 srcmini
srcmini本文概述
这篇博客文章将为你介绍Chris Moody在2016年发布的主题模型lda2vec。lda2vec扩展了Mikolov等人描述的word2vec模型。于2013年推出主题和文档载体, 并融合了词嵌入和主题模型的构想。
主题模型的总体目标是产生可解释的文档表示形式, 该表示形式可用于发现未标记文档集合中的主题或结构。这种可解释的文档表示形式的示例是:文档X为20%的主题a, 40%的主题b和40%的主题c。
今天的帖子将首先介绍潜在的Dirichlet分配(LDA)。 LDA是一种概率主题模型, 它将文档视为一堆单词, 因此你将首先探讨这种方法的优缺点。
另一方面, lda2vec在单词嵌入的基础上构建文档表示形式。你将了解有关单词嵌入的更多信息, 以及为什么它们目前是自然语言处理(NLP)模型中首选的构建基块。
最后, 你将了解有关lda2vec背后的一般思想的更多信息。
潜在狄利克雷分配:简介
主题模型采用未标记文档的集合, 并尝试在该集合中查找结构或主题。请注意, 主题模型通常假设单词的使用与主题的出现相关。例如, 你可以为主题模型提供一组新闻文章, 并且该主题模型将根据单词的使用情况将文档分为多个簇。
主题模型是自动浏览和构建大量文档的一种好方法:它们根据文档中出现的单词对文档进行分组或聚类。由于有关相似主题的文档倾向于使用相似的子词汇, 因此, 文档的结果簇可以解释为讨论不同的”主题”。
潜在狄利克雷分配(LDA)是概率主题模型的一个示例。这的确切含义是, 你将在以下各节中学习:首先, 你将了解LDA如何从一个词袋描述开始, 以表示不同的文档。然后, 你将看到如何使用这些表示形式在文档集合中查找结构。
词袋
传统上, 文本文档在NLP中表示为单词袋。
这意味着每个文档都表示为固定长度的矢量, 其长度等于词汇量。此向量的每个维度对应于文档中单词的计数或出现。能够将可变长度的文档缩减为固定长度的矢量, 使其更适合与多种机器学习(ML)模型和任务(聚类, 分类等)一起使用。
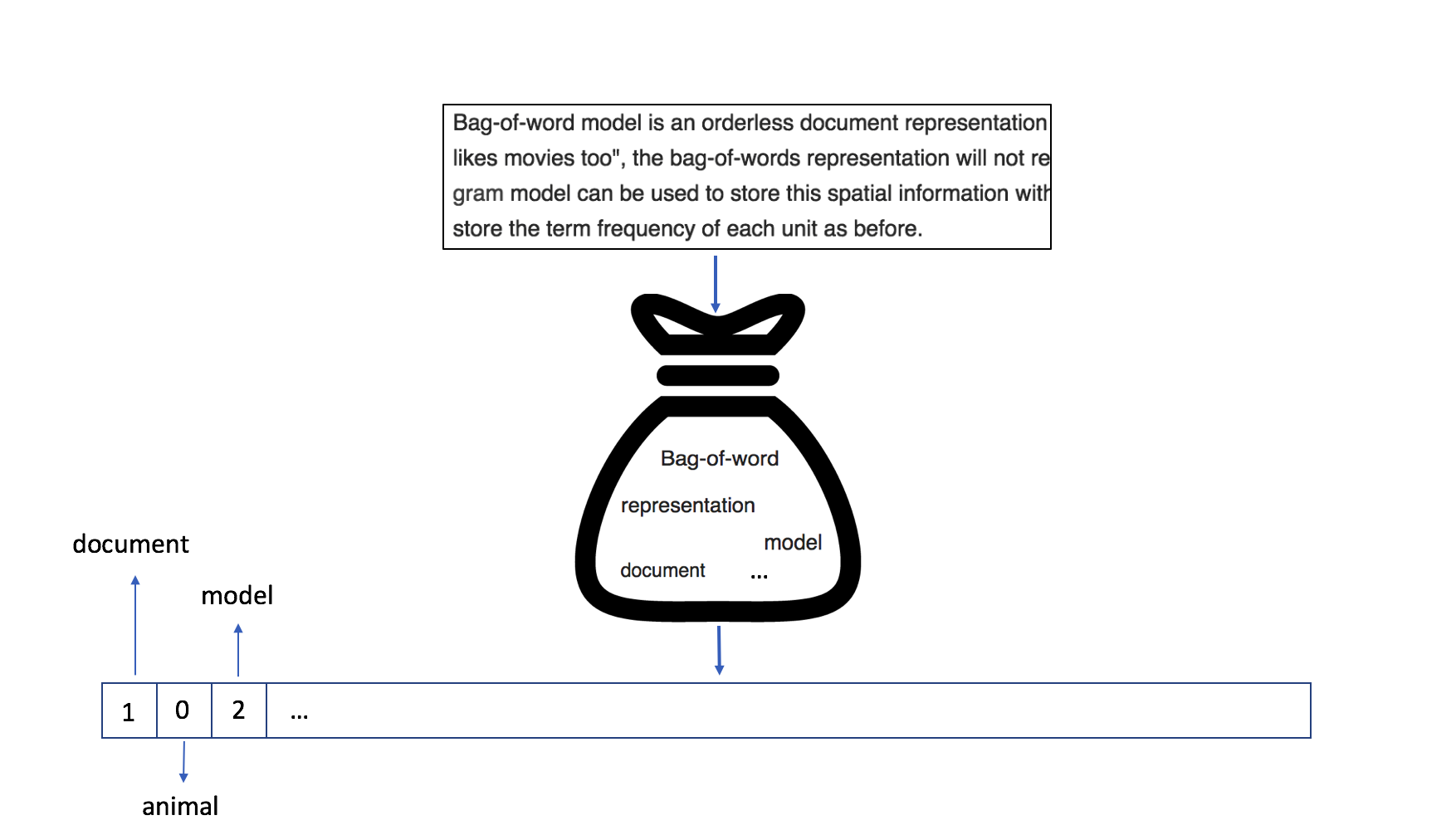
上图显示了如何在词袋模型中表示文档:单词” document”的计数为1, 而单词” model”在文本中出现两次。
尽管词袋会导致稀疏和高维文档表示, 但是如果有大量数据可用, 则通常会在主题分类上获得良好的结果。你随时可以阅读有关主题分类的最新Facebook论文。
定长文档表示意味着你可以轻松地将不同长度的文档输入ML模型(SVM, k-NN, Random Forests等)。这使你可以对文档执行聚类或主题分类。删除了文档的结构信息, 并且模型必须发现哪些向量维在语义上相似。例如, 在不同维度上映射”猫科动物”和”猫”较不直观, 因为模型被迫学习这些不同维度之间的相关性。
LDA模型
训练LDA模型时, 首先要收集文档, 并且每个文档都由固定长度的矢量(单词袋)表示。 LDA是一种通用的机器学习(ML)技术, 这意味着它也可以用于其他无监督的ML问题, 其中输入是固定长度向量的集合, 目标是探索此数据的结构。
要实现LDA模型, 首先要定义文档集中存在的”主题”数量。这听起来很简单, 但通常不如处理大量文档时直观。
在具有$$ M $$主题的$$ N $$文档上训练LDA模型与找到最能解释数据的文档和主题向量相对应。
请注意, 本教程将不会详细介绍LDA背后的全部理论(有关详细信息, 请参阅Blei等人的本文), 因为重点是更广泛地理解一般概念。
假设文档中的词汇表由$$ V $$个单词组成。

每个$ N $$文档将在LDA模型中由长度为$ M $$的向量表示, 该向量详细说明了该文档中出现的主题。一个文档可以包括75%为”主题1″和25%为”主题2″。 LDA通常会导致文档向量带有很多零, 这意味着每个文档只出现有限数量的主题。这与文档通常只谈论有限数量的主题这一想法相对应。这显着改善了这些文档载体的人类可解释性。
每个$$ M $$主题均由长度为$$ V $$的向量表示, 该向量详细说明了可能出现的单词(给定有关该主题的文档)。因此, 对于主题1, “学习”, “建模”和”统计”可能是一些最常用的词。这意味着你可以然后说这是”数据科学”主题。对于主题2, 单词” GPU”, “计算”和”存储”可能是最常见的单词。你可以将其解释为”计算”主题。
下图直观地说明了LDA模型。该模型的目的是找到解释不同文档的原始词袋表示形式的主题和文档向量。

重要的是要注意, 你所依赖的假设是主题向量将是可解释的, 否则该模型的输出将非常垃圾。本质上, 你假设该模型在获得足够数据的情况下将找出哪些词倾向于同时出现, 并将它们聚类为不同的”主题”。
LDA是一个简单的概率模型, 通常效果很好。文档向量通常是稀疏的, 低维的和高度可解释的, 突出了文档中的模式和结构。你必须确定文档集合中出现的主题数的良好估计。此外, 你还必须为不同的主题向量手动分配一个单独的提名人/”主题”。由于使用词袋模型来表示文档, 因此LDA可能遭受与词袋模型相同的缺点。 LDA模型学习一个文档向量, 该向量预测该文档内部的单词, 而忽略任何结构或这些单词在本地级别上如何相互作用。
词嵌入
词袋表示法的问题之一是模型负责弄清楚文档向量中哪些维在语义上相关。可能有人会想到, 利用有关单词在语义上如何相互关联的信息, 可以提高模型的性能, 而这正是单词嵌入所带来的希望。
对于单词嵌入, 单词表示为固定长度的矢量或嵌入。存在几种不同的模型来构造嵌入, 但是它们都基于分布假设。这意味着”一个单词的特征在于它所拥有的公司”。
词嵌入的目的是从诸如Wikipedia这样的大型无监督文档集中捕获语言的语义和句法规律性。在相同上下文中出现的单词由彼此紧邻的向量表示。

图片来自”使用t-SNE可视化单词嵌入”
上图是使用t分布随机邻居嵌入(t-SNE)将单词嵌入空间投影到2D空间的图。 t-SNE是一种降维方法, 可用于可视化高维数据。该方法将单词嵌入作为输入, 并将其投影到二维空间中, 该空间可以在图形中轻松查看。仅调查单词空间的一个小节, 重点放在接近”老师”的单词上。代替使用向量中无意义的维表示词, 可以使用词嵌入通过语义相关向量来表示词。
使用单词嵌入时, ML模型可以将大量文档(也称为”语料库”)中的信息嵌入矢量表示形式中, 以利用这些信息。词袋模型无法做到这一点, 当没有大量数据可用时会损害模型性能。单词嵌入导致文档表示形式不再是固定长度的。取而代之的是, 文档由单词矢量嵌入的可变长度序列表示。虽然某些深度学习技术(例如长短期记忆(LSTM), 具有自适应池的卷积网络)能够处理可变长度序列, 但通常需要大量数据来正确训练它们。
word2vec
正如你在简介中所读到的那样, word2vec是由Mikolov等人开发的非常流行的单词嵌入模型。请注意, 分布语义领域内还存在其他几种单词嵌入模型。尽管获得高质量的单词嵌入需要一些技巧, 但是本教程将仅关注word2vec背后的核心思想。
在word2vec中使用以下训练过程来获取单词嵌入。
在文本中选择一个(枢轴)词。当前枢纽词的上下文词是在枢纽词周围出现的词。这意味着你正在固定长度的单词窗口内工作。中心词和上下文词的组合构成了一组单词-上下文对。下图来自Chris Moody在lda2vec上的博客。在此文本片段中, ” awesome”是关键词, 其周围的词被用作上下文词, 从而形成7个单词-上下文对。

图片取自”介绍我们的混合lda2vec算法”
存在word2vec模型的两个变体:在词袋架构(CBOW)中, 枢轴词是根据一组周围的上下文词来预测的(即, 给定的”谢谢”, “这样”, “你”, “顶部”, 模型必须预测”真棒” )。由于上下文词的顺序无关紧要, 因此将其称为”词袋结构”。 b。在skip-gram架构中, 枢轴词用于预测周围的上下文词(即给定’awesome’预测’thank’, ‘such’, ‘you’, ‘top’)。下图描述了两种不同的word2vec体系结构。请注意, 使用了相对简单的(两层)神经模型(与计算机视觉中的深层神经模型相比)。

图片取自”向量空间中单词表示的有效估计”(Mikolov等, 2013)
通过在大型语料库上训练模型, 你将获得单词嵌入(投影层中的权重), 这些单词嵌入对语义信息以及一些有趣的属性进行编码:可以执行矢量算术, 例如$$ king-man + woman =皇后$$。
与例如简单的单热编码表示相比, 字向量是有用的表示。它们允许将来自大型语料库的统计信息编码到其他模型中, 例如主题分类或对话系统。单词向量通常是密集的, 高维的并且无法解释。考虑以下示例:[-0.65, -1.223, …, -0.252, +3.2]。尽管在LDA中维度大致与主题相对应, 但单词向量通常不是这种情况。每个单词都分配有上下文无关的单词向量。但是, 单词的语义高度依赖于上下文。 word2vec模型学习一个单词矢量, 该单词矢量可以预测不同文档中的上下文单词。结果, 文档特定信息在单词嵌入中混合在一起。
lda2vec
受潜在狄利克雷分配(LDA)的启发, word2vec模型被扩展为可同时学习单词, 文档和主题向量。
Lda2vec是通过修改skip-gram word2vec变体获得的。在原始的跳过语法方法中, 训练模型以基于枢轴词预测上下文词。在lda2vec中, 将枢轴词向量和文档向量相加以获得上下文向量。然后将该上下文向量用于预测上下文词。
在下一节中, 你将看到如何构造这些文档向量以及如何将它们与LDA中的文档向量类似地使用。
lda2vec架构
在word2vec模型中集成上下文向量的想法并不是一个新想法。例如, 段落向量也探索了这个想法, 以学习变长文本片段的定长表示。在他们的工作中, 对于每个文本片段(段落大小), 都学习了密集的矢量表示, 类似于学习的单词矢量。
这种方法的缺点是上下文/段落向量类似于典型的词向量, 从而使其难以解释为LDA的输出。
lda2vec模型通过处理文档大小的文本片段并将文档向量分解为两个不同的组件, 比段落向量方法迈出了一步。按照与LDA模型相同的精神, 将文档向量分解为文档权重向量和主题矩阵。文档权重向量代表不同主题的百分比, 而主题矩阵由不同主题向量组成。因此, 通过组合文档中出现的不同主题向量来构建上下文向量。
请考虑以下示例:在原始的word2vec模型中, 如果关键词是”法语”, 则可能的上下文词可能是”德语”, “荷兰语”, “英语”。如果没有任何全局(与文档相关的)信息, 这些将是最合理的猜测。
通过在lda2vec模型中提供一个附加的上下文向量, 可以更好地猜测上下文词。
如果文档向量是”食物”和”饮料”主题的组合, 则”法式长棍面包”, “奶酪”和”酒”可能更合适。如果文档向量类似于”城市”和”地理”主题, 则”巴黎”, “里昂”和”格勒诺布尔”可能更合适。
请注意, 这些主题向量是在词空间中学习的, 这便于解释:你只需查看最接近主题向量的词向量即可。另外, 对文档权重向量施加约束, 以获得稀疏向量(类似于LDA), 而不是密集向量。这样可以轻松解释不同文档的主题内容。
简而言之, lda2vec的最终结果是一组稀疏文档权重向量以及易于解释的主题向量。
尽管性能趋于类似于传统的LDA, 但是使用自动微分方法使该方法可扩展到非常大的数据集。此外, 通过组合上下文向量和词向量, 你可以获得”专用”词向量, 该词向量可在其他模型中使用(并且可能会胜过更多”通用”词向量)。
lda2vec库
Lda2vec是一种相当新的专业NLP技术。由于它基于现有方法, 因此任何word2vec实现都可以扩展到lda2vec中。克里斯·穆迪(Chris Moody)在Chainer中实现了该方法, 但是也可以使用其他自动区分框架(CNTK, Theano等)。 Tensorflow实现也已公开提供。
可以在此处找到lda2vec Python模块的概述。由于训练lda2vec可能需要大量计算, 因此建议为较大的语料库提供GPU支持。此外, 为了加快训练速度, 通常使用预训练的word2vec向量来初始化不同的词向量。
最后, 将lda2vec作为主题模型进行了讨论, 但是将上下文向量添加到word2vec模型的想法也可以更一般地定义。例如, 考虑来自不同地区的不同作者撰写的文档。然后, 作者和区域向量也可以添加到上下文向量中, 从而形成一种无监督的方法来获取文档, 区域和作者向量表示。
总结
这篇博文仅提供了LDA, word2vec和lda2vec的快速概述。请注意, 原始作者还发表了一篇有关lda2vec技术细节的精彩博客文章。
评论前必须登录!
注册