 srcmini
srcmini本文概述
在之前的两个Kaggle教程中, 你学习了所有有关如何使用探索性数据分析和基准机器学习模型以表格形式获取数据以构建第一个机器学习模型的知识。接下来, 你成功地建立了第一个机器学习模型, 即决策树分类器。你已将所有这些模型提交给Kaggle并解释了其准确性。
在第三篇教程中, 你将学习有关特征工程的更多信息, 该过程中, 你将使用数据的领域知识来创建其他相关特征, 从而增加学习算法的预测能力, 并使机器学习模型的性能更好!
进一步来说,
- 首先, 你需要进行所有必要的导入并在工作区中获取数据;
- 然后, 你将看到一些为什么应该进行要素工程并开始为数据集设计自己的新要素的原因!你将创建新列, 将变量转换为数字列, 处理缺失值等等。
- 最后, 你将使用新数据集构建一个新的机器学习模型, 并将其提交给Kaggle。
入门!
在开始之前, 你将要进行所有导入, 就像在上一个教程中一样, 使用一些IPython魔术来确保在Jupyter Notebook中内联生成图形并设置可视化样式。接下来, 你可以导入数据, 并确保将训练数据的目标变量存储在安全的地方。然后, 合并训练和测试数据集(df_train的” Survived”列除外)并将结果存储在数据中。
请记住, 你这样做是因为要确保对数据进行的任何预处理都可以同时反映在训练和测试集中!
最后, 你使用.info()方法查看数据:
# Imports
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import re
import numpy as np
from sklearn import tree
from sklearn.model_selection import GridSearchCV
# Figures inline and set visualization style
%matplotlib inline
sns.set()
# Import data
df_train = pd.read_csv('data/train.csv')
df_test = pd.read_csv('data/test.csv')
# Store target variable of training data in a safe place
survived_train = df_train.Survived
# Concatenate training and test sets
data = pd.concat([df_train.drop(['Survived'], axis=1), df_test])
# View head
data.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1309 entries, 0 to 417
Data columns (total 11 columns):
PassengerId 1309 non-null int64
Pclass 1309 non-null int64
Name 1309 non-null object
Sex 1309 non-null object
Age 1046 non-null float64
SibSp 1309 non-null int64
Parch 1309 non-null int64
Ticket 1309 non-null object
Fare 1308 non-null float64
Cabin 295 non-null object
Embarked 1307 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 122.7+ KB
为什么要使用特征工程师?
你可以执行要素工程以从数据中提取更多信息, 以便在构建模型时可以进行游戏。
泰坦尼克号的旅客头衔
让我们通过看一个例子来了解这到底是什么。让我们借助.tail()方法来检查”名称”列, 该方法可帮助你查看数据的最后五行:
# View head of 'Name' column
data.Name.tail()
413 Spector, Mr. Woolf
414 Oliva y Ocana, Dona. Fermina
415 Saether, Mr. Simon Sivertsen
416 Ware, Mr. Frederick
417 Peter, Master. Michael J
Name: Name, dtype: object
突然, 你会看到不同的标题出现!换句话说, 此列包含字符串或包含标题的文本, 例如” Mr”, ” Master”和” Dona”。
这些标题当然可以为你提供有关社会地位, 职业等方面的信息, 最终这些信息可以告诉你有关生存的更多信息。
乍一看, 将名称与标题分开似乎是一项艰巨的任务, 但不要惊慌!请记住, 你可以轻松使用正则表达式提取标题并将其存储在新的”标题”列中:
# Extract Title from Name, store in column and plot barplot
data['Title'] = data.Name.apply(lambda x: re.search(' ([A-Z][a-z]+)\.', x).group(1))
sns.countplot(x='Title', data=data);
plt.xticks(rotation=45);

请注意, 此新列”标题”实际上是你的数据集的新特征!
提示:要了解有关正则表达式的更多信息, 请查看我对事件的最后FB Live代码的撰写, 或者查阅srcmini的Python正则表达式教程。
你可以看到上面的图中有几个标题, 并且有很多不经常出现。因此, 将它们放在更少的存储桶中是有意义的。
例如, 你可能想用” Mrs”将” Mlle”和” Ms”替换为” Miss”和” Mme”, 因为这些是法语标题, 并且理想情况下, 你希望所有数据都使用一种语言。接下来, 你还将获得一堆无法立即分类的标题, 并将其放入”特殊”存储桶中。
提示:尝试一下, 以了解你的算法作为函数的性能!
接下来, 借助.countplot()方法查看结果的条形图:
data['Title'] = data['Title'].replace({'Mlle':'Miss', 'Mme':'Mrs', 'Ms':'Miss'})
data['Title'] = data['Title'].replace(['Don', 'Dona', 'Rev', 'Dr', 'Major', 'Lady', 'Sir', 'Col', 'Capt', 'Countess', 'Jonkheer'], 'Special')
sns.countplot(x='Title', data=data);
plt.xticks(rotation=45);

这就是你新设计的特征”标题”的外观!
现在, 确保你具有”标题”列, 并使用.tail()方法再次检出数据:
# View head of data
data.tail()
| 旅客编号 | P类 | 名称 | 性别 | 年龄 | 锡卜 | 版本号 | 票 | 做 | 舱 | 出发 | 标题 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 413 | 1305 | 3 | 幽灵先生, 伍尔夫先生 | 男 | NaN | 0 | 0 | A.5。 3236 | 8.0500 | NaN | 小号 | Mr |
| 414 | 1306 | 1 | Oliva和Ocana, Dona。费米纳 | 女 | 39.0 | 0 | 0 | 电脑17758 | 108.9000 | Q105 | C | 特别 |
| 415 | 1307 | 3 | 赛瑟(Siether Sivertsen)先生 | 男 | 38.5 | 0 | 0 | 索顿/ O.Q. 3101262 | 7.2500 | NaN | 小号 | Mr |
| 416 | 1308 | 3 | 洁具, 弗雷德里克先生 | 男 | NaN | 0 | 0 | 359309 | 8.0500 | NaN | 小号 | Mr |
| 417 | 1309 | 3 | 彼得, 师父。迈克尔·J | 男 | NaN | 1 | 1 | 2668 | 22.3583 | NaN | C | 主 |
客舱
加载数据并检查数据时, 你发现”机舱”列中存在多个NaN或缺少值。
可以合理地假设这些NaN没有机舱, 这可以告诉你有关”生存”的信息。因此, 现在让我们创建一个新列” Has_Cabin”, 该列对该信息进行编码, 并告诉你乘客是否有机舱。
请注意, 你在下面的代码块中使用.isnull()方法, 如果乘客没有机舱, 它将返回True, 否则返回False。但是, 由于要将结果存储在” Has_Cabin”列中, 因此实际上要翻转结果:如果乘客有机舱, 则要返回True。这就是为什么使用波浪号〜的原因。
# Did they have a Cabin?
data['Has_Cabin'] = ~data.Cabin.isnull()
# View head of data
data.head()
| 旅客编号 | P类 | 名称 | 性别 | 年龄 | 锡卜 | 版本号 | 票 | 做 | 舱 | 出发 | 标题 | Has_Cabin | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 3 | 布朗德, 欧文·哈里斯先生 | 男 | 22.0 | 1 | 0 | A / 5 21171 | 7.2500 | NaN | 小号 | Mr | false |
| 1 | 2 | 1 | 卡明斯, 约翰·布拉德利夫人(佛罗伦萨·布里格斯 | 女 | 38.0 | 1 | 0 | 电脑17599 | 71.2833 | C85 | C | 太太 | true |
| 2 | 3 | 3 | 海基宁小姐贷款 | 女 | 26.0 | 0 | 0 | STON / O2。 3101282 | 7.9250 | NaN | 小号 | 小姐 | false |
| 3 | 4 | 1 | Futrelle, Jacques Heath夫人(Lily May Peel) | 女 | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | 小号 | 太太 | true |
| 4 | 5 | 3 | 艾伦·威廉·亨利先生 | 男 | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | 小号 | Mr | false |
你现在想要做的就是删除一列不包含更多有用信息(或者我们不确定该怎么做)的列。在这种情况下, 你正在查看诸如[‘Cabin’, ‘Name’, ‘PassengerId’, ‘Ticket’]之类的列, 因为
- 你已经在新添加的” Has_Cabin”列中提取了有关乘客是否有机舱的信息;
- 另外, 你已经从”名称”列中提取了标题;
- 你还要删除” PassengerId”和” Ticket”列, 因为这些列可能不会告诉你更多有关泰坦尼克号乘客生存的信息。
提示”机舱”列中可能会有更多信息, 但是对于本教程, 你认为没有!
要将这些列放入实际数据DataFrame中, 请确保在.drop()方法中使用inplace参数并将其设置为True:
# Drop columns and view head
data.drop(['Cabin', 'Name', 'PassengerId', 'Ticket'], axis=1, inplace=True)
data.head()
| P类 | 性别 | 年龄 | 锡卜 | 版本号 | 做 | 出发 | 标题 | Has_Cabin | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | 男 | 22.0 | 1 | 0 | 7.2500 | 小号 | Mr | false |
| 1 | 1 | 女 | 38.0 | 1 | 0 | 71.2833 | C | 太太 | true |
| 2 | 3 | 女 | 26.0 | 0 | 0 | 7.9250 | 小号 | 小姐 | false |
| 3 | 1 | 女 | 35.0 | 1 | 0 | 53.1000 | 小号 | 太太 | true |
| 4 | 3 | 男 | 35.0 | 0 | 0 | 8.0500 | 小号 | Mr | false |
恭喜!你已经成功设计了一些新特征, 例如’Title’和’Has_Cabin’, 并确保现在不会从DataFrame中删除那些不会为你的机器学习模型添加更多有用信息的特征!
接下来, 你要处理缺失值, 对数值数据进行分箱, 然后再次使用.get_dummies()将所有要素转换为数值变量。最后, 你将为本教程构建最终模型。在下一部分中检查所有这些操作是如何完成的!
处理缺失值
对原始数据DataFrame进行所有更改后, 最好找出.info()是否遗漏任何值:
data.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1309 entries, 0 to 417
Data columns (total 9 columns):
Pclass 1309 non-null int64
Sex 1309 non-null object
Age 1046 non-null float64
SibSp 1309 non-null int64
Parch 1309 non-null int64
Fare 1308 non-null float64
Embarked 1307 non-null object
Title 1309 non-null object
Has_Cabin 1309 non-null bool
dtypes: bool(1), float64(2), int64(3), object(3)
memory usage: 133.3+ KB
上面的代码行的结果告诉你, “年龄”, “票价”和”禁止”中缺少值。
请记住, 你可以通过首先查看条目总数(1309), 然后在.info()列出的列中检出非空值的数量, 来轻松发现这一点。在这种情况下, 你会看到”年龄”有1046个非空值, 这意味着你有263个缺失值。同样, “票价”只有一个缺失值, 而”禁运”有两个缺失值。
就像你在上一教程中所做的一样, 你将在.fillna()的帮助下估算这些缺失的值:
请注意, 再次使用中位数填写”年龄”和”票价”列, 因为它非常适合处理异常值。推算缺失值的其他方法是使用平均值, 你可以通过将所有数据点相加并除以数据点数或众数(即出现次数最多的众数)来找到平均值。
在” Embarked”列中用” S”填充两个缺失值, S代表南安普敦, 因为该值是在此列中找到的所有值中最常见的一个。
提示:你可以通过执行其他探索性数据分析来再次确认这一点!
# Impute missing values for Age, Fare, Embarked
data['Age'] = data.Age.fillna(data.Age.median())
data['Fare'] = data.Fare.fillna(data.Fare.median())
data['Embarked'] = data['Embarked'].fillna('S')
data.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1309 entries, 0 to 417
Data columns (total 9 columns):
Pclass 1309 non-null int64
Sex 1309 non-null object
Age 1309 non-null float64
SibSp 1309 non-null int64
Parch 1309 non-null int64
Fare 1309 non-null float64
Embarked 1309 non-null object
Title 1309 non-null object
Has_Cabin 1309 non-null bool
dtypes: bool(1), float64(2), int64(3), object(3)
memory usage: 133.3+ KB
data.head()
| P类 | 性别 | 年龄 | 锡卜 | 版本号 | 做 | 出发 | 标题 | Has_Cabin | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | 男 | 22.0 | 1 | 0 | 7.2500 | 小号 | Mr | false |
| 1 | 1 | 女 | 38.0 | 1 | 0 | 71.2833 | C | 太太 | true |
| 2 | 3 | 女 | 26.0 | 0 | 0 | 7.9250 | 小号 | 小姐 | false |
| 3 | 1 | 女 | 35.0 | 1 | 0 | 53.1000 | 小号 | 太太 | true |
| 4 | 3 | 男 | 35.0 | 0 | 0 | 8.0500 | 小号 | Mr | false |
Bin数值数据
接下来, 你要对数值数据进行分箱, 因为你有一定的年龄和票价范围。但是, 这些数字可能存在波动, 无法反映数据中的模式, 这可能是噪声。这就是为什么要将年龄或票价在一定范围内的人放在同一个箱子中的原因。你可以通过使用pandas函数qcut()来对数字数据进行装箱:
# Binning numerical columns
data['CatAge'] = pd.qcut(data.Age, q=4, labels=False )
data['CatFare']= pd.qcut(data.Fare, q=4, labels=False)
data.head()
| P类 | 性别 | 年龄 | 锡卜 | 版本号 | 做 | 出发 | 标题 | Has_Cabin | 年龄 | 计程车费 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | 男 | 22.0 | 1 | 0 | 7.2500 | 小号 | Mr | false | 0 | 0 |
| 1 | 1 | 女 | 38.0 | 1 | 0 | 71.2833 | C | 太太 | true | 3 | 3 |
| 2 | 3 | 女 | 26.0 | 0 | 0 | 7.9250 | 小号 | 小姐 | false | 1 | 1 |
| 3 | 1 | 女 | 35.0 | 1 | 0 | 53.1000 | 小号 | 太太 | true | 2 | 3 |
| 4 | 3 | 男 | 35.0 | 0 | 0 | 8.0500 | 小号 | Mr | false | 2 | 1 |
请注意, 你将数据作为Series, data.Age和data.Fare传递, 然后指定分位数q = 4。最后, 将标签参数设置为False, 以将垃圾箱编码为数字。
现在你已将所有这些信息存储在箱中, 现在可以安全地删除”年龄”和”票价”列。不要忘记签出数据的前五行!
data = data.drop(['Age', 'Fare'], axis=1)
data.head()
| P类 | 性别 | 锡卜 | 版本号 | 出发 | 标题 | Has_Cabin | 年龄 | 计程车费 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | 男 | 1 | 0 | 小号 | Mr | false | 0 | 0 |
| 1 | 1 | 女 | 1 | 0 | C | 太太 | true | 3 | 3 |
| 2 | 3 | 女 | 0 | 0 | 小号 | 小姐 | false | 1 | 1 |
| 3 | 1 | 女 | 1 | 0 | 小号 | 太太 | true | 2 | 3 |
| 4 | 3 | 男 | 0 | 0 | 小号 | Mr | false | 2 | 1 |
船上家庭成员人数
接下来, 你可以创建一个新列, 该列是”泰坦尼克号”船上家族中的成员数量。在本教程中, 你将不会研究模型的执行情况。如果你确实想查看该模型如何处理此附加列, 请运行以下代码行:
# Create column of number of Family members onboard
data['Fam_Size'] = data.Parch + data.SibSp
现在, 你只需继续从DataFrame中删除” SibSp”和” Parch”列:
# Drop columns
data = data.drop(['SibSp', 'Parch'], axis=1)
data.head()
| P类 | 性别 | 出发 | 标题 | Has_Cabin | 年龄 | 计程车费 | |
|---|---|---|---|---|---|---|---|
| 0 | 3 | 男 | 小号 | Mr | false | 0 | 0 |
| 1 | 1 | 女 | C | 太太 | true | 3 | 3 |
| 2 | 3 | 女 | 小号 | 小姐 | false | 1 | 1 |
| 3 | 1 | 女 | 小号 | 太太 | true | 2 | 3 |
| 4 | 3 | 男 | 小号 | Mr | false | 2 | 1 |
将变量转换为数值变量
既然你已经设计了一些其他特征, 例如” Title”和” Has_Cabin”, 并且已经处理了缺失值, 对数值数据进行装箱, 那么现在该将所有变量转换为数值变量了。这样做是因为机器学习模型通常采用数字输入。
如之前所做的那样, 你将使用.get_dummies()进行此操作:
# Transform into binary variables
data_dum = pd.get_dummies(data, drop_first=True)
data_dum.head()
| P类 | Has_Cabin | 年龄 | 计程车费 | 性别男 | 登船_Q | 登船 | 标题_小姐 | 职称_先生 | 职称_夫人 | Title_Special | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | false | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 |
| 1 | 1 | true | 3 | 3 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 2 | 3 | false | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 |
| 3 | 1 | true | 2 | 3 | 0 | 0 | 1 | 0 | 0 | 1 | 0 |
| 4 | 3 | false | 2 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 |
完成所有这些步骤后, 就该构建最终模型了!
使用新数据集构建模型!
和以前一样, 你首先将数据分成训练和测试集。然后, 将它们转换为数组:
# Split into test.train
data_train = data_dum.iloc[:891]
data_test = data_dum.iloc[891:]
# Transform into arrays for scikit-learn
X = data_train.values
test = data_test.values
y = survived_train.values
现在, 你将在全新的特征部件工程数据集上构建决策树。要选择你的超参数max_depth, 你将在测试序列拆分中使用一个称为”交叉验证”的变体。

首先将数据集分为5个组或折叠。然后, 你将第一个折叠作为测试集, 将模型拟合到其余四个折叠上, 在测试集上进行预测并计算目标度量。接下来, 你将第二折作为你的测试集, 对剩余数据进行拟合, 对测试集进行预测并计算目标度量。然后与第三, 第四和第五类似。
结果, 你将获得五个精度值, 从中可以计算出感兴趣的统计数据, 例如中位数和/或均值以及95%置信区间。
你可以针对要调整的每个超参数的每个值执行此操作, 然后选择性能最佳的超参数集。这称为网格搜索。
现在已经足够了, 让我们开始吧!
在下文中, 你将使用交叉验证和网格搜索为新的要素工程数据集选择最佳的max_depth:
# Setup the hyperparameter grid
dep = np.arange(1, 9)
param_grid = {'max_depth' : dep}
# Instantiate a decision tree classifier: clf
clf = tree.DecisionTreeClassifier()
# Instantiate the GridSearchCV object: clf_cv
clf_cv = GridSearchCV(clf, param_grid=param_grid, cv=5)
# Fit it to the data
clf_cv.fit(X, y)
# Print the tuned parameter and score
print("Tuned Decision Tree Parameters: {}".format(clf_cv.best_params_))
print("Best score is {}".format(clf_cv.best_score_))
Tuned Decision Tree Parameters: {'max_depth': 3}
Best score is 0.8103254769921436
现在, 你可以对测试集进行预测, 创建一个新列” Survived”并将其存储在其中。不要忘记将df_test的’PassengerId’和’Survived’列保存到.csv并将其提交给Kaggle!
Y_pred = clf_cv.predict(test)
df_test['Survived'] = Y_pred
df_test[['PassengerId', 'Survived']].to_csv('data/predictions/dec_tree_feat_eng.csv', index=False)
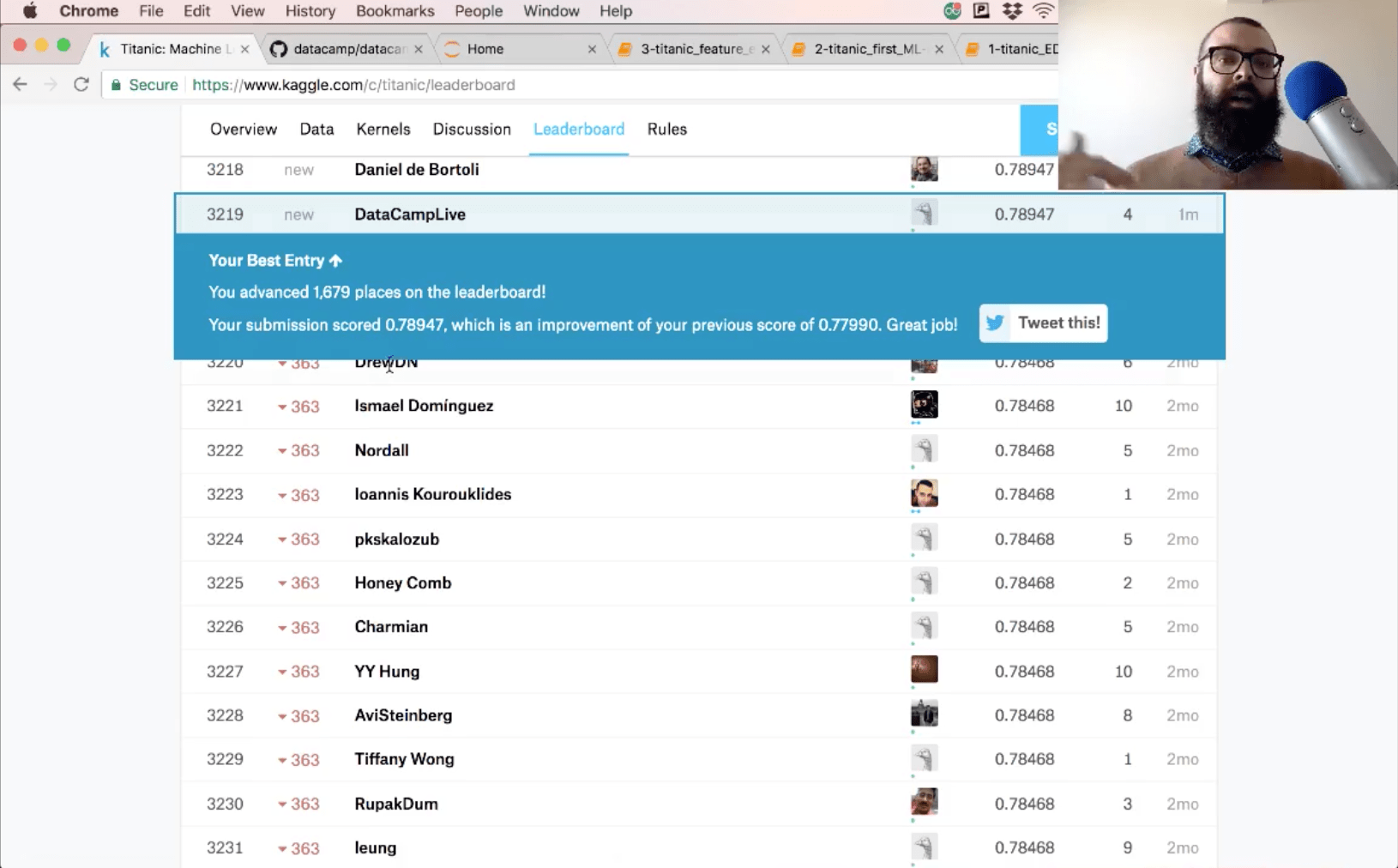
你提交的准确性是78.9。
下一步
看看你是否可以进行更多的特征工程设计, 并尝试一些新的模型来改善此分数。该笔记本和前两个笔记本一起发布在GitHub上, 很高兴看到大家在这些模型上有所改进。
你还需要了解很多预处理特征, 例如扩展数据。你还将发现scikit-learn管道超级有用。查看我们的scikit-learn监督学习课程和scikit-learn文档, 以了解所有其他信息。
评论前必须登录!
注册