 srcmini
srcmini本文概述
编者注:这篇文章是与Milan van der Meer合作撰写的。这篇文章的两位作者都在Real Impact Analytics团队中, 这是一家创新的比利时大数据初创公司, 通过”应用大数据”来捕获电信数据中的价值。
本教程简要介绍了为什么你可能想要生成随机数据集以及对它们的期望。它还将引导你完成一些有关如何使用Trumania(数据生成Python库)的第一个示例。
有关更多信息, 你可以访问Trumania的GitHub!
为什么要生成随机数据集?
生成随机数据集与数据工程师和数据科学家都息息相关。
作为数据工程师, 在编写了新的出色数据处理应用程序之后, 你认为是时候开始进行端到端测试了, 因此你需要一些输入数据。
作为数据科学家, 你可以从数据生成中受益, 因为它允许你尝试各种探索数据集, 算法, 数据可视化技术的方法, 或者针对你选择的许多不同数据集验证关于某种方法的行为的假设。
在这两种情况下, 诱人的选择只是使用实际数据。但是, 一个小问题是, 通常很难甚至部分地难以获取生产数据, 并且随着有关隐私权和安全性的新欧洲法律的出台也变得越来越容易。
也许你是其中的幸运者之一, 你在笔记本电脑上获得了不错的完整生产数据集。即使这样, 你仍希望数据集中具有更多的可变性, 以针对各种情况(例如不同的人口规模, 不同的数据分布, 各种数据质量问题, 例如丢失或无效数据)进行验证…
有关为什么生成随机数据集有用的更多信息, 请访问”为什么合成数据将成为主要的竞争优势”。
基于模式的随机数据生成:我们需要良好的关系!
本节试图说明基于模式的随机数据生成并显示其缺点。
已经存在许多用于生成随机数据集的工具。这些工具中的一种常见方法是基于架构的生成, 它允许你定义蓝图并使用它来生成某些实体。 Khermes和LogSynth是此类工具的两个示例。
基于模式的配置示例可能包括以下人员模式:
{
{
"field": "Name", "class": NameGenerator
}, {
"field": "Age", "class": RandomInt(18, 65)
}, {
"field": "Gender", "class": RandomPicker(["Male", "Female", "Other"])
}
}
此架构定义有关某个人的某些数据的生成。它包含名称, 年龄和性别。它简单, 快速并且有一些限制。一个主要限制是伪造不同实体之间或基于时间的关系。
例如, 如何根据性别使某些名字更有可能?或如何创建用户操作日志, 其中周末更可能发生操作?
基于模式的方法很难使你的新应用程序面临现实世界的特殊性或困难, 例如:
- 数据集不平衡(难以区分按组操作);
- 实体网络中的集群模式。也就是说, 通过用户交互(例如, 电话)发现社交团体;
- 各种时间活动档案。更有可能在一天或一周中的某个时间发生操作;
- 动作之间的因果关系。也就是说, 商店中的许多购买行为最终会触发”缺货”事件。
Trumania基于方案, 以解决这些缺点并生成更实际的数据集。随着场景的发展, 各种种群相互交流, 更新其属性并发出日志。
一个例子就是人们打电话给他们的朋友。当一个人打来电话时, 他们需要在几分钟内付款, 当分钟到了, 他们必须去一家商店…结果数据集可以是用户呼叫日志, 购物行为日志和每小时的库存水平。场景中的动作可以是随机的, 也可以是确定性的。
在Trumania中, 生成的数据集通常是时间序列的, 因为它们是由于执行随时间推移而展开的方案而产生的。
使用Trumania生成相互关联的数据(又称教程时间!)
在下面的示例中, 你将看到如何详细阐述一个基本的方案, 在该方案中, 不同的人会彼此发送消息。结果数据集将是人与人之间交换消息的时间序列。
我们将通过的步骤如下:
- 创建一个Trumania马戏团, 场景将在其中执行
- 添加一个” hello world”的故事, 它将产生基本的硬编码日志
- 添加关系以为每个人分配一些喜欢的引号, 这些引号将用于创建消息的内容。
- 对故事的时间参数进行参数化, 以获得贯穿一天的更真实的消息分布
- 添加另一个关系以定义社交网络, 从消息日志中出现的社交图更加真实
创建一个Trumania马戏团
目的
第一步包括创建一个马戏团, 这是场景中所有元素都将存在的世界。我们还将创造一个基本的人口群体。由于Trumania的许多方面都是随机的, 因此此步骤还将介绍生成器的概念, 该生成器用于控制许多随机行为。
我们现在不会添加任何方案, 因此所有内容都是静态的。
让我们开始吧!
如何
Trumania马戏团的创建简单如下:
from trumania.core import circus
example_circus = circus.Circus(name="example1", master_seed=12345, start=pd.Timestamp("1 Jan 2017 00:00"), step_duration=pd.Timedelta("1h"))
在Trumania中, 所有与时间相关的元素均由中央时钟控制。上面的代码片段中最重要的部分是step_duration = pd.Timedelta(” 1h”), 它定义了时钟将以1小时为单位递增。
接下来, 将人员人口添加到马戏团。人口本质上是一组具有ID和某些属性的代理。
可以手动指定每个属性的值, 但是在大多数情况下, 你希望随机生成它们, 因此让我们首先为它定义一些生成器:
from trumania.core.random_generators import SequencialGenerator, FakerGenerator, NumpyRandomGenerator
id_gen = SequencialGenerator(prefix="PERSON_")
age_gen = NumpyRandomGenerator(method="normal", loc=3, scale=5, seed=next(example_circus.seeder))
name_gen = FakerGenerator(method="name", seed=next(example_circus.seeder))
Trumania生成器负责在调用其方法generate()时提供数据。在上面的示例中, id_gen将生成类似PERSON_0001, PERSON_0002等的字符串。age_gen将重复从正态分布中采样数据, 而name_gen将提供随机的人的名字。
请注意, Trummania中提供了numpy以及Faker提供程序的任何统计分布, 并且可以轻松地用新的扩展Trumania。
通过此操作, 你可以添加具有顺序ID和两个基本随机属性的1000个人:
person = example_circus.create_population(name="person", size=1000, ids_gen=id_gen)
person.create_attribute("NAME", init_gen=name_gen)
person.create_attribute("AGE", init_gen=age_gen)
结果
你已经可以通过调用person.to_dataframe()来查看人员人口中所有成员的生成属性。
+-------------------+-----------------+---------+
| | NAME | age |
|-------------------+-----------------+---------|
| PERSON_0000000000 | Amy Berger | 28.588 |
| PERSON_0000000001 | Michael Curry | 28.7499 |
| PERSON_0000000002 | Robert Ramirez | 35.9242 |
| PERSON_0000000003 | Derek Gonzalez | 34.7091 |
| PERSON_0000000004 | Gregory Fischer | 25.6009 |
| PERSON_0000000005 | Erica Walker | 33.9758 |
| PERSON_0000000006 | Bradley Collins | 24.4428 |
| PERSON_0000000007 | James Rodriguez | 34.7835 |
| PERSON_0000000008 | Brandy Padilla | 34.6296 |
| PERSON_0000000009 | Mark Taylor | 38.2286 |
+-------------------+-----------------+---------+
提示:如果你想查看此基本用户群的完整脚本, 请在Github上查看此片段!
你好世界声明:创建故事
目的
让我们通过添加一个故事来使其更加有趣。 Trumania故事本质上是一个场景, 它封装了一些动态方面。每当模拟时钟向前移动一步时, 都会执行一个故事。
回想一下, 你在上述马戏团中设置了step_duration = pd.Timedelta(” 1h”), 因此这意味着每个逻辑小时, 每个故事都会有机会执行。
你将创建一个简单的hello-world故事, 其中上述人群中的所有成员都会定期发出” hello world”消息。
如何
创建故事时要指定的第一个主要方面是发起故事的人数。在这种情况下, 这将是人。第二方面是定义计时器, 该计时器定义人口中的每个成员何时触发该动作。现在, 你只是将它们硬编码为1, 这意味着所有成员将在每个时钟步骤执行故事(你将在后面的步骤中构建更多复杂的计时器):
hello_world = example_circus.create_story(
name="hello_world", initiating_population=example_circus.populations["person"], member_id_field="PERSON_ID", timer_gen=ConstantDependentGenerator(value=1)
)
到目前为止, 这个故事是空的, 因此它什么也没做:你需要向其中添加一些操作。操作可以是随机的或确定性的, 它们可以读取和更新马戏团中任何人群的属性或其他状态, 甚至有副作用。
现在, 让我们添加两个简单的确定性操作和一个记录器以实际获取一些日志:
hello_world.set_operations(
example_circus.clock.ops.timestamp(named_as="TIME"), ConstantGenerator(value="hello world").ops.generate(named_as="MESSAGE"), FieldLogger(log_id="hello")
)
example_circus.clock.ops.timestamp在当前的1小时时间间隔内生成一个随机时间戳, 而ConstantGenerator仅生成恒定的硬编码值。
结果
让我们在模拟时间的48小时内运行马戏团:
example_circus.run(
duration=pd.Timedelta("48h"), log_output_folder="example_scenario", delete_existing_logs=True
)
这应该产生基本的后续数据集, 其中每1000个人在2天中说48次” hello world”。
结果数据集的第一个字段PERSON_ID对应于故事的member_id_field。其他两个字段TIME和MESSAGE对应于你放置在故事中的两个主要操作。
+-------+-------------------+---------------------+-------------+
| | PERSON_ID | TIME | MESSAGE |
|-------+-------------------+---------------------+-------------|
| 0 | PERSON_0000000000 | 2017-01-01 01:14:12 | hello world |
| 1 | PERSON_0000000001 | 2017-01-01 01:23:51 | hello world |
| 2 | PERSON_0000000002 | 2017-01-01 01:37:11 | hello world |
| 3 | PERSON_0000000003 | 2017-01-01 01:33:12 | hello world |
| 4 | PERSON_0000000004 | 2017-01-01 01:08:02 | hello world |
| 5 | PERSON_0000000005 | 2017-01-01 01:13:36 | hello world |
| 6 | PERSON_0000000006 | 2017-01-01 01:35:08 | hello world |
| 7 | PERSON_0000000007 | 2017-01-01 01:24:30 | hello world |
| 8 | PERSON_0000000008 | 2017-01-01 01:01:51 | hello world |
| 9 | PERSON_0000000009 | 2017-01-01 01:41:41 | hello world |
| ... |
| 23990 | PERSON_0000000990 | 2017-01-02 23:33:28 | hello world |
| 23991 | PERSON_0000000991 | 2017-01-02 23:15:26 | hello world |
| 23992 | PERSON_0000000992 | 2017-01-02 23:45:56 | hello world |
| 23993 | PERSON_0000000993 | 2017-01-02 23:25:16 | hello world |
| 23994 | PERSON_0000000994 | 2017-01-02 23:33:55 | hello world |
| 23995 | PERSON_0000000995 | 2017-01-02 23:41:45 | hello world |
| 23996 | PERSON_0000000996 | 2017-01-02 23:39:23 | hello world |
| 23997 | PERSON_0000000997 | 2017-01-02 23:45:53 | hello world |
| 23998 | PERSON_0000000998 | 2017-01-02 23:29:25 | hello world |
| 23999 | PERSON_0000000999 | 2017-01-02 23:12:24 | hello world |
+-------+-------------------+---------------------+-------------+
提示:在Github上查看整个代码段
有人向
目的
让我们通过在对话中添加另一个随机的人来改善这一点。现在, 你将要说的是, 任何人都可以以相同的概率与任何其他人说话, 这不太现实(你将在以后的步骤中添加一个社交网络)。另外, 你将通过基于人们的ID添加人们的姓名来丰富数据集。
如何
假设其他人将被存储在新的OTHER_PERSON字段中。在这种简单的情况下, 你只想在该字段中输入从人员总体中随机进行未加权选择的结果。你可以简单地使用该总体的select_one随机操作:
example_circus.set_operations(
example_circus.clock.ops.timestamp(named_as="TIME"), ConstantGenerator(value="hello world").ops.generate(named_as="MESSAGE"), example_circus.populations["person"].ops.select_one(named_as="OTHER_PERSON"), example_circus.populations["person"]
.ops.lookup(id_field="PERSON_ID", select={"NAME": "EMITTER_NAME"}), example_circus.populations["person"]
.ops.lookup(id_field="OTHER_PERSON", select={"NAME": "RECEIVER_NAME"}), FieldLogger(log_id="hello")
)
结果
再次运行马戏团时, 最终得到的数据集带有新的OTHER_PERSON字段:
+-------+-------------------+---------------------+-------------+-------------------+---------------------+--------------------+
| | PERSON_ID | TIME | MESSAGE | OTHER_PERSON | EMITTER_NAME | RECEIVER_NAME |
|-------+-------------------+---------------------+-------------+-------------------+---------------------+--------------------|
| 0 | PERSON_0000000000 | 2017-01-01 01:14:12 | hello world | PERSON_0000000852 | Ann Cruz | Sophia Black |
| 1 | PERSON_0000000001 | 2017-01-01 01:23:51 | hello world | PERSON_0000000429 | Kimberly Sanchez | Jeffrey Ryan |
| 2 | PERSON_0000000002 | 2017-01-01 01:37:11 | hello world | PERSON_0000000925 | Bethany Smith | Regina Brown |
| 3 | PERSON_0000000003 | 2017-01-01 01:33:12 | hello world | PERSON_0000000347 | Frank Middleton | Jacob Ross |
| 4 | PERSON_0000000004 | 2017-01-01 01:08:02 | hello world | PERSON_0000000211 | Cheryl Decker | Joshua Miller |
| 5 | PERSON_0000000005 | 2017-01-01 01:13:36 | hello world | PERSON_0000000779 | Thomas Rodriguez | Nicole Tanner |
| 6 | PERSON_0000000006 | 2017-01-01 01:35:08 | hello world | PERSON_0000000331 | James Peters | Melissa Rogers |
| 7 | PERSON_0000000007 | 2017-01-01 01:24:30 | hello world | PERSON_0000000234 | Allison Hansen | Taylor Smith |
| 8 | PERSON_0000000008 | 2017-01-01 01:01:51 | hello world | PERSON_0000000678 | Candice Sellers | James Smith |
| 9 | PERSON_0000000009 | 2017-01-01 01:41:41 | hello world | PERSON_0000000108 | Maria White | James Nguyen |
| ... |
| 23990 | PERSON_0000000990 | 2017-01-02 23:33:28 | hello world | PERSON_0000000689 | Natasha Brown | Bailey Ramirez DDS |
| 23991 | PERSON_0000000991 | 2017-01-02 23:15:26 | hello world | PERSON_0000000250 | Shelly Ponce | Jordan Johnson |
| 23992 | PERSON_0000000992 | 2017-01-02 23:45:56 | hello world | PERSON_0000000413 | Steven Mendez | Crystal Duffy |
| 23993 | PERSON_0000000993 | 2017-01-02 23:25:16 | hello world | PERSON_0000000670 | Morgan Rice | Jonathan Obrien |
| 23994 | PERSON_0000000994 | 2017-01-02 23:33:55 | hello world | PERSON_0000000411 | Crystal Vincent | George Mathis |
| 23995 | PERSON_0000000995 | 2017-01-02 23:41:45 | hello world | PERSON_0000000563 | Dawn Kim | Jennifer Martinez |
| 23996 | PERSON_0000000996 | 2017-01-02 23:39:23 | hello world | PERSON_0000000668 | Jimmy Franco | Dr. Mark Ruiz MD |
| 23997 | PERSON_0000000997 | 2017-01-02 23:45:53 | hello world | PERSON_0000000268 | Christian Christian | Victoria Donovan |
| 23998 | PERSON_0000000998 | 2017-01-02 23:29:25 | hello world | PERSON_0000000829 | David Hernandez | Margaret Anderson |
| 23999 | PERSON_0000000999 | 2017-01-02 23:12:24 | hello world | PERSON_0000000944 | Tamara Ramirez | Andrew Curtis |
+-------+-------------------+---------------------+-------------+-------------------+---------------------+--------------------+
提示:你可以在此处查看完整的代码
你总这样说
目的
让我们通过在MESSAGE字段中生成一个随机语句而不是无聊的hello world硬编码字符串来进一步改进。这将使你能够说明Trumania关系的第一个基本用法。
你将每个人与4个引号相关联。每当有人发出消息时, 内容就会从该人的4个引号中挑选出来。此外, 你将使每个报价具有不同的权重, 从而定义该报价的可能性:具有高权重的报价的所有者将比具有低权重的报价更频繁地发出报价。
现在, 你如何开始?
如何
第一步是创建一个报价生成器, 它类似于你在上面看到的其他Faker生成器:
quote_generator = FakerGenerator(method="sentence", nb_words=6, variable_nb_words=True, seed=next(example_circus.seeder))
你可以像以前一样在故事中按原样使用该生成器, 但是通过限制每个人始终使用其4个最喜欢的引号中的一个, 让事情变得更有趣。通过在人员群体的成员与某些句子值之间建立关系来实现此目的。
首先, 创建一个空关系:
quotes_rel = example_circus.populations["person"].create_relationship("quotes")
然后, 用每个人的4个引号填充此关系。在下面的代码中person.ids是一个大小为1000的pandas系列, 其中包含所有人员种群的id, quote_generator.generate(size = person.size)提供了另一个大小为1000的熊猫系列, 带有随机引号。
这意味着下面的for循环的每一遍都会在关系中填充1000个关系:向1000个用户中的每个用户添加一个引号。前1000个引号将与weight = 1相关联, 而下一个引号将与weight = 2相关联…
for w in range(4):
quotes_rel.add_relations(
from_ids=person.ids, to_ids=quote_generator.generate(size=person.size), weights=w
)
现在, 你可以将故事中的ConstantGenerator替换为对该关系的select_one操作。内容如下:对于当前在PERSON_ID字段中的每个值, 请查找以该ID开头的引号中的关系, 并随机选择一个相关值。由于在以下操作中不会覆盖任何权重, 因此将使用上面在add_relations中定义的默认关系权重:
example_circus.set_operations(
example_circus.clock.ops.timestamp(named_as="TIME"), example_circus.populations["person"].get_relationship("quotes")
.ops.select_one(from_field="PERSON_ID", named_as="MESSAGE"), example_circus.populations["person"].ops.select_one(named_as="OTHER_PERSON"), example_circus.populations["person"]
.ops.lookup(id_field="PERSON_ID", select={"NAME": "EMITTER_NAME"}), example_circus.populations["person"]
.ops.lookup(id_field="OTHER_PERSON", select={"NAME": "RECEIVER_NAME"}), FieldLogger(log_id="hello")
)
结果
运行马戏团时, MESSAGE字段现在应包含随机引号:
+-------+-------------------+---------------------+-----------------------------------------------------+-------------------+---------------------+---------------------+
| | PERSON_ID | TIME | MESSAGE | OTHER_PERSON | EMITTER_NAME | RECEIVER_NAME |
|-------+-------------------+---------------------+-----------------------------------------------------+-------------------+---------------------+---------------------|
| 0 | PERSON_0000000000 | 2017-01-01 01:14:12 | Become period risk wait now toward less. | PERSON_0000000158 | Ann Cruz | Victoria Washington |
| 1 | PERSON_0000000001 | 2017-01-01 01:23:51 | Month push down. | PERSON_0000000366 | Kimberly Sanchez | Steven Williams |
| 2 | PERSON_0000000002 | 2017-01-01 01:37:11 | Blue general carry else deep problem area. | PERSON_0000000613 | Bethany Smith | Frances Davis |
| 3 | PERSON_0000000003 | 2017-01-01 01:33:12 | Phone sister pretty suddenly allow conference. | PERSON_0000000086 | Frank Middleton | Ashley Fernandez |
| 4 | PERSON_0000000004 | 2017-01-01 01:08:02 | Each discussion several send wide process. | PERSON_0000000972 | Cheryl Decker | Latoya Flynn |
| 5 | PERSON_0000000005 | 2017-01-01 01:13:36 | Guess can issue writer. | PERSON_0000000030 | Thomas Rodriguez | Lindsay Bailey |
| 6 | PERSON_0000000006 | 2017-01-01 01:35:08 | Boy step claim camera common but our. | PERSON_0000000548 | James Peters | Thomas Ward |
| ... | 23993 | PERSON_0000000993 | 2017-01-02 23:25:16 | May course and kill from news. | PERSON_0000000202 | Morgan Rice | Patricia Williams |
| 23994 | PERSON_0000000994 | 2017-01-02 23:33:55 | Water door live hospital together safe. | PERSON_0000000268 | Crystal Vincent | Victoria Donovan |
| 23995 | PERSON_0000000995 | 2017-01-02 23:41:45 | Stage control management read although thousand. | PERSON_0000000466 | Dawn Kim | Ashley Baxter |
| 23996 | PERSON_0000000996 | 2017-01-02 23:39:23 | Their that region majority break article. | PERSON_0000000620 | Jimmy Franco | Alex Dominguez |
| 23997 | PERSON_0000000997 | 2017-01-02 23:45:53 | Lead simple audience response eye. | PERSON_0000000319 | Christian Christian | David Smith |
| 23998 | PERSON_0000000998 | 2017-01-02 23:29:25 | Vote man son yeah child. | PERSON_0000000487 | David Hernandez | Joshua Park |
| 23999 | PERSON_0000000999 | 2017-01-02 23:12:24 | Answer region wind condition someone bed cover. | PERSON_0000000237 | Tamara Ramirez | Beverly Rodriguez |
+-------+-------------------+---------------------+-----------------------------------------------------+-------------------+---------------------+---------------------+
用于引号的关系的要点在于, 现在生成的数据集的字段已相关:某些用户更常使用某些句子。
提示:在Github上查看完整的代码段
不是你在做什么, 是时候去做
目的
到目前为止, 人口中的每个成员每天每天仅发出一则消息。让我们更现实一些。
Trumania使用两个概念的组合来控制故事执行的时间方面:活动级别和计时器配置文件。它们共同确定了特定用户和一天中的特定时间触发故事的可能性。
如何
你将更新故事并参数化这两个方面。
首先, 让我们创建故事的计时器配置文件, 它控制触发更多或更少动作的时刻。对于触发该故事的所有人口, 此配置文件都是相同的。
Trumania内置了一些有趣的默认电话, 例如DefaultDailyTimerGenerator, 它对应于我们在实际生产数据集上测得的每日电话使用量:

让我们在你的场景中实例化一个:
from trumania.components.time_patterns.profilers import DefaultDailyTimerGenerator
story_timer_gen = DefaultDailyTimerGenerator(
clock=example_circus.clock, seed=next(example_circus.seeder))
其次, 该故事有人口成员的活动级别, 该活动级别定义了该故事中每个用户的活跃程度。你可以为每个成员设置不同的级别, 这样某些成员会比其他成员或多或少地触发该动作。
你可以根据需要手动指定每个级别, 尽管这里只是使用随机生成器为每个人口成员分配活动级别。
首先, 我们定义了三个活动级别, 平均每天3、10和20个触发器:
low_activity = story_timer_gen.activity(n=3, per=pd.Timedelta("1 day"))
med_activity = story_timer_gen.activity(n=10, per=pd.Timedelta("1 day"))
high_activity = story_timer_gen.activity(n=20, per=pd.Timedelta("1 day"))
然后, 你可以根据选择方法创建实际的活动生成器, 这将是另一个Numpy生成器。以下一项将为20%的人口分配低活动度, 为70%的人口分配中等活动度, 为10%的人口分配高活动度:
activity_gen = NumpyRandomGenerator(
method="choice", a=[low_activity, med_activity, high_activity], p=[.2, .7, .1], seed=next(example_circus.seeder))
现在, 你可以将此计时器配置文件和活动生成器用作故事的一部分:
hello_world = example_circus.create_story(
name="hello_world", initiating_population=example_circus.populations["person"], member_id_field="PERSON_ID", timer_gen=story_timer_gen, activity_gen=activity_gen
)
结果
结果数据集具有与以前相同的架构:
+-------+-------------------+---------------------+---------------------------------------------------------+-------------------+---------------------+----------------------+
| | PERSON_ID | TIME | MESSAGE | OTHER_PERSON | EMITTER_NAME | RECEIVER_NAME |
|-------+-------------------+---------------------+---------------------------------------------------------+-------------------+---------------------+----------------------|
| 0 | PERSON_0000000016 | 2017-01-01 00:14:12 | Still try sex sure. | PERSON_0000000739 | Johnny Moore | Adam Barrett |
| 1 | PERSON_0000000063 | 2017-01-01 00:23:51 | Resource magazine wide. | PERSON_0000000511 | Cody Pham | Tina Simmons |
| 2 | PERSON_0000000064 | 2017-01-01 00:37:11 | Heat sure simple letter better forget. | PERSON_0000000044 | Katherine Fleming | Angela Gray |
| 3 | PERSON_0000000076 | 2017-01-01 00:33:12 | Star our conference always place ball. | PERSON_0000000959 | Benjamin Reese II | Barbara Alexander |
| 4 | PERSON_0000000088 | 2017-01-01 00:08:02 | Hot event five left become time commercial. | PERSON_0000000000 | Zachary Cook | Ann Cruz |
| ... |
| 28556 | PERSON_0000000962 | 2017-01-04 00:07:45 | Then include rock rule scientist condition. | PERSON_0000000448 | Johnny Washington | Melissa Adams |
| 28557 | PERSON_0000000980 | 2017-01-04 00:04:44 | Collection full argue interview property pattern never. | PERSON_0000000731 | James Ramirez | David Morrow |
| 28558 | PERSON_0000000983 | 2017-01-04 00:23:21 | High day prepare see. | PERSON_0000000509 | Evan Horne | Robert Sims |
| 28559 | PERSON_0000000988 | 2017-01-04 00:43:56 | Likely south school result case federal seat. | PERSON_0000000819 | Benjamin Campbell | Michelle Jackson DDS |
+-------+-------------------+---------------------+---------------------------------------------------------+-------------------+---------------------+----------------------+
提示:在Github上查看代码段
结果分析
现在, 你在方案配置中包括的时间模式应该在结果数据集的内部结构中可见。你可以通过对结果的所得数据集进行基本数据分析来证明这一点:
- 每天每一小时的消息数应遵循指定的分布(请注意, 其与上面的DefaultDailyTimerGenerator的曲线有多相似):
time_profile = (
resulting_dataset[["MESSAGE", "TIME"]]
.groupby(by=example_5_df.TIME.dt.hour)["MESSAGE"]
.count()
)
time_profile.plot()

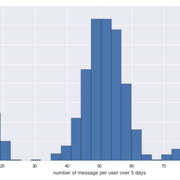
- 每个用户的邮件数量直方图也应遵循你的配置:
- 你将low_activity平均配置为每天3条消息, 将med_activity配置为10条消息, 将high_activity配置为20条消息, 并在5天内运行了模拟。这应该产生3组人, 总共有大约15、50和100条消息, 这对应于下面的直方图的3个中心
- 你将这些活动级别的概率配置为.2, .7和.1, 这再次大致对应于直方图的每个”凹凸”区域:
usage_per_user = resulting_dataset[["MESSAGE", "PERSON_ID"]].groupby("PERSON_ID")["MESSAGE"].count()
usage_per_user.plot(kind="hist")
社交网络
目的
你可以通过联系人们, 使他们在执行故事过程中将消息发送给他们的朋友, 而不是随意发送给朋友, 从而进一步改善场景。由于现在应该可以从消息日志中发现社交图, 因此这将为结果数据集引入很多结构。
如何
你可以再次使用”关系”对社交网络进行建模, 这与上面对报价建模所使用的概念相同。你可能还记得报价关系很重要。这个权重定义了给定一个人或多或少的报价。你可以在此处执行相同的操作, 并使用权重来定义与其他朋友相比, 哪些朋友更有可能被称为。
请注意, 尽管一般而言, Trumania允许你定义任何一对人口之间的关系, 但你在这里定义的是人与人之间的关系。
有很多方法可以生成社交图的边缘。一种基本而经典的方法就是简单地依靠Erdos-Renyi算法。在Trumania中, 这特别容易, 因为它已经内置在框架中。你只需要将其注入到场景中即可创建关系。
在这里, 你将定义人际关系成员之间的社交图, 其中每个人都有20个朋友。请注意, 权重将通过帕累托分布自动添加到该关系中。
from trumania.components.social_networks.erdos_renyi import WithErdosRenyi
# self is the circus here, see example code on github for details
self.add_er_social_network_relationship(
self.populations["person"], relationship_name="friends", average_degree=20)
有了这种关系, 你就可以再次回顾我们的故事。这次, OTHER_PERSON将不再在人口中随机选择, 而是在每个人的朋友中选择, 其概率与社交网络中定义的权重成正比:
hello_world.set_operations(
self.clock.ops.timestamp(named_as="TIME"), self.populations["person"].get_relationship("quotes")
.ops.select_one(from_field="PERSON_ID", named_as="MESSAGE"), self.populations["person"]
.get_relationship("friends")
.ops.select_one(from_field="PERSON_ID", named_as="OTHER_PERSON"), self.populations["person"]
.ops.lookup(id_field="PERSON_ID", select={"NAME": "EMITTER_NAME"}), self.populations["person"]
.ops.lookup(id_field="OTHER_PERSON", select={"NAME": "RECEIVER_NAME"}), operations.FieldLogger(log_id="hello_6")
)
结果
再次, 生成的数据集具有与以前相同的数据模式, 尽管这次有了基本的社交网络, 它的结构比以前更大了:
+-------+-------------------+---------------------+----------------------------------------------------+-------------------+-------------------+------------------+
| | PERSON_ID | TIME | MESSAGE | OTHER_PERSON | EMITTER_NAME | RECEIVER_NAME |
|-------+-------------------+---------------------+----------------------------------------------------+-------------------+-------------------+------------------|
| 0 | PERSON_0000000004 | 2017-01-01 00:14:12 | Clearly see sure. | PERSON_0000000321 | Cheryl Decker | Ian White |
| 1 | PERSON_0000000012 | 2017-01-01 00:23:51 | Offer or interview clear structure watch capital. | PERSON_0000000697 | Kelly Green | Ashley Turner |
| 2 | PERSON_0000000018 | 2017-01-01 00:37:11 | Recently race draw thousand around ahead. | PERSON_0000000989 | Laura Stephenson | Hannah James |
| 3 | PERSON_0000000040 | 2017-01-01 00:33:12 | To protect man image power beyond. | PERSON_0000000418 | Jeffrey Miller | Scott Collins |
... |
| 28966 | PERSON_0000000985 | 2017-01-04 00:09:23 | However agreement fear door land hotel. | PERSON_0000000211 | Laura Mason | Joshua Miller |
| 28967 | PERSON_0000000995 | 2017-01-04 00:48:08 | Top heat window quite forward friend somebody. | PERSON_0000000171 | Dawn Kim | Sandra Phillips |
| 28968 | PERSON_0000000999 | 2017-01-04 00:58:46 | Answer region wind condition someone bed cover. | PERSON_0000000252 | Tamara Ramirez | Jordan Collins |
+-------+-------------------+---------------------+----------------------------------------------------+-------------------+-------------------+------------------+
提示:你可以在Github上查看代码段
结果分析
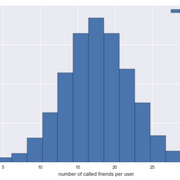
调查该社交网络的一种非常原始的方法只是简单地计算每个人所呼叫的唯一朋友的数量。如果你进行足够长时间的模拟, 这应该为每个人的社交网络中的实际人数提供一个较低的界限(由于你使用带有Pareto分布的权重, 因此许多人的朋友确实不太可能被称为, 因此你需要进行长时间的模拟, 才能真正观察每个可能被叫的人)。
你在15个模拟天中执行了我们的方案, 并获得了该值, 该值的中心非常接近并且低于你在社交图中设置的平均20度:
social_group_size = (
resulting_dataset[["PERSON_ID", "OTHER_PERSON"]]
.groupby("PERSON_ID")
.agg(lambda friends_ids: len(friends_ids.unique()))
)
social_group_size.plot(kind="hist")
还有更多 !
这篇文章中没有描述Trumania的几个功能:
- 在一个场景中有几个人口
- 在场景中有几个故事
- 在故事之间添加概率依存关系(例如, 某人在被叫后打电话给朋友)
- 状态更新(例如, 根据通话时间减少余额帐户)
- 可重用的场景片段, 例如地理位置, 更多计时器配置文件, …
- 场景的持久性
总结
我们在Python中引入了Trumania作为基于场景的数据生成器库。生成的数据集可用于广泛的应用程序, 例如测试, 学习和基准测试。
我们解释说, 为了正确测试应用程序或算法, 我们需要尊重某些预期统计属性的数据集。我们举例说明了Trumania能够做到这一点, 在该示例中, 我们生成了一个基本的”消息日志”数据集, 该数据集尊重每个用户的消息数分布, 一天中的时间分布以及社交图之间的呼叫分布。
我们希望我们也证明了Trumania组件的灵活性可以创建各种各样的场景。
Trumania场景可以包括实体之间的关系, 并且可以用理论随机分布, 在实际数据集中甚至实际生产数据(例如位置ID的数据集)中观察到的经验分布进行配置。我们证明了通过重新使用在实际数据集中观察到的电话使用时间戳的统计分布来配置我们故事的时间随机计时器。
考虑到这一点, 发疯!转到Trumania的Github并编写你自己的场景;)
否则, 请随时与Svend Vanderveken或合著者Milan van der Meer联系:
- Svend Vanderveken是一位自由软件工程师, 在数据处理解决方案方面拥有丰富的专业知识, 主要是在Kafka, Scala, SQL, python ……通过他的博客svend.kelesia.com和twitter @ sv3ndk关注他。
- Milan van der Meer目前是Real Impact Analytics的软件工程师。你可以随时在LinkedIn上与他联系
评论前必须登录!
注册