 srcmini
srcmini本文概要
数据预处理是准备原始数据并使其适合于机器学习模型的过程。这是创建机器学习模型的第一步,也是至关重要的一步。
在创建一个机器学习项目时,我们并不总是遇到干净和格式化的数据。在对数据进行任何操作时,都必须对其进行清理并以格式化的方式放置。因此,我们使用数据预处理任务。
我们为什么需要数据预处理?
真实世界的数据通常包含噪音、缺失的值,而且格式可能无法直接用于机器学习模型。数据预处理是清洗数据并使其适合于机器学习模型的必要任务,这也提高了机器学习模型的准确性和效率。
它包括以下步骤:
- 获取数据集
- 导入库
- 导入数据集
- 查找缺失数据
- 编码分类数据
- 拆分数据集为训练和测试集
- 特征缩放
1)获取数据集
要创建一个机器学习模型,我们首先需要的是一个数据集,因为机器学习模型完全是基于数据的。以适当的格式为特定问题收集的数据称为数据集。
数据集可能有不同的格式,用于不同的目的,例如,如果我们想创建一个用于业务目的的机器学习模型,那么数据集将与肝脏病人所需的数据集不同。所以每个数据集都不同于另一个数据集。为了在代码中使用数据集,我们通常将其放入CSV文件中。然而,有时,我们可能还需要使用HTML或xlsx文件。
什么是一个CSV文件?
CSV代表“逗号分隔值”文件;它是一种文件格式,使我们能够保存表格数据,如电子表格。这是一个巨大的数据集有用,可以在程序中使用这些数据集。
在这里,我们将使用数据预处理演示数据集,并为实践,可以从这里,“https://www.superdatascience.com/pages/machine-learning下载。对于真实世界的问题,我们可以在网上下载的数据集从各种来源如https://www.kaggle.com/uciml/datasets,https://archive.ics.uci.edu/ml/index.php等
我们还可以通过使用Python的各种API收集数据并将数据放入.csv文件中来创建数据集。
2)导入库
为了使用Python执行数据预处理,我们需要导入一些预定义的Python库。这些库用于执行一些特定的任务。我们将使用三个特定的库进行数据预处理,它们是
Numpy: Numpy Python库用于在代码中包含任何类型的数学操作。它是Python中科学计算的基础包。它还支持添加大型、多维数组和矩阵。在Python中,我们可以将它导入为
import numpy as nm这里我们使用了nm,它是Numpy的一个短名称,将在整个程序中使用。
Matplotlib:第二个库是matplotlib,它是一个Python 2D绘图库,使用这个库,我们需要导入一个子库pyplot。这个库用于在Python中为代码绘制任何类型的图表。它将被导入如下
import matplotlib.pyplot as mpt在这里,我们已经使用MPT作为该库的简短名字。
Pandas:最后一个库是panda库,它是最著名的Python库之一,用于导入和管理数据集。它是一个开源的数据操作和分析库。它将被导入如下
在这里,我们使用PD作为该库的简短名字。考虑下面的图片:

3)导入数据集
现在我们需要导入我们为机器学习项目收集的数据集。但是在导入数据集之前,我们需要将当前目录设置为工作目录。要在Spyder IDE中设置工作目录,需要执行以下步骤
- 保存你的Python文件中包含的数据集的目录。
- 转到Spyder的IDE文件资源管理器选项,然后选择所需的目录。
- 点击F5键或运行选项执行该文件。
注:我们可以设置任意目录作为工作目录,但它必须包含所需的数据集。
在这里,下面的图片中,我们可以看到Python的文件与数据集需要一起。现在,在当前文件夹被设置为工作目录。
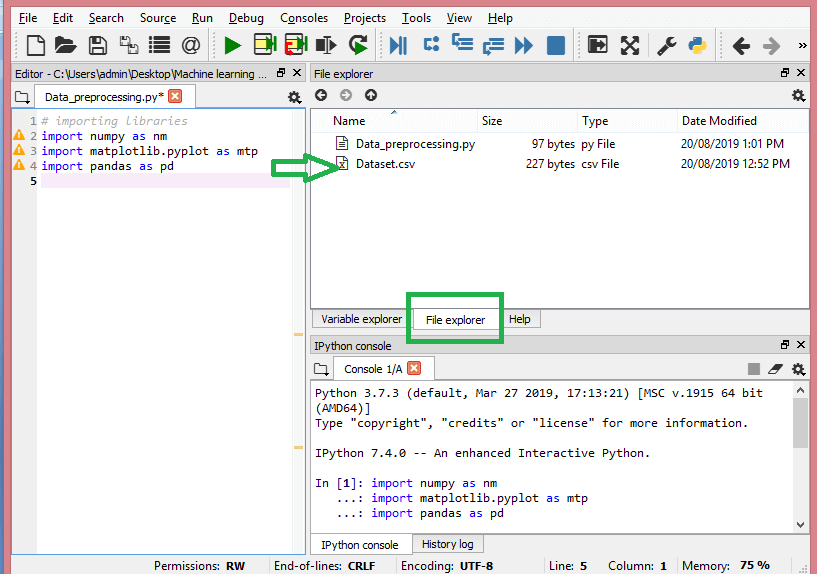
read_csv()函数:
现在导入的数据集,我们将使用read_csv(pandas库,它是用来读取csv文件,并执行各种操作的)函数。使用这个函数,我们可以在本地读取csv文件,也可以通过URL读取。
我们可以使用read_csv功能如下:
data_set= pd.read_csv('Dataset.csv')这里,data_set是存储数据集的变量的名称,在函数内部,我们传递了数据集的名称。一旦我们执行上述代码行,它将成功地导入我们代码中的数据集。我们还可以通过单击节变量资源管理器来检查导入的数据集,然后双击data_set。考虑下面的图像:
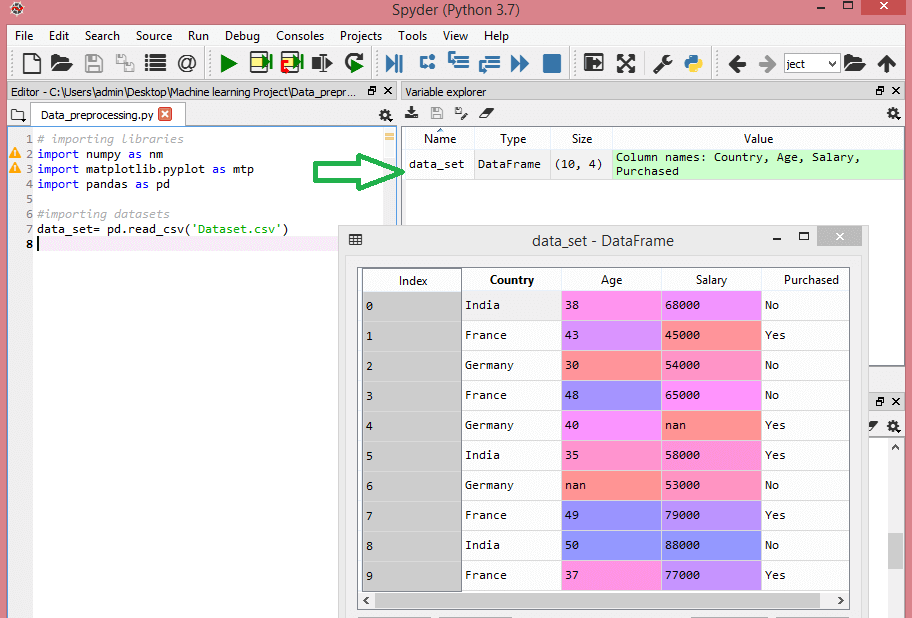
作为上述图像中,索引从0开始,它是在Python默认索引。我们还可以通过单击格式选项更改了数据集的格式。
提取因变量和自变量:
在机器学习中,将特征矩阵(自变量)和因变量与数据集区分开来是非常重要的。在我们的数据集中,有三个自变量,分别是国家、年龄和工资,一个是购买的因变量。
提取自变量:
为了提取一个自变量,我们将使用panda library的iloc[]方法。它用于从数据集中提取所需的行和列。
x= data_set.iloc[:,:-1].values在上面的代码中,第一个冒号(:)用于获取所有行,第二个冒号(:)用于获取所有列。这里我们用了-1,因为我们不想取最后一列因为它包含因变量。这样做,我们就得到了特征矩阵。
通过执行上面的代码,我们会得到输出:
[['India' 38.0 68000.0]
['France' 43.0 45000.0]
['Germany' 30.0 54000.0]
['France' 48.0 65000.0]
['Germany' 40.0 nan]
['India' 35.0 58000.0]
['Germany' nan 53000.0]
['France' 49.0 79000.0]
['India' 50.0 88000.0]
['France' 37.0 77000.0]]正如我们在上面的输出看,只有三个变量。
提取因变量:
为了提取因变量,我们将再次使用panda.iloc[]方法。
y= data_set.iloc[:,3].values这里我们只取最后一列的所有行。它会给出因变量的数组。
通过执行上面的代码,我们会得到输出:
输出:
array(['No','Yes','No','No','Yes','Yes','No','Yes','No','Yes'],dtype=object)注:如果你使用Python语言进行机器学习,那么提取是必需的,但对于R语言则不是必需的。
4)处理丢失数据
数据预处理的下一步是处理数据集中丢失的数据。如果我们的数据集包含一些缺失的数据,那么它可能会给我们的机器学习模型带来一个巨大的问题。因此,有必要处理数据集中缺失的值。
处理丢失数据的方法:
主要有两种方式来处理丢失的数据,它们是:
通过删除特定行:第一种方法通常用于处理空值。通过这种方式,我们只需删除包含空值的特定行或列。但是这种方法不是很有效,删除数据可能会导致信息的丢失,从而不能给出准确的输出。
通过计算平均值:这样,我们将计算包含任何缺失值的列或行的平均值,并将其放在缺失值的位置。这种策略对于具有数字数据的特征(如年龄、工资、年份等)非常有用。在这里,我们将使用这种方法。
为了处理缺失的值,我们将在代码中使用Scikit-learn库,其中包含用于构建机器学习模型的各种库。这里我们将使用sklearn的Imputer.preprocessing预处理库。下面是它的代码:
# 处理丢失的数据(用平均值替换丢失的数据)
from sklearn.preprocessing import Imputer
imputer= Imputer(missing_values ='NaN',strategy='mean',axis = 0)
# 将imputer对象与自变量x进行拟合。
imputer= imputer.fit(x[:,1:3])
# 用计算出的平均值代替缺失的数据
x[:,1:3]= imputer.transform(x[:,1:3])输出:
array([['India',38.0,68000.0],['France',43.0,45000.0],['Germany',30.0,54000.0],['France',48.0,65000.0],['Germany',40.0,65222.22222222222],['India',35.0,58000.0],['Germany',41.111111111111114,53000.0],['France',49.0,79000.0],['India',50.0,88000.0],['France',37.0,77000.0]],dtype=object正如我们在上面的输出中看到,遗漏值已替换为其他列值的平均值。
5)编码分类数据
分类数据是指在我们的数据集中有一些类别的数据;有两个分类变量,国家和购买。
由于机器学习模型完全适用于数学和数字,但是如果我们的数据集有一个分类变量,那么它可能会在构建模型时造成麻烦。所以有必要把这些分类变量编码成数字。
对于国家变量:
首先,我们将国家变量转换为分类数据。为此,我们将使用来自预处理库的LabelEncoder()类。
# 分类数据
# 国家变量
from sklearn.preprocessing import LabelEncoder
label_encoder_x= LabelEncoder()
x[:,0]= label_encoder_x.fit_transform(x[:,0])输出:
Out[15]:
array([[2,38.0,68000.0],[0,43.0,45000.0],[1,30.0,54000.0],[0,48.0,65000.0],[1,40.0,65222.22222222222],[2,35.0,58000.0],[1,41.111111111111114,53000.0],[0,49.0,79000.0],[2,50.0,88000.0],[0,37.0,77000.0]],dtype=object)说明:
在上面的代码中,我们导入了sklearn库的LabelEncoder类。这个类已经成功地将变量编码为数字。
但是在我们的例子中,有三个国家变量,正如我们在上面的输出中看到的,这些变量被编码为0、1和2。根据这些值,机器学习模型可能会假设这些变量之间存在某种相关性,从而产生错误的输出。为了消除这个问题,我们将使用虚拟编码。
虚拟变量:
虚拟变量是那些值为0或1的变量。1的值表示该变量在特定列中的存在,而其它变量变为0。使用虚拟编码,我们将拥有与类别数量相等的列数。
在我们的数据集中,我们有3个类别,因此它将生成3个列,分别具有0和1的值。对于虚拟编码,我们将使用onehotencoder类的预处理库。
#Country变量
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
label_encoder_x= LabelEncoder()
x[:,0]= label_encoder_x.fit_transform(x[:,0])
#虚拟变量编码
onehot_encoder= OneHotEncoder(categorical_features= [0])
x= onehot_encoder.fit_transform(x).toarray()输出:
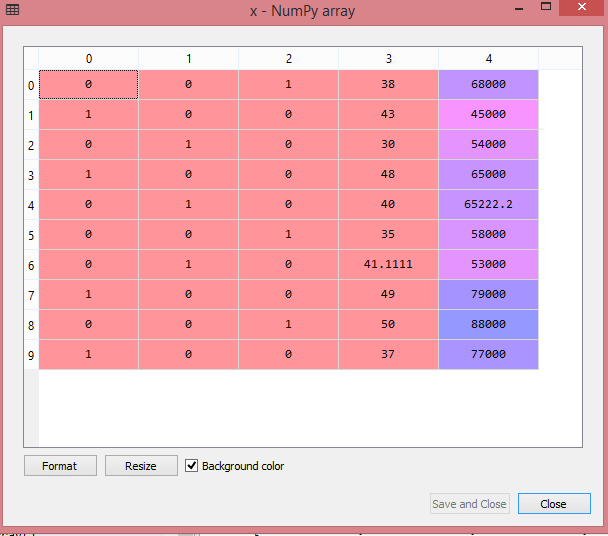
array([[0.00000000e+00,0.00000000e+00,1.00000000e+00,3.80000000e+01,6.80000000e+04],[1.00000000e+00,0.00000000e+00,0.00000000e+00,4.30000000e+01,4.50000000e+04],[0.00000000e+00,1.00000000e+00,0.00000000e+00,3.00000000e+01,5.40000000e+04],[1.00000000e+00,0.00000000e+00,0.00000000e+00,4.80000000e+01,6.50000000e+04],[0.00000000e+00,1.00000000e+00,0.00000000e+00,4.00000000e+01,6.52222222e+04],[0.00000000e+00,0.00000000e+00,1.00000000e+00,3.50000000e+01,5.80000000e+04],[0.00000000e+00,1.00000000e+00,0.00000000e+00,4.11111111e+01,5.30000000e+04],[1.00000000e+00,0.00000000e+00,0.00000000e+00,4.90000000e+01,7.90000000e+04],[0.00000000e+00,0.00000000e+00,1.00000000e+00,5.00000000e+01,8.80000000e+04],[1.00000000e+00,0.00000000e+00,0.00000000e+00,3.70000000e+01,7.70000000e+04]])正如我们可以在上面输出中看到,所有变量都被编码成数字0和1,并分成三列。
通过单击x选项,可以在变量资源管理器部分更清楚地看到它:
对于购买变量:
labelencoder_y= LabelEncoder()
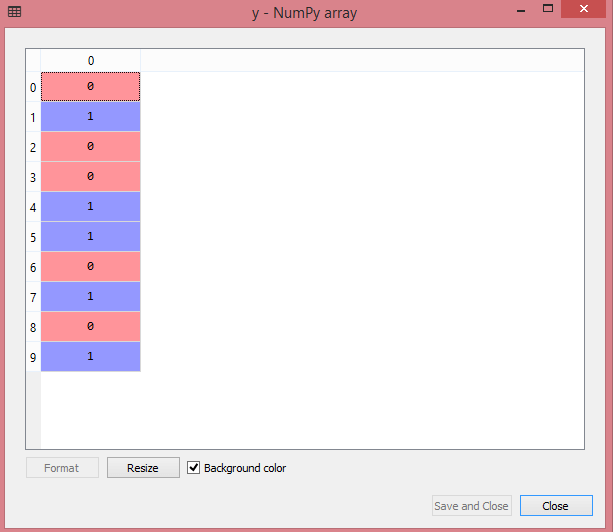
y= labelencoder_y.fit_transform(y)对于第二个分类变量,我们将只使用LableEncoder类labelencoder对象。在这里,我们不使用OneHotEncoder类,因为购买的变量只有两个类别是或否,并且被自动地编码成0和1。
输出:
Out[17]: array([0,1,0,0,1,1,0,1,0,1])它也可以被看作是:
6)将数据集分为训练集和测试集
在机器学习数据预处理,我们把我们的数据集中到一个训练集和测试集。这是数据预处理,通过这样的关键步骤之一,我们可以提高我们的机器学习模型的性能。
假设,如果我们用一个数据集来训练我们的机器学习模型,然后用一个完全不同的数据集来测试它。然后,这会给我们的模型理解模型之间的相关性带来困难。
如果我们很好地训练我们的模型,它的训练精度也很高,但是我们给它提供了一个新的数据集,那么它会降低性能。因此,我们总是试图建立一个使用训练集和测试数据集都表现良好的机器学习模型。在这里,我们可以将这些数据集定义为:
训练集:数据集的一个子集来训练机器学习模型,我们已经知道的输出。
测试设置:一个子集的数据集来测试机器学习模型,并通过使用测试集,模型预测输出。
为了分割数据集,我们将使用以下代码行:
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test= train_test_split(x,y,test_size= 0.2,random_state=0)说明:
- 在上面的代码中,第一行用于将数据集的数组分割成随机的序列和测试子集。
- 在第二行,我们使用了四个变量作为输出: x_train:训练数据的特征,x_test:测试数据的特征,y_train:训练数据的因变量,y_test:测试数据的自变量。
- 在train_test_split()函数,我们已经通过四个参数,其中前两个是用于数据的阵列,以及test_size是用于指定测试集的大小。所述test_size也许0.5,0.3,或0.2,它告诉训练集和测试集的分频比。
- 最后一个参数random_state用于设置一个种子随机生成,让你总是得到相同的结果,而这个最常用的值是42。
输出:
通过执行上述代码,我们将得到4个不同的变量,可以在变量资源管理器部分看到它们。
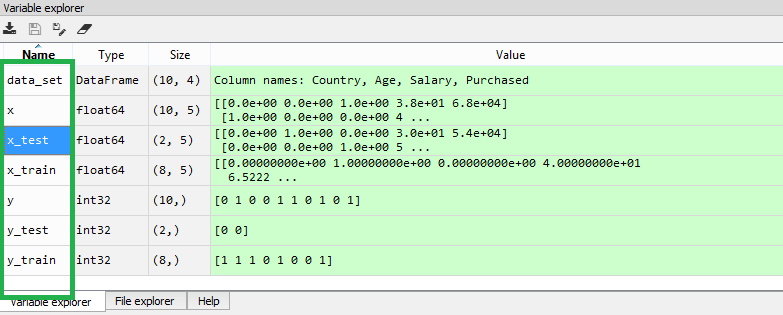
正如我们可以在上述图像中看到的,变量x和y被分成4个不同的变量具有相应的值。
7)特征缩放
特征缩放是机器学习中数据预处理的最后一步。它是在特定范围内标准化数据集的自变量的一种技术。在特征缩放中,我们把变量放在相同的范围内,这样就不会有任何变量支配其他变量。
考虑下面的数据集:
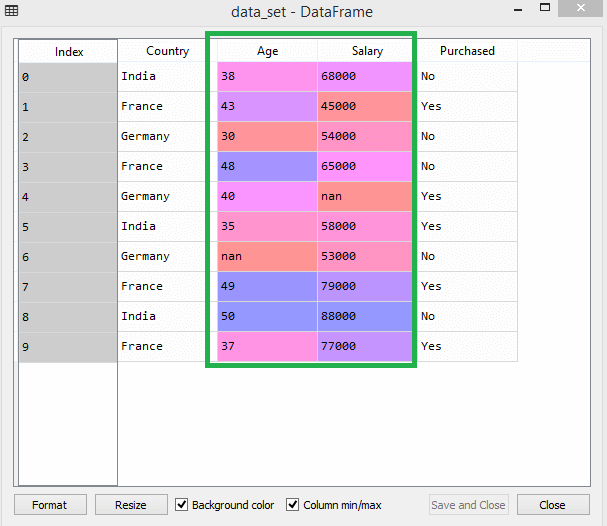
正如我们所看到的,年龄和薪水列的值是不相同的规模。机器学习模型是基于欧氏距离,如果我们不缩放变量,那么它会引起一些问题,在我们的机器学习模型。
欧氏距离给出如下:
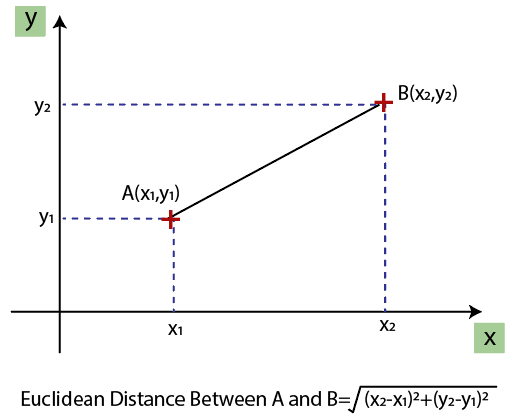
如果我们从年龄和工资中计算任意两个值,那么工资值将主导年龄值,并将产生一个错误的结果。为了解决这个问题,我们需要对机器学习进行特征缩放。
在机器学习中有两种方法可以实现特征缩放:
标准化
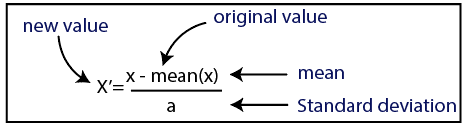
正常化
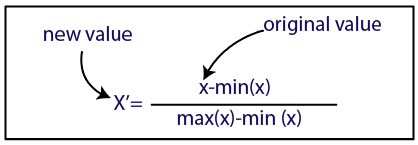
在这里,我们将使用我们的数据的标准化方法。
对于特征缩放,我们将导入sklearn.preprocessing库作为StandardScaler类:
from sklearn.preprocessing import StandardScaler现在,我们将为独立变量或特性创建StandardScaler类的对象。然后我们将拟合和转换训练数据集。
st_x= StandardScaler()
x_train= st_x.fit_transform(x_train)对于测试数据集,我们将直接应用transform()函数,而不是fit_transform(),因为它已经在训练集中完成了。
x_test= st_x.transform(x_test)输出:
通过执行上述代码行,我们将得到x_train和x_test的缩放值:
x_train:

x_test:
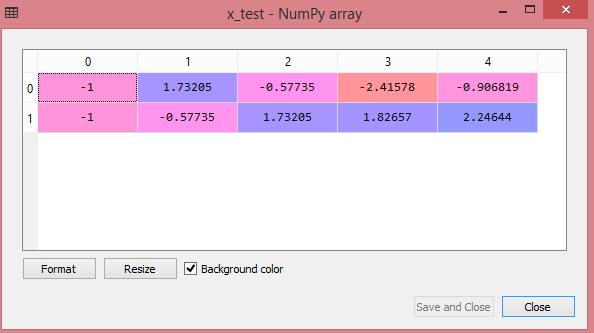
正如我们在上面的输出中看到的,所有的变量都是在-1到1之间缩放的。
注:这里,我们没有缩放因变量因为只有两个值0和1。但是如果这些变量有更多的取值范围,那么我们也需要缩放这些变量。
结合所有的步骤:
现在,到了最后,我们可以将所有的步骤结合起来,使我们完整的代码更容易理解。
# 1、导入库: numpy作为数学处理, matplotlib.pyplot提供绘图, pandas提供数据集导入和处理
import numpy as nm
import matplotlib.pyplot as mtp
import pandas as pd
# 2、导入数据集
data_set= pd.read_csv('Dataset.csv')
# 3、提取自变量
x= data_set.iloc[:, :-1].values
# 4、提出因变量
y= data_set.iloc[:, 3].values
# 4、处理丢失的数据(用平均值替换丢失的数据)
from sklearn.preprocessing import Imputer
imputer= Imputer(missing_values ='NaN', strategy='mean', axis = 0)
# 5、将估算对象拟合到独立变量x上。
imputer= imputer.fit(x[:, 1:3])
# 6、用计算出的平均值代替缺失的数据
x[:, 1:3]= imputer.transform(x[:, 1:3])
# 7、分类编码: Country变量
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
# 8、虚拟变量编码
onehot_encoder= OneHotEncoder(categorical_features= [0])
x= onehot_encoder.fit_transform(x).toarray()
# 9、购买变量编码
labelencoder_y= LabelEncoder()
y= labelencoder_y.fit_transform(y)
# 10、数据集分为训练集和测试集。
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
# 11、数据集的特征缩放
from sklearn.preprocessing import StandardScaler
st_x= StandardScaler()
x_train= st_x.fit_transform(x_train)
x_test= st_x.transform(x_test)在上面的代码中,我们包含了所有的数据预处理在一起的步骤。但是有一些步骤或代码不是所有机器学习模式所必需的。所以我们可以把它们从我们的代码中去掉,这样我们就可以为所有的模型提供可替代的服务。
评论前必须登录!
注册