 srcmini
srcmini本文概述
当你使用dplyr, magrittr等软件包时, 你可能已经看过或使用过管道运算符。…但是你知道管道和著名的%>%运算符来自何处, 它们的确切含义或方式吗?什么时候以及为什么要使用它们?你还能提出一些替代方案吗?
本教程将向你介绍R中的管道, 并将涵盖以下主题:
- R中的管道算子:简介
- R中管道操作员的简要历史
- 它是什么?
- 为什么要使用它?
- 额外管道
- 如何在R中使用管道
- 基本管道
- 参数占位符
- 重新使用占位符作为属性
- 建立一元函数
- 复合分配管道操作
- 与Tee操作员进行Tee操作
- 使用Exposition运算符公开数据变量
- dplyr和magrittr
- RStudio键盘快捷键
- 何时不使用R中的管道运算符
- R中管道的替代方案
你是否有兴趣了解有关使用dplyr在R中处理数据的更多信息?看看dplyr课程中R中的srcmini的数据操作。
R中的管道算子:简介
要了解R中的管道算子是什么以及可以使用它做什么, 有必要考虑整个情况, 以了解其背后的历史。诸如”这种怪异的符号组合来自何处以及为什么这样制作?”这样的问题?可能在你的脑海中。你将在本节中找到这些问题的答案以及更多问题。
现在, 你可以从三个角度查看历史:从数学的角度, 从编程语言的整体角度以及从R语言本身的角度。你将在后面介绍所有这三个部分!
R中管道操作员的历史
数学史
如果你有两个函数, 比如说$ f:B→C $和$ g:A→B $, 则可以通过获取一个函数的输出并将其插入下一个函数来将这些函数链接在一起。简而言之, “链接”意味着你将中间结果传递给下一个函数, 但是稍后你将看到更多有关该结果的信息。
例如, 你可以说$ f(g(x))$:$ g(x)$充当$ f()$的输入, 而$ x $当然充当$ g()的输入$。
如果要记下来, 请使用符号$ f◦g $, 读作” f follow g”。或者, 你可以直观地表示为:
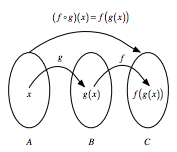
图片来源:James Balamuta, “管道数据”
其他编程语言的管道算子
如本节简介中所述, 此运算符在编程中并不陌生:在Shell或Terminal中, 你可以使用管道字符|将命令从一个传递到下一个。同样, F#具有前向管道运算符, 以后将被证明很重要!最后, 还很高兴知道Haskell包含许多从Shell或Terminal派生的管道操作。
R中的管道
既然你已经了解了其他编程语言中的管道运算符的一些历史, 那么现在该关注R了。根据AdolfoÁlvarez在2012年1月17日撰写的精彩博客文章, R中的该运算符的历史开始了。一位匿名用户在此Stack Overflow帖子中问了以下问题:
如何在R中实现F#的前向管道运算符?操作员可以轻松地链接一系列计算。例如, 当你有输入数据并想要依次调用函数foo和bar时, 可以写数据|> foo |> bar吗?
答案来自麦克马斯特大学教授本·博克(Ben Bolker), 他回答:
我不知道它能在多大程度上实际使用, 但这似乎(?)可以做你想要的事情, 至少对于单参数函数…”%>%” <-function(x, f )do.call(f, list(x))pi%>%sin [1] 1.224606e-16 pi%>%sin%>%cos [1] 1 cos(sin(pi))[1] 1
大约九个月后, Hadley Wickham在GitHub上启动了dplyr软件包。你现在可能已经知道RStudio的首席科学家Hadley, 他是许多流行的R包(例如最后一个包!)的作者, 并且是srcmini在R课程中的写作函数的讲师。
但是, 直到2013年, 第一个管道%。%才出现在此包装中。正如AdolfoÁlvarez在他的博客文章中正确提到的那样, 该函数被命名为chain(), 其目的是简化将多个函数应用于R中的单个数据帧的表示法。
正如Stefan Bache于2013年12月29日提出的替代方案一样, %。%管道的存在时间不长, 你现在可能已经知道它包括:
iris %>%
subset(Sepal.Length > 5) %>%
aggregate(. ~ Species, ., mean)
Bache继续从事此管道运营工作, 并于2013年底形成了magrittr包装。同时, Hadley Wickham继续从事dplyr的工作, 并在2014年4月将%。%运算符替换为你现在所知道的%>%。
那年晚些时候, Kun Ren在GitHub上发布了pipeR程序包, 该程序包包含了另一个管道运算符%>>%, 旨在为管道过程增加更多的灵活性。但是, 可以肯定地说, %>%现在是用R语言建立的, 尤其是随着Tidyverse的最近流行。
它是什么?
知道历史是一回事, 但这仍然不能使你了解F#的正向管道运算符是什么, 或者它实际上在R中的作用。
在F#中, 管道前导运算符|>是用于链式方法调用的语法糖。或者, 更简单地说, 它使你可以将中间结果传递给下一个函数。
请记住, “链接”意味着你调用多个方法调用。当每个方法返回一个对象时, 实际上可以允许将调用链接到一个语句中, 而无需使用变量来存储中间结果。
如你所见, 在R中, 管道运算符为%>%。如果你不熟悉F#, 则可以认为此运算符类似于ggplot2语句中的+。它的功能与你在F#运算符中看到的功能非常相似:它获取一条语句的输出, 并使其成为下一条语句的输入。描述它时, 你可以将其视为” THEN”。
以下面的代码块为例, 然后大声阅读:
iris %>%
subset(Sepal.Length > 5) %>%
aggregate(. ~ Species, ., mean)
没错, 上面的代码块将转换为”你获取Iris数据, 然后对数据进行子集然后汇总数据”之类的内容。
这是Tidyverse最强大的功能之一。实际上, 具有标准化的处理动作链称为”管道”。为数据格式创建管道非常好, 因为你可以将该管道应用于具有相同格式的传入数据, 并以ggplot2友好格式进行输出。
为什么要使用它?
R是一种功能语言, 这意味着你的代码通常包含很多括号(和)。当你使用复杂的代码时, 这通常意味着你必须将这些括号嵌套在一起。这使你的R代码难以阅读和理解。这是%>%的救援对象!
看下面的示例, 它是嵌套代码的典型示例:
# Initialize `x`
x <- c(0.109, 0.359, 0.63, 0.996, 0.515, 0.142, 0.017, 0.829, 0.907)
# Compute the logarithm of `x`, return suitably lagged and iterated differences, # compute the exponential function and round the result
round(exp(diff(log(x))), 1)
- 3.3
- 1.8
- 1.6
- 0.5
- 0.3
- 0.1
- 48.8
- 1.1
在%<%的帮助下, 你可以按以下方式重写上面的代码:
# Import `magrittr`
library(magrittr)
# Perform the same computations on `x` as above
x %>% log() %>%
diff() %>%
exp() %>%
round(1)
你觉得这很难吗?别担心!你将在本教程的后面部分详细了解如何进行此操作。
请注意, 你需要导入magrittr库以使上面的代码起作用。如前所述, 这是因为管道运算符是magrittr库的一部分, 并且自2014年以来也是dplyr的一部分。如果你忘记导入该库, 则会收到类似eval(expr, envir, enclos)中的错误的错误:找不到函数”%>%”。
还要注意, 在log, diff和exp之后添加括号不是正式的要求, 但是在R社区中, 有些人会使用它来提高代码的可读性。
简而言之, 这是在R中使用管道的四个原因:
- 你将按照从内到外的顺序从左到右构造数据操作的顺序。
- 你将避免嵌套函数调用;
- 你将使对局部变量和函数定义的需求降到最低。和
- 你可以轻松地在操作序列中的任何位置添加步骤。
这些原因来自magrittr文档本身。隐式地, 你看到了可读性和灵活性返回的论点。
额外管道
即使%>%是magrittr程序包的(主要)管道运算符, 你也应该知道其他几个运算符, 它们是同一程序包的一部分:
- 复合赋值运算符%<>%;
# Initialize `x`
x <- rnorm(100)
# Update value of `x` and assign it to `x`
x %<>% abs %>% sort
- T型运算符%T>%;
rnorm(200) %>%
matrix(ncol = 2) %T>%
plot %>%
colSums
请注意, 现在很高兴知道上面的代码块实际上是以下代码的快捷方式:
rnorm(200) %>%
matrix(ncol = 2) %T>%
{ plot(.); . } %>%
colSums
但是稍后你会看到更多关于此的信息!
- 博览会管道运营商%$%。
data.frame(z = rnorm(100)) %$%
ts.plot(z)
当然, 这三个运算符的工作方式与主要%>%运算符略有不同。在本教程后面的部分中, 你将看到有关它们的功能和用法的更多信息!
请注意, 即使你最常看到magrittr管道, 但在进行过程中可能还会遇到其他管道!包装器的点箭头管道%。>%或点管道%>。%或Bizarro管道->。;。
如何在R中使用管道
既然你已经知道%>%运算符的起源, 它的真正含义以及使用它的原因, 那么现在该是你发现如何实际使用它以发挥自己的优势的时候了。你会发现有很多使用方式!
基本管道
在深入探讨运算符的高级用法之前, 最好先看看使用运算符的最基本的示例。从本质上讲, 你会发现在开始时可以遵循3条规则:
- f(x)可以重写为x%>%f
简而言之, 这意味着采用一个参数function(argument)的函数可以按以下方式重写:参数%>%function()。请看以下更实际的示例, 以了解这两者是如何等效的:
# Compute the logarithm of `x`
log(x)
# Compute the logarithm of `x`
x %>% log()
- f(x, y)可以重写为x%>%f(y)
当然, 有很多函数不只是接受一个参数, 而是多个参数。情况就是这样:你会看到该函数接受两个参数x和y。与在第一个示例中看到的类似, 可以通过遵循结构arguments1%>%function(argument2)重写函数, 其中arguments1是magrittr占位符, argument2是函数调用。
这一切似乎都是理论上的。让我们看一个更实际的例子:
# Round pi
round(pi, 6)
# Round pi
pi %>% round(6)
- x%>%f%>%g%>%h可以重写为h(g(f(x)))
这可能看起来很复杂, 但是当你看一个真实的R示例时, 它并不是完全一样:
# Import `babynames` data
library(babynames)
# Import `dplyr` library
library(dplyr)
# Load the data
data(babynames)
# Count how many young boys with the name "Taylor" are born
sum(select(filter(babynames, sex=="M", name=="Taylor"), n))
# Do the same but now with `%>%`
babynames%>%filter(sex=="M", name=="Taylor")%>%
select(n)%>%
sum
请注意重写嵌套代码时从内到外的工作方式:首先输入婴儿名称, 然后使用%>%首先对数据进行filter()。之后, 你将选择n, 最后将sum()一切。
还请记住, 你已经在本教程的开头看到了这样的嵌套代码的另一个示例, 该示例已转换为更易读的代码, 其中你使用log(), diff(), exp()和round()函数执行计算。在x上
使用当前环境的功能
不幸的是, 上一节中概述的更一般的规则也有一些例外。让我们在这里看看其中的一些。
考虑这个示例, 在这里你使用assign()函数将值10分配给变量x。
# Assign `10` to `x`
assign("x", 10)
# Assign `100` to `x`
"x" %>% assign(100)
# Return `x`
x
10
你会看到, 第二个通过assign()函数与管道结合使用的调用无法正常工作。 x的值不更新。
为什么是这样?
这是因为该函数将新值100分配给%>%使用的临时环境。因此, 如果要对管道使用assign(), 则必须明确说明环境:
# Define your environment
env <- environment()
# Add the environment to `assign()`
"x" %>% assign(100, envir = env)
# Return `x`
x
100
具有惰性求值的功能
仅当函数在R中使用函数时, 才会计算函数中的参数。这意味着在调用函数之前不会计算任何参数!这也意味着管道依次计算函数的每个元素。
问题所在的一个地方是tryCatch(), 它使你可以捕获和处理错误, 如本例所示:
tryCatch(stop("!"), error = function(e) "An error")
stop("!") %>%
tryCatch(error = function(e) "An error")
‘一个错误’
Error in eval(expr, envir, enclos): !
Traceback:
1. stop("!") %>% tryCatch(error = function(e) "An error")
2. eval(lhs, parent, parent)
3. eval(expr, envir, enclos)
4. stop("!")
你会看到, 写下这一行代码的嵌套方式可以完美地工作, 而管道替代方法会返回错误。具有相同行为的其他函数是基本R中的try(), pressiveMessages()和preventWarnings()。
参数占位符
在某些情况下, 你可以将管道运算符用作参数占位符。看下面的例子:
- f(x, y)可以重写为y%>%f(x, 。)
在某些情况下, 你不希望将值或magrittr占位符放在第一个位置的函数调用上, 直到现在为止, 在每个示例中都是如此。重新考虑以下代码行:
pi %>% round(6)
如果你要重写此行代码, pi将是round()函数中的第一个参数。但是, 如果你想替换第二, 第三, …参数并将其用作函数调用的magrittr占位符, 该怎么办?
看一下这个示例, 其中的值实际上位于函数调用的第三个位置:
"Ceci n'est pas une pipe" %>% gsub("une", "un", .)
“这不是烟斗”
- f(y, z = x)可以重写为x%>%f(y, z =。)
同样, 你可能希望在函数中将特定参数的值称为magrittr占位符。考虑以下代码行:
6 %>% round(pi, digits=.)
重新使用占位符作为属性
直接在右侧表达式中多次使用占位符很简单。但是, 当占位符仅出现在嵌套表达式中时, magrittr仍将应用第一参数规则。原因是在大多数情况下, 这会产生更干净的代码。
以下是在嵌套函数调用中使用参数占位符时可以考虑的一些常规”规则”:
- f(x, y = nrow(x), z = ncol(x))可以重写为x%>%f(y = nrow(。), z = ncol(。))
# Initialize a matrix `ma`
ma <- matrix(1:12, 3, 4)
# Return the maximum of the values inputted
max(ma, nrow(ma), ncol(ma))
# Return the maximum of the values inputted
ma %>% max(nrow(ma), ncol(ma))
12
12
可以通过将右手括在右括号中来否决此行为:
- f(y = nrow(x), z = ncol(x))可以重写为x%>%{f(y = nrow(。), z = ncol(。))}
# Only return the maximum of the `nrow(ma)` and `ncol(ma)` input values
ma %>% {max(nrow(ma), ncol(ma))}
4
最后, 请看下面的示例, 在该示例中, 你可能想调整嵌套函数调用中参数占位符的工作方式:
# The function that you want to rewrite
paste(1:5, letters[1:5])
# The nested function call with dot placeholder
1:5 %>%
paste(., letters[.])
- ‘1个’
- ‘2 b’
- ‘3 c’
- ‘4天’
- ‘5是’
- ‘1个’
- ‘2 b’
- ‘3 c’
- ‘4天’
- ‘5是’
你会看到, 如果仅在嵌套函数调用中使用占位符, 则magrittr占位符也将被放置为第一个参数!如果要避免这种情况的发生, 可以使用大括号{和}:
# The nested function call with dot placeholder and curly brackets
1:5 %>% {
paste(letters[.])
}
# Rewrite the above function call
paste(letters[1:5])
- ‘一个’
- ‘b’
- ‘C’
- ‘d’
- “与”
- ‘一个’
- ‘b’
- ‘C’
- ‘d’
- “与”
建立一元函数
一元函数是采用一个参数的函数。如果要将其应用到值, 则可以使用由点。, 后跟函数组成并且与%>%链接在一起的任何管道。请看以下有关此类管道的示例:
. %>% cos %>% sin
该管道将需要一些输入, 然后将cos()和sin()功能都应用到它。
但是你还没有!如果你希望该管道完全完成你刚刚阅读的内容, 则需要首先将其分配给变量f。之后, 你可以稍后重新使用它来对其他值执行管道中包含的操作。
# Unary function
f <- . %>% cos %>% sin
f
structure(function (value)
freduce(value, `_function_list`), class = c("fseq", "function"
))还要记住, 如果想提高可读性, 可以在代码行中的cos()和sin()函数后加上括号。考虑带括号的相同示例:。 %>%cos()%>%sin()。
你会看到, 在magrittr中构建函数与使用基数R构建函数非常相似!如果不确定它们的实际相似程度, 请查看上面的行并将其与下一行代码进行比较;这两行结果相同!
# is equivalent to
f <- function(.) sin(cos(.))
f
function (.)
sin(cos(.))复合分配管道操作
在某些情况下, 你想要覆盖左侧的值, 就像下面的示例中一样。直观地, 你将使用赋值运算符<-来执行此操作。
# Load in the Iris data
iris <- read.csv(url("http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"), header = FALSE)
# Add column names to the Iris data
names(iris) <- c("Sepal.Length", "Sepal.Width", "Petal.Length", "Petal.Width", "Species")
# Compute the square root of `iris$Sepal.Length` and assign it to the variable
iris$Sepal.Length <-
iris$Sepal.Length %>%
sqrt()
但是, 有一个复合分配管道运算符, 它允许你使用简写表示法将管道的结果立即分配给左侧:
# Compute the square root of `iris$Sepal.Length` and assign it to the variable
iris$Sepal.Length %<>% sqrt
# Return `Sepal.Length`
iris$Sepal.Length
请注意, 复合赋值运算符%<>%必须是链中的第一个管道运算符, 此函数才能起作用。这与你刚刚读到的有关运算符是重复的较长记号的简写表示法完全一致, 在此处你使用常规<-赋值运算符。
结果, 此运算符将分配管道的结果, 而不是返回它。
使用Tee运算符进行Tee操作
Tee运算符的工作方式与%>%完全相同, 但是它返回的是左侧值, 而不是右侧操作的潜在结果。
这意味着, 在包含一些副作用函数的情况下, 例如使用plot()进行绘图或打印到文件中, tee操作员可以派上用场。
换句话说, 诸如plot()之类的函数通常不返回任何内容。这意味着, 例如, 在调用plot()之后, 你的管道将结束。但是, 在以下示例中, 即使使用了plot(), Tee运算符%T>%也允许你继续执行管道:
set.seed(123)
rnorm(200) %>%
matrix(ncol = 2) %T>%
plot %>%
colSums

使用Exposition运算符公开数据变量
使用R时, 你会发现许多函数都带有一个数据参数。例如, 考虑lm()函数或with()函数。这些函数在先处理数据然后传递到函数的管道中很有用。
对于没有数据参数的函数(例如cor()函数), 如果可以在数据中公开变量, 则仍然很方便。这就是%$%运算符出现的地方。请考虑以下示例:
iris %>%
subset(Sepal.Length > mean(Sepal.Length)) %$%
cor(Sepal.Length, Sepal.Width)
0.336696922252551
在%$%的帮助下, 确保Sepal.Length和Sepal.Width暴露于cor()。同样, 你会看到data.frame()函数中的数据已传递到ts.plot(), 以在公共图上绘制几个时间序列:
data.frame(z = rnorm(100)) %$%
ts.plot(z)

dplyr和magrittr
在本教程的简介中, 你已经了解到dplyr和magrittr的开发大约在同一时间发生, 即在2013-2014年左右。而且, 如你所读, magrittr软件包也是Tidyverse的一部分。
在本节中, 你将发现在R代码中结合使用这两个包时会感到多么兴奋。
对于那些不熟悉dplyr软件包的人, 你应该知道此R软件包是围绕五个动词构建的, 即” select”, ” filter”, ” arrange”, ” mutate”和” summaryize”。如果你已经为某个数据科学项目处理过数据, 则将知道这些动词构成了通常需要对数据执行的大部分数据处理任务。
以使用这些dplyr函数的一些传统代码为例:
library(hflights)
grouped_flights <- group_by(hflights, Year, Month, DayofMonth)
flights_data <- select(grouped_flights, Year:DayofMonth, ArrDelay, DepDelay)
summarized_flights <- summarise(flights_data, arr = mean(ArrDelay, na.rm = TRUE), dep = mean(DepDelay, na.rm = TRUE))
final_result <- filter(summarized_flights, arr > 30 | dep > 30)
final_result
| 年 | 月 | 每月的一天 | rr | 深度 |
|---|---|---|---|---|
| 2011 | 2 | 4 | 44.08088 | 47.17216 |
| 2011 | 3 | 3 | 35.12898 | 38.20064 |
| 2011 | 3 | 14 | 46.63830 | 36.13657 |
| 2011 | 4 | 4 | 38.71651 | 27.94915 |
| 2011 | 4 | 25 | 37.79845 | 22.25574 |
| 2011 | 5 | 12 | 69.52046 | 64.52039 |
| 2011 | 5 | 20 | 37.02857 | 26.55090 |
| 2011 | 6 | 22 | 65.51852 | 62.30979 |
| 2011 | 7 | 29 | 29.55755 | 31.86944 |
| 2011 | 9 | 29 | 39.19649 | 32.49528 |
| 2011 | 10 | 9 | 61.90172 | 59.52586 |
| 2011 | 11 | 15 | 43.68134 | 39.23333 |
| 2011 | 12 | 29 | 26.30096 | 30.78855 |
| 2011 | 12 | 31 | 46.48465 | 54.17137 |
当你查看此示例时, 你会立即理解dplyr和magrittr为什么能够如此出色地协同工作:
hflights %>%
group_by(Year, Month, DayofMonth) %>%
select(Year:DayofMonth, ArrDelay, DepDelay) %>%
summarise(arr = mean(ArrDelay, na.rm = TRUE), dep = mean(DepDelay, na.rm = TRUE)) %>%
filter(arr > 30 | dep > 30)
两个代码块都相当长, 但是如果你想继续执行所有操作, 则可以辩称第二个代码块更清晰。通过在第一个代码块中创建中间变量, 你可能会丢失代码的”流”。通过使用%>%, 你可以更清楚地了解对数据执行的操作!
简而言之, dplyr和magrittr是你在R中操作数据的理想之选!
RStudio管道的键盘快捷键
将所有这些管道添加到你的R代码中可能是一项艰巨的任务!为了使你的生活更轻松, Win-Vector, LLC和srcmini讲师的共同创始人兼首席顾问John Mount发布了一个带有RStudio插件的软件包, 允许你在R中为管道创建键盘快捷方式。插件实际上是R函数具有一些特殊的注册元数据。例如, 简单插件的示例可以是插入常用文本片段的函数, 但也可能变得非常复杂!
使用这些插件, 你可以使用键盘快捷键或通过”插件”菜单在RStudio IDE中以交互方式执行R函数。
请注意, 该程序包实际上是RStudio原始外接程序包的分支, 你可以在此处找到。但是请注意, 仅在最新版本的RStudio中才提供对插件的支持!如果你想进一步了解如何安装这些RStudio插件, 请查看此页面。
你可以在此处下载加载项和键盘快捷键。
何时不使用R中的管道运算符
在上面, 你已经看到在使用R进行编程时绝对应该使用管道。更具体地说, 通过介绍一些管道被证明非常有用的情况, 你已经看到了管道!但是, Hadley Wickham在”数据科学R”中概述了某些情况, 在这种情况下, 你最好避免它们:
- 你的管道超过(例如)十个步骤。
在这种情况下, 最好使用有意义的名称创建中间对象。这不仅可以使你调试代码更加容易, 而且还可以更好地理解你的代码, 而其他人也可以更轻松地理解你的代码。
- 你有多个输入或输出。
如果不是要变换一个主要对象, 而是将两个或更多对象组合在一起, 则最好不要使用管道。
- 你开始考虑具有复杂依赖关系结构的有向图。
管道从根本上讲是线性的, 与管道表达复杂的关系只会导致难以阅读和理解的复杂代码。
- 你正在进行内部包装开发
在内部软件包开发中使用管道是不行的, 因为它使调试变得更加困难!
有关此主题的更多思考, 请查看此Stack Overflow讨论。该讨论中出现的其他情况是循环, 程序包依赖性, 参数顺序和可读性。
简而言之, 你可以将其总结如下:牢记使该结构如此出色的两件事, 即可读性和灵活性。一旦这两个主要优点之一遭到损害, 你可能会考虑一些替代方法来支持管道。
R中管道的替代方案
毕竟, 你可能还对R编程语言中存在的某些替代方法感兴趣。你在本教程中看到的一些解决方案如下:
- 用有意义的名称创建中间变量;
不要将所有操作链接在一起并输出一个结果, 而要断开链并确保将中间结果保存在单独的变量中。注意这些变量的命名:目标应该始终是使你的代码尽可能地易于理解!
- 嵌套你的代码, 以便你从内而外阅读它;
你可能对管道提出的反对意见之一是, 它与你习惯于使用基数R的”流”相违背。解决方案是坚持嵌套你的代码!但是, 如果你不喜欢管道, 但又认为嵌套可能会造成混乱, 那该怎么办?解决方案可以是使用选项卡突出显示层次结构。
- …你还有其他建议吗?确保让我知道-给我发一条推文@willems_karlijn
总结
在本教程中, 你已经学到了很多基础知识:已经了解了%>%的来源, 确切含义, 为什么要使用它以及如何使用它。你已经看到dplyr和magrittr软件包可以很好地协同工作, 并且那里还有更多的运算符!最后, 你还看到了一些在R中编程时不应该使用它的情况, 以及在这种情况下可以使用的替代方法。
如果你想了解有关Tidyverse的更多信息, 请考虑srcmini的Tidyverse课程简介。
评论前必须登录!
注册