 srcmini
srcmini本文概要
监督和无监督学习是机器学习的两种技术。但这两种技术在不同的场景和不同的数据集使用。下面给出了两种学习方法的解释及其差异表。
监督机器学习
监督学习是一种机器学习方法,其中模型训练使用标记数据。在监督学习中,模型需要找到映射函数来映射输入变量(X)和输出变量(Y)。
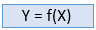
监督学习需要监督来训练模型,就像学生在老师面前学习一样。监督学习可用于两类问题: 分类和回归。
了解更多监督机器学习
例如:假设我们有一个不同种类水果的图像。我们的监督学习模型的任务是识别和分类结果。因此,为了识别监督学习中的图像,我们将给出输入数据和输出数据,这意味着我们将根据每个水果的形状、大小、颜色和味道来训练模型。一旦训练完成,我们将通过提供新的水果集来测试模型。该模型将使用合适的算法识别水果并预测输出。
无监督机器学习
无监督学习是另一种机器学习方法,它从未标记的输入数据中推断出模式。无监督学习的目标是从输入数据中找到结构和模式。无监督学习不需要任何监督。相反,它自己从数据中寻找模式。
了解更多无监督机器学习
无监督的学习可以用于两种类型的问题:聚类和关联。
例如:为了理解无监督学习,我们将使用上面给出的例子。与监督学习不同的是,我们不会对模型进行任何监督。我们将向模型提供输入数据集,并允许模型从数据中找到模式。在合适的算法的帮助下,模型会训练自己,根据水果之间最相似的特征将它们分成不同的组。
监督和无监督学习的主要区别给出如下:
| 监督学习 | 无监督学习 |
|---|---|
| 监督学习算法使用标记数据进行训练。 | 无监督学习算法使用未标记的数据进行训练。 |
| 监督学习模型将直接反馈给检查它是否正确预测输出与否。 | 无监督学习模型不接受任何反馈。 |
| 监督学习模型预测输出。 | 无监督学习模型发现数据中隐藏的模式。 |
| 在监督学习中,输入数据与输出一起提供给模型。 | 在无监督学习中,只向模型提供输入数据。 |
| 监督学习的目标是训练模型,这样当它被赋予了新的数据,则可以预测的输出。 | 无监督学习的目标是从未知数据集中发现隐藏的模式和有用的见解。 |
| 监督学习需要监督来训练模型。 | 无监督学习不需要任何监督训练模型。 |
| 监督学习可以分为分类和回归问题。 | 无监督学习可以分为聚类问题和关联问题。 |
| 监督学习可以用于那些我们所知道的输入以及相应的输出情况。 | 无监督学习可以用于只有输入数据而没有相应输出数据的情况。 |
| 监督学习模型产生准确的结果。 | 相比于监督学习无监督学习模式可能会不太准确的结果。 |
| 在这里,我们首先训练每个数据的模型,然后只有它才能预测正确的输出。 | 无监督学习更接近于真正的人工智能,因为它学习的方式类似于儿童通过经验学习日常事务。 |
| 它包括各种算法,例如线性回归,Logistic回归,支持向量机,多类分类,决策树,贝叶斯逻辑等 | 它包括各种算法,如聚类,KNN, Apriori算法。 |
评论前必须登录!
注册