 srcmini
srcmini本文概要
我们知道,在监督的机器学习算法可以大致分为回归和分类算法。在回归算法,我们预测连续值的输出,但预测分类值,我们需要分类算法。
什么是分类算法?
分类算法是用来识别训练数据的基础上的新的观测类别监督学习技术。在分类上,从给定的数据集或观察程序学习并然后分类新的观察为多个类或组。比如,Yes或No,0或1,垃圾邮件或者非垃圾邮件,猫或狗等类可以被称为目标/标签或类别。
不像回归,分类器的输出变量是一个类别,而不是一个值,例如“绿色或蓝色”,“水果或动物”等。由于分类算法是监督学习技术,因此它需要标注的输入数据,其意味着它包含具有对应的输出的输入。
在分类算法,离散输出函数(Y)被映射到输入变量(x)。
y=f(x),where y = categorical output一个ML分类算法的最好的例子就是电子邮件垃圾邮件检测器。
分类算法的主要目标是确定一个给定的数据集的类,并且这些算法主要用于预测中的分类数据的输出。
分类算法可以使用下面的图可以更好地理解。在下面的图中,有两个类,类A和B类这些类拥有的功能是彼此相似的和不相似的其他类。
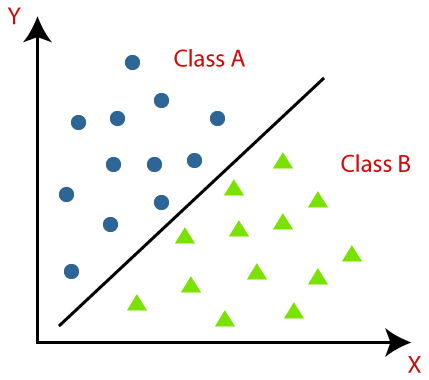
它实现对数据集进行分类的算法被称为分类器。有两种类型的分类的:
- 二元分类:如果分类问题只有两种可能的结果,那么它被称为二元分类。实例:YES或NO,男性或女性,SPAM或NOT SPAM,猫或狗等
- 多级分类:若某分类问题有两个以上的结果,那么它被称为多级分类。示例:作物种类分类的音乐类型分类。
在分类问题学生
在分类的问题,有两种类型的学习者:
- 懒学生:直到接收到测试数据集懒学习者首先存储训练数据集和等待。在懒惰学习者的情况下,分类存储在训练数据集的最相关数据的基础上完成的。这需要在训练,但更多的时间进行预测的时间更少。例如:K-NN算法,基于案例的推理
- 渴望学习者:渴望学习者开发基于训练数据集分类模型接收测试数据集之前。相反懒学生,渴望学习花费更少的时间在预测的训练和更多的时间。例如:决策树,朴素贝叶斯,ANN。
ML分类算法的类型
分类算法可以进一步分为主要有两种类型:
- 线性模型Logistic回归支持向量机
- 非线性模型K-近邻核SVM贝叶斯决策树分类随机森林分类
注意:我们将吸取上述算法,在后面的章节。
评估分类模型
一旦我们的模型完成后,有必要评价其业绩;要么它是一个分类或回归模型。因此,对于评估分类模型,我们有以下几种方式:
1.登录损失或交叉熵损失:
- 它用于评估分类器的性能,它的输出是0和1之间的概率值。
- 对于一个良好的二元分类模型,日志的损失值应接近为0。
- 日志损失增加的值,如果预测值与实际值偏差。
- 较低的日志损失表示模型的精度更高。
- 对于二元分类,交叉熵可以计算为:
?(ylog(p)+(1?y)log(1?p))其中y =实际输出,P =预测的输出。
2.混淆矩阵:
- 混淆矩阵提供给我们的基质/表作为输出,并描述了该模型的性能。
- 它也被称为误差矩阵。
- 所述基质由预测导致概括形式,其具有正确的预测和不正确的预测的总数量。矩阵的样子如下表所示:
| 实际利好 | 实际负 | |
|---|---|---|
| Predicted Positive | True Positive | 假阳性 |
| Predicted Negative | False Negative | 真阴性 |

3. AUC-ROC曲线:
- ROC曲线代表接收器工作特性曲线及AUC代表曲线下面积。
- 这是示出了在不同的阈值的分类模型的性能的曲线图。
- 以可视化的多类分类模型的性能,我们使用了AUC-ROC曲线。
- ROC曲线绘制与TPR和FPR,其中在Y轴X轴TPR(真阳性率)和FPR(假阳性率)。
分类算法的使用案例
分类算法可以在不同的地方使用。下面是分类算法的一些流行的用例:
- 垃圾邮件检测
- 语音识别
- 癌肿瘤细胞的标识。
- 药品分类
- 生物识别等。
评论前必须登录!
注册