭房间数;
- 每个家庭的人口, 基本上可以让你了解每个街区组的家庭有多少人;和
- 每个房间的卧室, 这将使你了解每个块组有多少个房间;
在使用DataFrames时, 最好使用select()方法选择要使用的列, 即totalRooms, 家庭和人口。此外, 你必须通过在代码中添加col()函数来表明你正在使用列。否则, 你将无法进行像元素划分这样的元素操作, 你要牢记这三个变量:
# Import all from `sql.functions` if you haven't yet
from pyspark.sql.functions import *
# Divide `totalRooms` by `households`
roomsPerHousehold = df.select(col("totalRooms")/col("households"))
# Divide `population` by `households`
populationPerHousehold = df.select(col("population")/col("households"))
# Divide `totalBedRooms` by `totalRooms`
bedroomsPerRoom = df.select(col("totalBedRooms")/col("totalRooms"))
# Add the new columns to `df`
df = df.withColumn("roomsPerHousehold", col("totalRooms")/col("households")) \
.withColumn("populationPerHousehold", col("population")/col("households")) \
.withColumn("bedroomsPerRoom", col("totalBedRooms")/col("totalRooms"))
# Inspect the result
df.first()你会看到, 对于第一行, 每个家庭大约有6.98个房间, 块组中的家庭大约有2.5个人, 而卧室的数量非常少, 只有0.14:
Row(households=126.0, housingMedianAge=41.0, latitude=37.880001068115234, longitude=-122.2300033569336, medianHouseValue=4.526, medianIncome=8.325200080871582, population=322.0, totalBedRooms=129.0, totalRooms=880.0, roomsPerHousehold=6.984126984126984, populationPerHousehold=2.5555555555555554, bedroomsPerRoom=0.14659090909090908)接下来, -这已经预见了在标准化数据集中的值时可能遇到的问题-你还将对值进行重新排序。由于你不一定要标准化目标值, 因此需要确保隔离数据集中的目标值。
在这种情况下, 你需要使用select()方法并以更合适的顺序传递列名来执行此操作。在这种情况下, 应将目标变量中位数房屋价值放在首位, 这样它就不会受到标准化的影响。
还要注意, 这是舍弃你可能不想在分析中考虑的变量的时候。在这种情况下, 我们忽略诸如经度, 纬度, housingMedianAge和totalRooms之类的变量。
# Re-order and select columns
df = df.select("medianHouseValue", "totalBedRooms", "population", "households", "medianIncome", "roomsPerHousehold", "populationPerHousehold", "bedroomsPerRoom")标准化
现在, 你已经对数据进行了重新排序, 就可以对数据进行规范化了。或几乎, 至少。你只需要完成一个步骤:将功能与目标变量分开。从本质上讲, 这可以归结为将DataFrame中的第一列与其余列隔离。
在这种情况下, 你将使用与RDD一起使用的map()函数来执行此操作。你还将看到使用了DenseVector()函数。密集向量是由代表其输入值的双精度数组支持的局部向量。换句话说, 它用于存储值数组以供PySpark使用。
接下来, 返回使用input_data制作DataFrame的方法, 并通过将列表作为第二个参数传递来重新标记列。此列表由列名”标签”和”功能”组成:
# Import `DenseVector`
from pyspark.ml.linalg import DenseVector
# Define the `input_data`
input_data = df.rdd.map(lambda x: (x[0], DenseVector(x[1:])))
# Replace `df` with the new DataFrame
df = spark.createDataFrame(input_data, ["label", "features"])接下来, 你最终可以缩放数据。你可以使用Spark ML做到这一点:该库将使可扩展且容易的大数据机器学习。你会发现ML算法之类的工具, 以及建立实用ML管道所需的一切。在这种情况下, 你不需要进行太多的预处理, 因此管道可能会显得过大, 但是如果你要研究它, 一定要考虑访问此页面。
输入列是要素, 而将包含在scaled_df中的具有重新缩放的输出列将被命名为” features_scaled”:
# Import `StandardScaler`
from pyspark.ml.feature import StandardScaler
# Initialize the `standardScaler`
standardScaler = StandardScaler(inputCol="features", outputCol="features_scaled")
# Fit the DataFrame to the scaler
scaler = standardScaler.fit(df)
# Transform the data in `df` with the scaler
scaled_df = scaler.transform(df)
# Inspect the result
scaled_df.take(2)让我们看一下你的DataFrame和结果。你确实看到, 确实在你的DataFrame中添加了第三列features_scaled, 你可以将其与功能进行比较:
[Row(label=4.526, features=DenseVector([129.0, 322.0, 126.0, 8.3252, 6.9841, 2.5556, 0.1466]), features_scaled=DenseVector([0.3062, 0.2843, 0.3296, 4.3821, 2.8228, 0.2461, 2.5264])), Row(label=3.585, features=DenseVector([1106.0, 2401.0, 1138.0, 8.3014, 6.2381, 2.1098, 0.1558]), features_scaled=DenseVector([2.6255, 2.1202, 2.9765, 4.3696, 2.5213, 0.2031, 2.6851]))]请注意, 这些代码行与你在Scikit-Learn中所做的非常相似。
使用Spark ML构建机器学习模型
完成所有预处理后, 终于可以开始构建线性回归模型了!像往常一样, 你首先需要将数据分为训练集和测试集。幸运的是, randomSplit()方法没有问题:
# Split the data into train and test sets
train_data, test_data = scaled_df.randomSplit([.8, .2], seed=1234)你传入一个带有两个数字的列表, 这些数字代表你希望训练和测试集拥有的大小, 并带有一个种子, 出于可重复性原因, 需要使用此种子。如果你想了解更多信息, 请考虑srcmini的Python机器学习教程。
然后, 不用费劲, 你就可以制作模型!
请注意, 参数elasticNetParam对应于α或垂直截距, 而regParam或正则化参数对应于λ。点击这里了解更多信息。
# Import `LinearRegression`
from pyspark.ml.regression import LinearRegression
# Initialize `lr`
lr = LinearRegression(labelCol="label", maxIter=10, regParam=0.3, elasticNetParam=0.8)
# Fit the data to the model
linearModel = lr.fit(train_data)放置好模型后, 你可以为测试数据生成预测:使用transform()方法预测test_data的标签。然后, 你可以使用RDD操作从DataFrame中提取预测以及真实标签, 并将这两个值一起压缩到一个名为predictionAndLabel的列表中。
最后, 你只需使用方括号[]访问列表即可检查预测值和实际值:
# Generate predictions
predicted = linearModel.transform(test_data)
# Extract the predictions and the "known" correct labels
predictions = predicted.select("prediction").rdd.map(lambda x: x[0])
labels = predicted.select("label").rdd.map(lambda x: x[0])
# Zip `predictions` and `labels` into a list
predictionAndLabel = predictions.zip(labels).collect()
# Print out first 5 instances of `predictionAndLabel`
predictionAndLabel[:5]你会看到以下实际值和预测值(按此顺序):
[(1.4491508524918457, 0.14999), (1.5705029404692372, 0.14999), (2.148727956912464, 0.14999), (1.5831547768979277, 0.344), (1.5182107797955968, 0.398)]评估模型
查看预测值是一回事, 但另一方面, 更好的是查看一些指标以更好地了解模型的实际效果。你可以首先打印出系数和模型的截距:
# Coefficients for the model
linearModel.coefficients
# Intercept for the model
linearModel.intercept得到以下结果:
# The coefficients
[0.0, 0.0, 0.0, 0.276239709215, 0.0, 0.0, 0.0]
# The intercept
0.990399577462接下来, 你还可以使用summary属性来拉起rootMeanSquaredError和r2:
# Get the RMSE
linearModel.summary.rootMeanSquaredError
# Get the R2
linearModel.summary.r2-
RMSE衡量比较预测值和观察值或已知值的两个数据集之间存在多少误差。 RMSE值越小, 预测值和观察值越接近。
-
R2(” R平方”)或确定系数是一种度量, 用于显示数据与拟合回归线的接近程度。该分数将始终在0到100%之间(在这种情况下为0到1), 其中0%表示模型没有解释响应数据均值周围的变化, 而100%则表明相反:所有的可变性。通常, 这意味着R平方越高, 该模型越适合你的数据。
你将获得以下结果:
# RMSE
0.8692118678997669
# R2
0.4240895287218379
你的模型肯定需要一些改进!如果要继续使用此模型, 则可以处理传递给模型的参数, 以及原始DataFrame中包含的变量, …。但这就是本教程的结尾!
你走之前…
在开始之前, 请确保使用以下代码行停止SparkSession:
spark.stop()进一步推动大数据
恭喜!在本教程的最后, 你已经学到了如何在Spark ML的帮助下制作线性回归模型。
如果你想了解有关PySpark的更多信息, 请考虑参加srcmini的PySpark入门课程。
评论前必须登录!
注册