 srcmini
srcmini本文概述
建立你的第一个机器学习模型
有了探索性数据分析(EDA)和基线模型, 你就可以开始研究第一个真正的机器学习模型。
请注意, 本教程基于会话中的Facebook Live代码。你可以在这里重新观看:
在开始之前, 请导入所有必需的库:
# Import modules
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import re
import numpy as np
from sklearn import tree
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
# Figures inline and set visualization style
%matplotlib inline
sns.set()
# Import data
df_train = pd.read_csv('data/train.csv')
df_test = pd.read_csv('data/test.csv')
- 在下面, 你将从训练数据集中删除目标”幸存”, 并创建一个新的DataFrame数据, 其中包含训练和测试集。这样做是因为你要对数据进行一点预处理, 并确保对测试数据集执行的所有操作也都在测试数据集上完成。
- 但首先, 你将存储训练数据的目标变量以安全保存。
# Store target variable of training data in a safe place
survived_train = df_train.Survived
# Concatenate training and test sets
data = pd.concat([df_train.drop(['Survived'], axis=1), df_test])
- 使用info()方法签出新的DataFrame数据。
data.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1309 entries, 0 to 417
Data columns (total 11 columns):
PassengerId 1309 non-null int64
Pclass 1309 non-null int64
Name 1309 non-null object
Sex 1309 non-null object
Age 1046 non-null float64
SibSp 1309 non-null int64
Parch 1309 non-null int64
Ticket 1309 non-null object
Fare 1308 non-null float64
Cabin 295 non-null object
Embarked 1307 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 122.7+ KB
有2个数值变量缺少值。
这些是什么?
没错, 你缺少”年龄”和”票价”列的值!在上面的.info()方法的结果中, 你看到第一列缺少263个值, 因为你的DataFrame的总共1309个条目只有1046个非空值。理想情况下, 你当然希望所有这些1309都具有非null值, 但事实并非如此!
幸运的是, 你仅在票价列中缺少一个。还要注意, ” Cabin”和” Embarked”也缺少值, 你需要在某些时候进行处理。
但是, 现在你将专注于固定数字变量:你将使用知道这些变量的中间值来估算或填写”年龄”和”票价”列的缺失值。
请注意, 在这种情况下, 请使用中位数, 因为它非常适合处理离群值。换句话说, 当数据分布偏斜时, 中位数很有用。推算缺失值的其他方法是使用均值, 你可以通过将所有数据点相加并除以数据点数或众数(即出现次数最多的众数)来找到平均值。
# Impute missing numerical variables
data['Age'] = data.Age.fillna(data.Age.median())
data['Fare'] = data.Fare.fillna(data.Fare.median())
# Check out info of data
data.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1309 entries, 0 to 417
Data columns (total 11 columns):
PassengerId 1309 non-null int64
Pclass 1309 non-null int64
Name 1309 non-null object
Sex 1309 non-null object
Age 1309 non-null float64
SibSp 1309 non-null int64
Parch 1309 non-null int64
Ticket 1309 non-null object
Fare 1309 non-null float64
Cabin 295 non-null object
Embarked 1307 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 122.7+ KB
看起来已经好多了, 对!
还要注意, 在上一教程和笔记本中, 你具有一堆要用于预测的功能, 因为从探索性数据分析中注意到, 它们对于”生存”至关重要。这些功能之一是”票价”, 但”年龄”和”性”也是其他特征!
但是, 你想使用数字对数据进行编码, 因此需要将” male”和” female”更改为数字。这样做是因为大多数机器学习模型都使用数字输入功能。你可以使用熊猫函数.get_dummies()这样做:
data = pd.get_dummies(data, columns=['Sex'], drop_first=True)
data.head()
| 旅客编号 | P类 | 名称 | 年龄 | 锡卜 | 版本号 | 票 | 做 | 舱 | 出发 | 性别男 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 3 | 布朗德, 欧文·哈里斯先生 | 22.0 | 1 | 0 | A / 5 21171 | 7.2500 | NaN | 小号 | 1 |
| 1 | 2 | 1 | 卡明斯, 约翰·布拉德利夫人(佛罗伦萨·布里格斯·托… | 38.0 | 1 | 0 | 电脑17599 | 71.2833 | C85 | C | 0 |
| 2 | 3 | 3 | 海基宁小姐贷款 | 26.0 | 0 | 0 | STON / O2。 3101282 | 7.9250 | NaN | 小号 | 0 |
| 3 | 4 | 1 | Futrelle, Jacques Heath夫人(莉莉·梅·皮尔) | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | 小号 | 0 |
| 4 | 5 | 3 | 艾伦·威廉·亨利先生 | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | 小号 | 1 |
.get_dummies()允许你为”性”中的每个选项创建一个新列。因此, 它为女性创建了一个新列, 称为” Sex_female”, 然后为” Sex_male”创建了一个新列, 该列编码该行是男性还是女性。
现在, 由于在上面的代码行中添加了drop_first参数, 因此删除了” Sex_female”, 因为从本质上讲, 这些新列” Sex_female”和” Sex_male”对相同的信息进行编码。
因此, 你要做的就是创建一个新列’Sex_male’, 如果该行是男性, 则为1;如果该行是女性, 则为0。
在进行机器学习的数据处理时, .get_dummies()将是你最好的朋友之一!
- 现在, 你将从DataFrame中选择列[‘Sex_male’, ‘Fare’, ‘Age’, ‘Pclass’, ‘SibSp’], 以建立你的第一个机器学习模型:
# Select columns and view head
data = data[['Sex_male', 'Fare', 'Age', 'Pclass', 'SibSp']]
data.head()
| 性别男 | 做 | 年龄 | P类 | 锡卜 | |
|---|---|---|---|---|---|
| 0 | 1 | 7.2500 | 22.0 | 3 | 1 |
| 1 | 0 | 71.2833 | 38.0 | 1 | 1 |
| 2 | 0 | 7.9250 | 26.0 | 3 | 0 |
| 3 | 0 | 53.1000 | 35.0 | 1 | 1 |
| 4 | 1 | 8.0500 | 35.0 | 3 | 0 |
- 使用.info()签出数据:
data.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1309 entries, 0 to 417
Data columns (total 5 columns):
Sex_male 1309 non-null uint8
Fare 1309 non-null float64
Age 1309 non-null float64
Pclass 1309 non-null int64
SibSp 1309 non-null int64
dtypes: float64(2), int64(2), uint8(1)
memory usage: 52.4 KB
现在所有条目都不为空。做得好!
到目前为止, 你已经以某种形式获得了数据以构建第一个机器学习模型。这意味着你最终可以构建你的第一个机器学习模型!
有关熊猫的更多信息, 请查看我们的Python数据处理指南。
建立决策树分类器
什么是决策树分类器?它是一棵树, 允许你根据特征变量对数据点进行分类, 这些数据点也称为目标变量。
例如, 下面的树具有一个根节点, 该根节点根据以下问题迫使你做出第一个决定:” Sex_male”是否小于0.5?换句话说, 数据点是女性。如果该问题的答案为”真”, 则可以向左转到”幸存”。如果为False, 则向右走, 将显示” Dead”。
现在, 你无需担心在节点中看到的所有其他信息, 例如gini, 样本或值。你可以稍后查看所有这些信息!
- 首先, 你需要将这样的模型拟合到训练数据中, 这意味着(基于训练数据)决定哪些决策将在树中的每个分支点进行拆分。例如, 第一个分支是否在”雄性”上, 而”雄性”导致对”死亡”的预测。
请注意, 实际上是用于做出这些决定的基尼系数。在这一点上, 你将不再深入研究这些东西。
- 在将模型拟合到数据之前, 将其拆分回训练集和测试集:
data_train = data.iloc[:891]
data_test = data.iloc[891:]
- 你将使用scikit-learn, 它需要将数据作为数组而不是DataFrames进行转换:
X = data_train.values
test = data_test.values
y = survived_train.values
- 现在你可以构建决策树分类器!首先创建一个具有max_depth = 3的模型, 然后将其拟合为你的数据。请注意, 你将模型命名为clf, 它是”分类器”的缩写。
# Instantiate model and fit to data
clf = tree.DecisionTreeClassifier(max_depth=3)
clf.fit(X, y)
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=3, max_features=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, presort=False, random_state=None, splitter='best')
特征变量X是传递给.fit()方法的第一个参数, 而目标变量y是第二个参数。
输出告诉你所有有关你刚刚构建的决策树分类器的知识:例如, 你看到最大深度设置为3。
- 现在, 你将对测试集进行预测, 创建一个新列” Survived”并将其存储在其中。将df_test的’PassengerId’和’Survived’列保存到.csv并提交给Kaggle。
# Make predictions and store in 'Survived' column of df_test
Y_pred = clf.predict(test)
df_test['Survived'] = Y_pred
df_test[['PassengerId', 'Survived']].to_csv('data/predictions/1st_dec_tree.csv', index=False)
- 根据Kaggle的报告, 你的模型的准确性是多少?
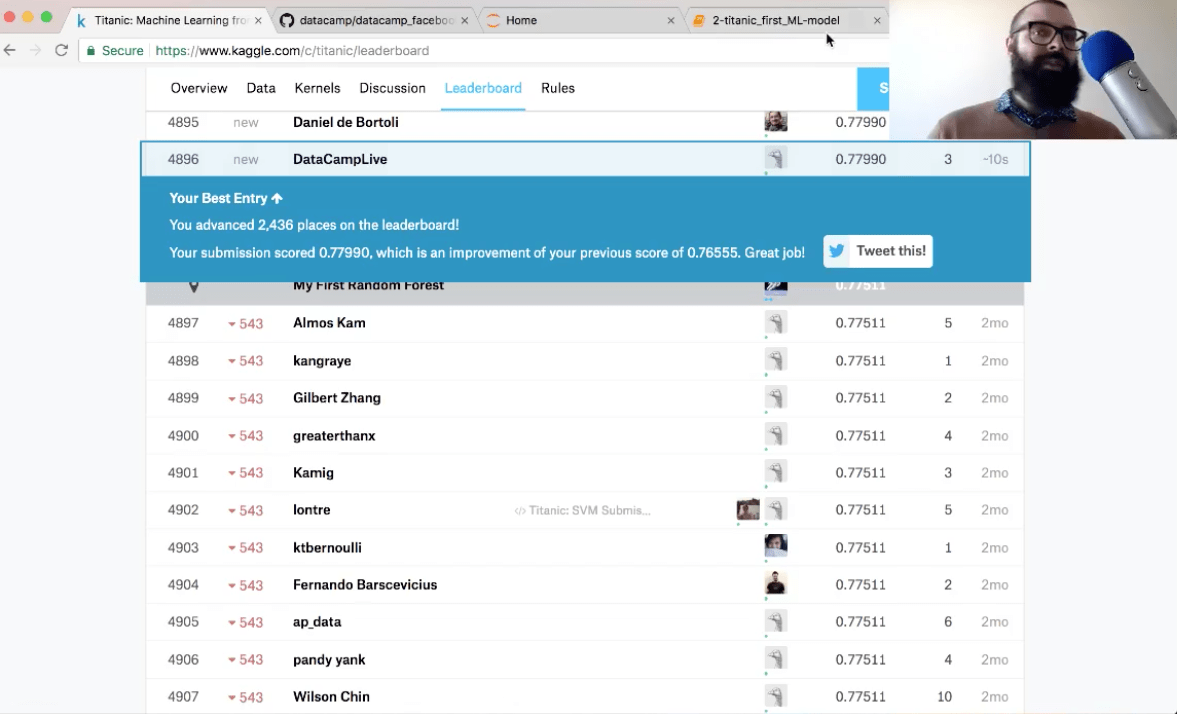
准确度为78%。你已经晋升了2, 000多个地方!
恭喜, 你已将数据以某种形式构建了第一个机器学习模型。最重要的是, 你还建立了第一个机器学习模型:决策树分类器。
现在, 你将弄清楚max_depth参数是什么, 为什么选择它, 并探索train_test_split。
有关scikit-learn的更多信息, 请查看我们的scikit-learn指导学习课程。
什么是决策树分类器?
你刚刚构建的决策树分类器具有max_depth = 3, 它看起来像这样:

第一个决策与最后一个决策之间的最大距离为3, 因此max_depth = 3。
注意:你可以使用graphviz生成这样的图形。有关更多详细信息, 请参见此处的scikit-learn文档。
在构建此模型时, 你实际上要做的是在特征变量的空间中创建决策边界, 例如(此处的图像):

为什么选择max_depth = 3?
树的深度称为超参数, 这意味着在将模型拟合到数据之前需要确定一个参数。如果选择较大的max_depth, 则会获得更复杂的决策边界。
- 如果决策边界太复杂, 则可以过度拟合数据, 这意味着你的模型将描述噪声和信号。
- 如果你的max_depth太小, 则可能是数据拟合不足, 这意味着你的模型包含的信号不足。
但是, 如何判断你是过度拟合还是拟合不足?
注意:这也称为偏差方差折衷;你不会在此处详细说明, 但我们只想完整地提及它!
一种方法是从训练数据中保留测试集。然后, 你可以使模型适合你的训练数据, 在测试集上进行预测, 并查看你的预测在测试集上的表现如何。
- 现在, 你将执行以下操作:将原始训练数据分为训练和测试集:
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=42, stratify=y)
- 现在, 你将迭代从1到9的max_depth值, 并在训练和测试集上绘制模型的准确性:
# Setup arrays to store train and test accuracies
dep = np.arange(1, 9)
train_accuracy = np.empty(len(dep))
test_accuracy = np.empty(len(dep))
# Loop over different values of k
for i, k in enumerate(dep):
# Setup a Decision Tree Classifier
clf = tree.DecisionTreeClassifier(max_depth=k)
# Fit the classifier to the training data
clf.fit(X_train, y_train)
#Compute accuracy on the training set
train_accuracy[i] = clf.score(X_train, y_train)
#Compute accuracy on the testing set
test_accuracy[i] = clf.score(X_test, y_test)
# Generate plot
plt.title('clf: Varying depth of tree')
plt.plot(dep, test_accuracy, label = 'Testing Accuracy')
plt.plot(dep, train_accuracy, label = 'Training Accuracy')
plt.legend()
plt.xlabel('Depth of tree')
plt.ylabel('Accuracy')
plt.show()

随着max_depth的增加, 你将越来越适合训练数据, 因为你将做出描述训练数据的决策。训练数据的准确性会不断提高, 但是你会发现测试数据不会发生这种情况:你拟合过度。
这就是为什么你选择max_depth = 3。
总结
在本教程中, 你将以某种形式获取数据以构建第一个机器学习模型。 Nex, 你还建立了第一个机器学习模型:决策树分类器。最后, 你了解了train_test_split及其如何帮助我们选择ML模型超参数。
在2018年1月10日出现在srcmini社区的下一个教程中, 你将学习如何设计一些新功能并构建一些新模型!
同时, 如果你想了解更多关于scikit-learn的信息, 请查看srcmini的scikit-learn监督学习课程。
评论前必须登录!
注册