 srcmini
srcmini在编译器前端中,实现词法分析的方式有两种:编码实现和使用生成器实现。编码实现就是手工编程,使用特定的算法和数据结构实现一个词法分析器,这种方式实现起来比较困难,也比较复杂,你需要有更好的编程基础和严谨的设计,但是这种方式实现的分析器效率高,也比较可控。目前使用这种方式实现的有GCC和LLVM。
使用生成器实现一个分析器则显得相当简单,虽然细节上不大可控,但是这是目前实现一个分析器最快速的方式了,之后几节会详细围绕这种方式进行讲解。常见的生成器有Lex和Flex,词法分析器生成器也是一个翻译器,它负责将词法规则翻译成C语言源代码,使用C编译器对该源代码进行编译生成词法分析器,然后使用该分析器就可以对目标源文件进行分析了。
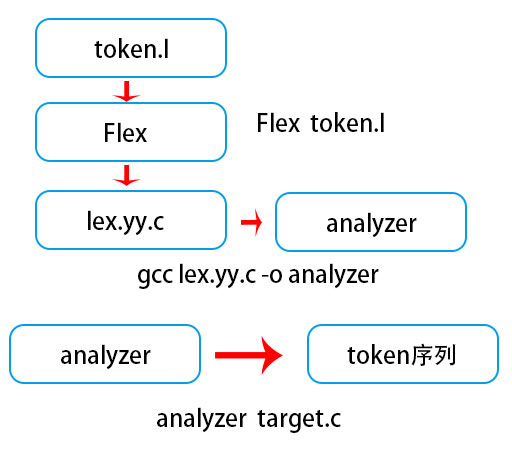
一、词法分析器生成器安装和简单使用
使用生成器需要编写一个l文件,该文件使用lex语言规范编写正则表达式,Flex翻译成的lex.yy.c文件是分析器的主要部分,包含DFA状态转移表和驱动该表的程序。因此,在实现分析器之前我们需要学习正则表达式的编写,以及生成器的工作原理。
1、下载工具
Windows平台Flex立即吃瓜:https://sourceforge.net/projects/winflexbison/
Linux Ubuntu安装命令:sudo apt-get install flex
CentOS安装命令:yum install flex
Flex词法规则文件下载: https://pan.baidu.com/s/1-gbi2OQFzxtwAuCYYZY5Sg
提取码: tpwi
2、创建hello.c源文件:
#include <stdio.h>
int main(){
char *message = "hello ubuntu!";
printf("message: %s\n", message);
return 0;
}
3、生成词法分析器
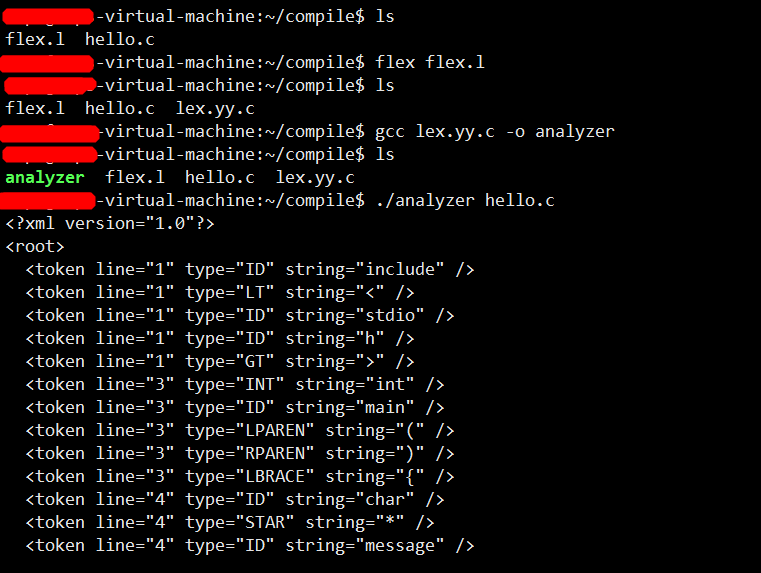
以上是一个简单的使用,flex的词法规则文件仅做暂时调试使用,实际中我们需要自己编写,因此我们需要重点学下正则表达式。
二、正则表达式(Regular Expression)
正则表达式是一个字符串,用于匹配一系列符合该字符串规则的文本,表面看来它其实很繁琐,这个很多时候是因为高级语言需要更好更强大的表示造成的。实际上正则表达式只有三种基本运算:
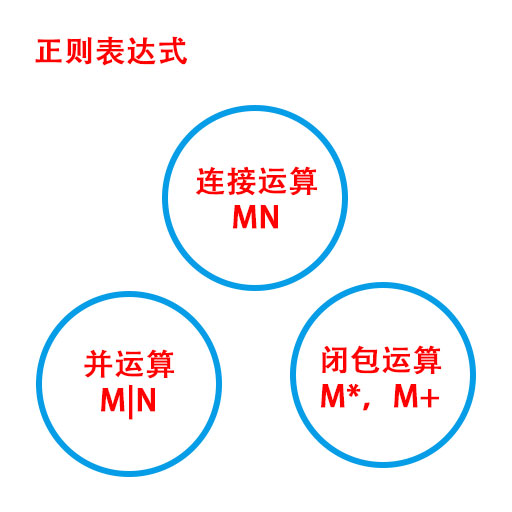
设M和N分别都是一个正则表达式:
连接运算:MN,两个表达式是连起来的,所以只能顺序地进行匹配,例如ab,只能匹配文本中只有ab的部分。
并运算:M|N,并的意思是集合中的并集,也有同时的意思,比如a|b,同时可以匹配文本中的任何a和任何b。
闭包运算:M*或M+,连接重复匹配,M*连接多次M表达式进行重复匹配,如ab*,可以匹配后面有n个b的字符串,[ab]+ 是重复匹配1次或多次ab。
以上是正则表达式的基本运算,另外正则化还有一个匹配次数的概念,次数可表示为{n,m},n表示最少匹配次数,m表示最大匹配次数,留空表示多次。如[ab]{1,}表示匹配ab一次或多次。大括号{}用于匹配次数,方括号[]表示字符并集。
如果你觉得平时使用正则表达式很繁琐,那么掌握以上核心可以让你更轻松使用到正则化的强大功能,它是文本处理的神器。
三、正则表达式的使用例子
正则化不仅限于在词法分析器中使用,比如在爬虫中也有可能会用到,如下面一段html文本,首先我们的目标是匹配出所有的a元素:

可以使用表达式:<a([\s]*|(\shref=”[/a-z]*”))>[0-9a-zA-Z ]*</a>,匹配结果如下:

如果我们需要取出标签a的值,可以使用:[A-Z][a-zA-Z\s]+,简单取出目标值:

评论前必须登录!
注册