 srcmini
srcmini如果你刚刚开始使用Python, 并且想了解更多信息, 请参加srcmini的Python数据科学入门课程。

在Internet上拥有如此多数据的时代, 显然, 数据已成为一种新的石油, Web抓取在各种应用中变得更加重要和实用。 Web抓取处理从网站中提取或抓取信息。 Web抓取有时也称为Web收集或Web数据提取。从网站复制文本并将其粘贴到本地系统也是Web抓取。但是, 这是一项手动任务。通常, 网络抓取是在网络搜寻器的帮助下自动提取数据。 Web搜寻器是使用HTTP协议连接到万维网的脚本, 可让你以自动方式获取数据。
无论你是数据科学家, 工程师, 还是分析大量数据集的任何人, 从Web抓取数据的能力都是一项有用的技能。假设你是从网络上找到数据的, 没有直接下载的方法, 使用Python进行网络抓取是一项技巧, 你可以用来将数据提取为有用的形式, 然后以各种方式导入和使用。
网页抓取的一些实际应用可能是:
- 收集具有特定技能的候选人的简历,
- 从Twitter提取带有特定主题标签的推文,
- 市场营销中的潜在客户,
- 从电子商务网站上搜爬取产品详细信息和评论。
除上述用例外, 网络抓取还广泛用于自然语言处理中, 用于从网站中提取文本以训练深度学习模型。
Web爬网的潜在挑战
- 从网站抓取信息时遇到的挑战之一是网站的各种结构。这意味着网站模板将有所不同并且将是唯一的;因此, 跨网站推广可能是一个挑战。
- 另一个挑战可能是寿命。由于Web开发人员不断更新其网站, 因此你肯定不能长期依赖一个爬虫。尽管修改可能很小, 但它们在获取数据时仍可能给你带来障碍。
因此, 为了解决上述挑战, 可能有各种可能的解决方案。一种方法是遵循持续的集成与开发(CI / CD)和不断的维护, 因为网站的修改是动态的。
另一个更现实的方法是使用各种网站和平台提供的应用程序编程接口(API)。例如, Facebook和Twitter为你提供了API, 这些API是专门为想要试验其数据或想要提取信息(比如说与所有朋友和共同朋友相关的信息)并为其绘制连接图的开发人员而设计的。使用API时的数据格式与通常的Web抓取(即JSON或XML)不同, 而在标准Web抓取中, 你主要处理HTML格式的数据。
什么是Beautiful Soup?
Beautiful Soup是一个纯Python库, 用于从网站提取结构化数据。它允许你解析HTML和XML文件中的数据。它充当帮助程序模块, 并以与你使用其他可用的开发人员工具与网页进行交互的方式类似且更好的方式与HTML交互。
- 由于它可以与你喜欢的解析器(例如lxml和html5lib)一起使用, 从而提供了导航, 搜索和修改解析树的有机Python方式, 因此通常可以节省程序员的工作时间或工作量。
- Beautiful Soup的另一个强大而有用的功能是其智能, 可以将获取的文档转换为Unicode, 并将传出的文档转换为UTF-8。作为开发人员, 除非文档固有的未指定编码或Beautiful Soup无法检测到编码, 否则你不必担心。
- 与其他常规解析或抓取技术相比, 它也被认为更快。
解析器的类型

资源
请随时从这里阅读更多有关它的内容。
理论够了吧?因此, 让我们安装Beautiful Soup, 并开始使用Python学习它的特性和功能。
第一步, 你需要使用终端机或jupyter实验室安装Beautiful Soup库。安装Beautiful Soup的最好方法是通过pip, 因此请确保已安装pip模块。
!pip3 install beautifulsoup4
Requirement already satisfied: beautifulsoup4 in /usr/local/lib/python3.7/site-packages (4.7.1)
Requirement already satisfied: soupsieve>=1.2 in /usr/local/lib/python3.7/site-packages (from beautifulsoup4) (1.9.5)
导入必要的库
让我们导入所需的软件包, 你将使用这些软件包从网站上抓取数据并借助seaborn, matplotlib和bokeh将其可视化。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
import re
import time
from datetime import datetime
import matplotlib.dates as mdates
import matplotlib.ticker as ticker
from urllib.request import urlopen
from bs4 import BeautifulSoup
import requests
爬取亚马逊畅销书
你要抓取的该URL是以下内容:https://www.amazon.in/gp/bestsellers/books/ref=zg_bs_pg_’+str(pageNo)+’?ie=UTF8&pg=’+str(pageNo) (如果你无法访问此链接, 则为父链接)。如你所见, 可以修改page参数以访问每个页面的数据。因此, 要访问所有页面, 你将需要遍历所有页面以获取必要的数据集, 但是首先, 你需要从网站上查找页面数。
要连接到URL并获取HTML内容, 需要执行以下操作:
- 定义一个get_data函数, 它将输入页码作为参数,
- 定义一个用户代理, 这将有助于绕过检测程序而成为爬取板,
- 指定requests.get的URL, 并将用户代理标头作为参数传递,
- 从requests.get中提取内容,
- 抓取指定的页面并将其分配给Soup变量,
接下来的重要步骤是确定父标记, 你需要的所有数据都将驻留在该父标记下。你要提取的数据是:
- 书名
- 作者
- 评分
- 客户评分
- 价钱
下图显示了父标记的位置, 将鼠标悬停在其上方时, 所有必需的元素都会突出显示。

与父标签类似, 你需要查找书名, 作者, 等级, 客户评级和价格的属性。你将必须转到要抓取的网页, 选择属性并右键单击它, 然后选择检查元素。这将帮助你找出需要从纯粹的HTML网页中提取的特定信息字段, 如下图所示:

请注意, 有些作者姓名未在Amazon注册, 因此你需要为这些作者申请额外的查找。在下面的单元代码中, 你将找到作者姓名的嵌套if-else条件, 该条件用于提取作者/出版物名称。
no_pages = 2
def get_data(pageNo):
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0", "Accept-Encoding":"gzip, deflate", "Accept":"text/html, application/xhtml+xml, application/xml;q=0.9, */*;q=0.8", "DNT":"1", "Connection":"close", "Upgrade-Insecure-Requests":"1"}
r = requests.get('https://www.amazon.in/gp/bestsellers/books/ref=zg_bs_pg_'+str(pageNo)+'?ie=UTF8&pg='+str(pageNo), headers=headers)#, proxies=proxies)
content = r.content
soup = BeautifulSoup(content)
#print(soup)
alls = []
for d in soup.findAll('div', attrs={'class':'a-section a-spacing-none aok-relative'}):
#print(d)
name = d.find('span', attrs={'class':'zg-text-center-align'})
n = name.find_all('img', alt=True)
#print(n[0]['alt'])
author = d.find('a', attrs={'class':'a-size-small a-link-child'})
rating = d.find('span', attrs={'class':'a-icon-alt'})
users_rated = d.find('a', attrs={'class':'a-size-small a-link-normal'})
price = d.find('span', attrs={'class':'p13n-sc-price'})
all1=[]
if name is not None:
#print(n[0]['alt'])
all1.append(n[0]['alt'])
else:
all1.append("unknown-product")
if author is not None:
#print(author.text)
all1.append(author.text)
elif author is None:
author = d.find('span', attrs={'class':'a-size-small a-color-base'})
if author is not None:
all1.append(author.text)
else:
all1.append('0')
if rating is not None:
#print(rating.text)
all1.append(rating.text)
else:
all1.append('-1')
if users_rated is not None:
#print(price.text)
all1.append(users_rated.text)
else:
all1.append('0')
if price is not None:
#print(price.text)
all1.append(price.text)
else:
all1.append('0')
alls.append(all1)
return alls
下面的代码单元将执行以下功能:
- 在for循环中调用get_data函数,
- for循环将从1开始迭代此函数, 直到页面数+ 1。
- 由于输出将是一个嵌套列表, 因此你将首先将列表展平, 然后将其传递给DataFrame。
- 最后, 将数据框另存为CSV文件。
results = []
for i in range(1, no_pages+1):
results.append(get_data(i))
flatten = lambda l: [item for sublist in l for item in sublist]
df = pd.DataFrame(flatten(results), columns=['Book Name', 'Author', 'Rating', 'Customers_Rated', 'Price'])
df.to_csv('amazon_products.csv', index=False, encoding='utf-8')
读取CSV文件
现在, 让我们加载你创建的CSV文件并将其保存在上述单元格中。同样, 这是一个可选步骤;你甚至可以直接使用数据框df, 而忽略以下步骤。
df = pd.read_csv("amazon_products.csv")
df.shape
(100, 5)
数据框的形状表明, CSV文件中有100行和5列。
让我们打印数据集的前5行。
df.head(61)
| 书名 | 作者 | 评分 | 客户评分 | 价钱 | |
|---|---|---|---|---|---|
| 0 | 你的潜意识的力量 | 约瑟夫·墨菲 | 5星4.5 | 13, 948 | ¥ 99.00 |
| 1 | 思考致富 | 拿破仑山 | 5星4.5 | 16, 670 | ¥ 99.00 |
| 2 | 字动力变得简单 | 诺曼·刘易斯 | 5星4.4 | 10, 708 | ¥ 130.00 |
| 3 | 12年级数学(每册2册) | 夏尔马 | 5星4.5 | 18 | ₹930.00 |
| 4 | 105房间里的女孩 | 切坦·巴加特 | 5星4.3 | 5, 162 | ¥149.00 |
| … | … | … | … | … | … |
| 56 | JAIIB法律方面的指南组合包… | 麦克米兰 | 5星4.5 | 114 | ₹1, 400.00 |
| 57 | ren和马丁高中英语语法和… | 饶N | 5星4.4 | 1, 613 | ¥ 400.00 |
| 58 | 客观常识 | Sanjiv Kumar | 5星4.2 | 742 | ₹254.00 |
| 59 | 有史以来最粗鲁的书 | Shwetabh Gangwar | 4.6 / 5星 | 1, 177 | ¥ 194.00 |
| 60 | Sita:密西拉战士(Ram Chandra系列-… | 阿米什·特里帕蒂(Amish Tripathi) | 5星4.4 | 3, 110 | ¥ 248.00 |
61行×5列
让我们对等级, customers_rated和价格列进行一些预处理。
- 由于你知道评分不超过5, 因此你只能保留该评分, 并删除其中的多余部分。
- 在customers_rated列中, 删除逗号。
- 从价格列中删除卢比符号(逗号), 并按点将其分割。
- 最后, 将所有三列转换为整数或浮点数。
df['Rating'] = df['Rating'].apply(lambda x: x.split()[0])
df['Rating'] = pd.to_numeric(df['Rating'])
df["Price"] = df["Price"].str.replace('₹', '')
df["Price"] = df["Price"].str.replace(', ', '')
df['Price'] = df['Price'].apply(lambda x: x.split('.')[0])
df['Price'] = df['Price'].astype(int)
df["Customers_Rated"] = df["Customers_Rated"].str.replace(', ', '')
df['Customers_Rated'] = pd.to_numeric(df['Customers_Rated'], errors='ignore')
df.head()
| 书名 | 作者 | 评分 | 客户评分 | 价钱 | |
|---|---|---|---|---|---|
| 0 | 你的潜意识的力量 | 约瑟夫·墨菲 | 4.5 | 13948 | 99 |
| 1 | 思考致富 | 拿破仑山 | 4.5 | 16670 | 99 |
| 2 | 字动力变得简单 | 诺曼·刘易斯 | 4.4 | 10708 | 130 |
| 3 | 12年级数学(每册2册) | 夏尔马 | 4.5 | 18 | 930 |
| 4 | 105房间里的女孩 | 切坦·巴加特 | 4.3 | 5162 | 149 |
让我们验证DataFrame的数据类型。
df.dtypes
Book Name object
Author object
Rating float64
Customers_Rated int64
Price int64
dtype: object
将DataFrame中的零值替换为NaN。
df.replace(str(0), np.nan, inplace=True)
df.replace(0, np.nan, inplace=True)
计算数据框中NaN的数量
count_nan = len(df) - df.count()
count_nan
Book Name 0
Author 6
Rating 0
Customers_Rated 0
Price 1
dtype: int64
从上面的输出中, 你可以看到总共有六本书没有作者姓名, 而一本书没有与之相关的价格。这些信息对于想要出售其书籍并且不应该忽略放置此类信息的作者而言至关重要。
让我们删除这些NaN。
df = df.dropna()
作者最高价的书
让我们找出所有作者中价格最高的一本书。你将可视化此类前20名作者的结果。
data = df.sort_values(["Price"], axis=0, ascending=False)[:15]
data
| 书名 | 作者 | 评分 | 客户评分 | 价钱 | |
|---|---|---|---|---|---|
| 56 | JAIIB法律方面的指南组合包… | 麦克米兰 | 4.5 | 114 | 1400.0 |
| 98 | 耳鼻喉疾病 | 辛格拉 | 4.7 | 118 | 1285.0 |
| 3 | 12年级数学(每册2册) | 夏尔马 | 4.5 | 18 | 930.0 |
| 96 | Madhymik Bhautik Vigyan -12(Part 1-2)(NCERT … | 库马尔·米塔尔 | 5.0 | 1 | 765.0 |
| 6 | 我的第一个图书馆:10套董事会书籍的… | 妙宅书 | 4.5 | 3116 | 750.0 |
| 38 | 印度政体-用于公务员和其他社会 | 拉克斯米坎特 | 4.6 | 1210 | 700.0 |
| 42 | 言语与非言语娱乐的现代方法… | R.S.阿格瓦尔 | 4.4 | 1822 | 675.0 |
| 27 | 精明的投资者(英文)平装本-… | 本杰明·格雷厄姆(Benjamin Graham) | 4.4 | 6201 | 650.0 |
| 99 | 合同法和特殊救济 | Avtar Singh博士 | 4.4 | 23 | 643.0 |
| 49 | 一站式英语CBSE 12类2019-20 | 专家 | 4.4 | 493 | 599.0 |
| 72 | 秘密 | 朗达·伯恩 | 4.5 | 11220 | 556.0 |
| 86 | 如何准备适合自己的定量能力 | 阿伦·沙玛(Arun Sharma) | 4.4 | 847 | 537.0 |
| 8 | 竞争性考试的定量能力 | 阿加瓦尔 | 4.4 | 4553 | 435.0 |
| 16 | 智人:人类简史 | 尤瓦尔·诺亚·哈拉里(Yuval Noah Harari) | 4.6 | 14985 | 434.0 |
| 84 | 物理概念第二部分(2019-2020届)… | H.C.维玛 | 4.6 | 1807 | 433.0 |
from bokeh.models import ColumnDataSource
from bokeh.transform import dodge
import math
from bokeh.io import curdoc
curdoc().clear()
from bokeh.io import push_notebook, show, output_notebook
from bokeh.layouts import row
from bokeh.plotting import figure
from bokeh.transform import factor_cmap
from bokeh.models import Legend
output_notebook()
加载BokehJS …
p = figure(x_range=data.iloc[:, 1], plot_width=800, plot_height=550, title="Authors Highest Priced Book", toolbar_location=None, tools="")
p.vbar(x=data.iloc[:, 1], top=data.iloc[:, 4], width=0.9)
p.xgrid.grid_line_color = None
p.y_range.start = 0
p.xaxis.major_label_orientation = math.pi/2
show(p)
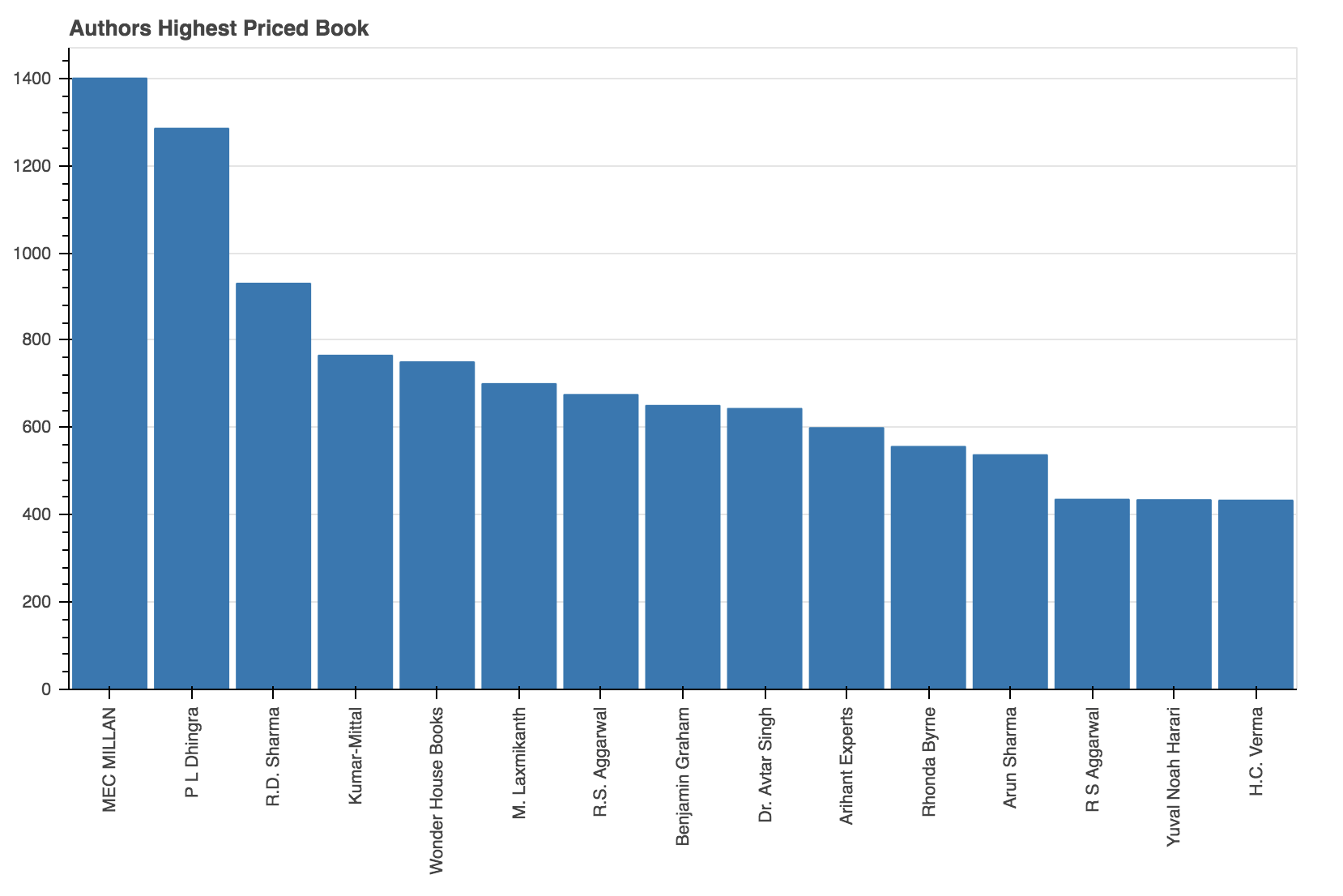
从上图可以看出, 价格最高的两本书是作者Mecmillan和P L Dhingra撰写的。
客户评价最高的书籍和作者
让我们找出哪些作者的书籍收视率最高, 以及哪些作者的书籍收视率最高。但是, 在找出答案的同时, 你会过滤掉那些少于1000位客户评价的作者。
data = df[df['Customers_Rated'] > 1000]
data = data.sort_values(['Rating'], axis=0, ascending=False)[:15]
data
| 书名 | 作者 | 评分 | 客户评分 | 价钱 | |
|---|---|---|---|---|---|
| 26 | 内部工程:瑜伽士的欢乐指南 | 萨杜古鲁 | 4.7 | 4091 | 254.0 |
| 70 | 博伽梵歌(印地语) | A. C. Bhaktivedanta | 4.7 | 1023 | 150.0 |
| 11 | 炼金术士 | 保罗·科埃略 | 4.7 | 22182 | 264.0 |
| 47 | 哈利·波特与魔法石 | J.K.罗琳 | 4.7 | 7737 | 234.0 |
| 84 | 物理概念第二部分(2019-2020届)… | H.C.维玛 | 4.6 | 1807 | 433.0 |
| 16 | 智人:人类简史 | 尤瓦尔·诺亚·哈拉里(Yuval Noah Harari) | 4.6 | 14985 | 434.0 |
| 38 | 印度政体-用于公务员和其他社会 | 拉克斯米坎特 | 4.6 | 1210 | 700.0 |
| 29 | 火翼:阿卜杜勒·卡拉姆自传 | 阿伦·蒂瓦里(Arun Tiwari) | 4.6 | 3513 | 301.0 |
| 39 | 万物理论 | 史蒂芬·霍金 | 4.6 | 2004 | 199.0 |
| 25 | The Immortals of Meluha (Shiva Trilogy) | 阿米什人 | 4.6 | 4538 | 248.0 |
| 23 | 生命的奇妙秘诀:如何找到平衡和… | 加尔·戈帕尔·达斯(Gaur Gopal Das) | 4.6 | 3422 | 213.0 |
| 34 | 亲爱的陌生人, 我知道你的感觉 | 阿什什·巴格里查(Ashish Bagrecha) | 4.6 | 1130 | 167.0 |
| 17 | 出售法拉利的和尚 | 罗宾·夏尔马 | 4.6 | 5877 | 137.0 |
| 13 | 如何赢得朋友并影响人 | 戴尔卡耐基 | 4.6 | 15377 | 99.0 |
| 59 | 有史以来最粗鲁的书 | Shwetabh Gangwar | 4.6 | 1177 | 194.0 |
p = figure(x_range=data.iloc[:, 0], plot_width=800, plot_height=600, title="Top Rated Books with more than 1000 Customers Rating", toolbar_location=None, tools="")
p.vbar(x=data.iloc[:, 0], top=data.iloc[:, 2], width=0.9)
p.xgrid.grid_line_color = None
p.y_range.start = 0
p.xaxis.major_label_orientation = math.pi/2
show(p)
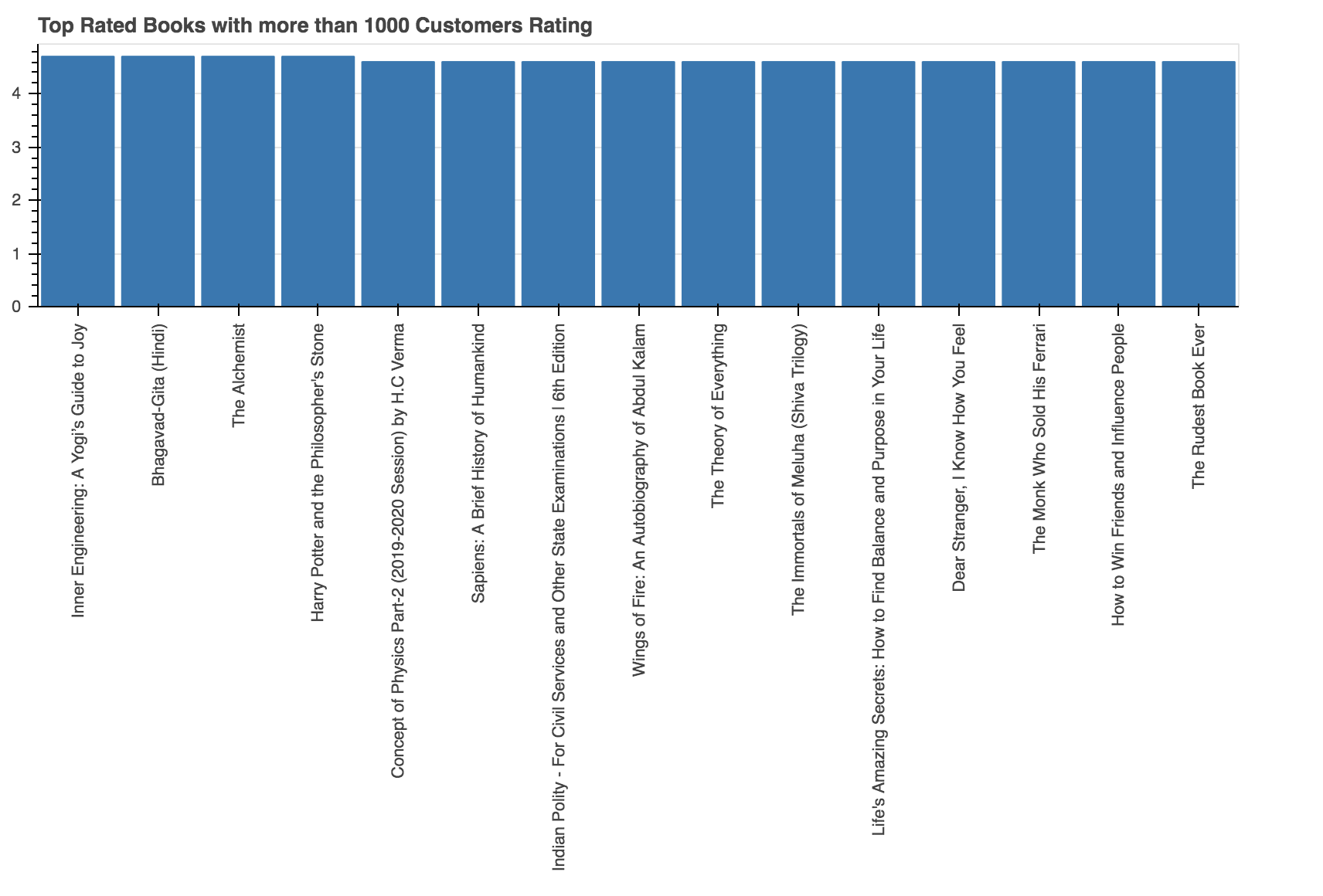
从上面的输出中, 你可以看到, 拥有超过1000个客户评分的前三本书是《内部工程》:《瑜伽士的喜悦指南》, 《博伽梵歌》(印地语)和《炼金术士》。
p = figure(x_range=data.iloc[:, 1], plot_width=800, plot_height=600, title="Top Rated Books with more than 1000 Customers Rating", toolbar_location=None, tools="")
p.vbar(x=data.iloc[:, 1], top=data.iloc[:, 2], width=0.9)
p.xgrid.grid_line_color = None
p.y_range.start = 0
p.xaxis.major_label_orientation = math.pi/2
show(p)
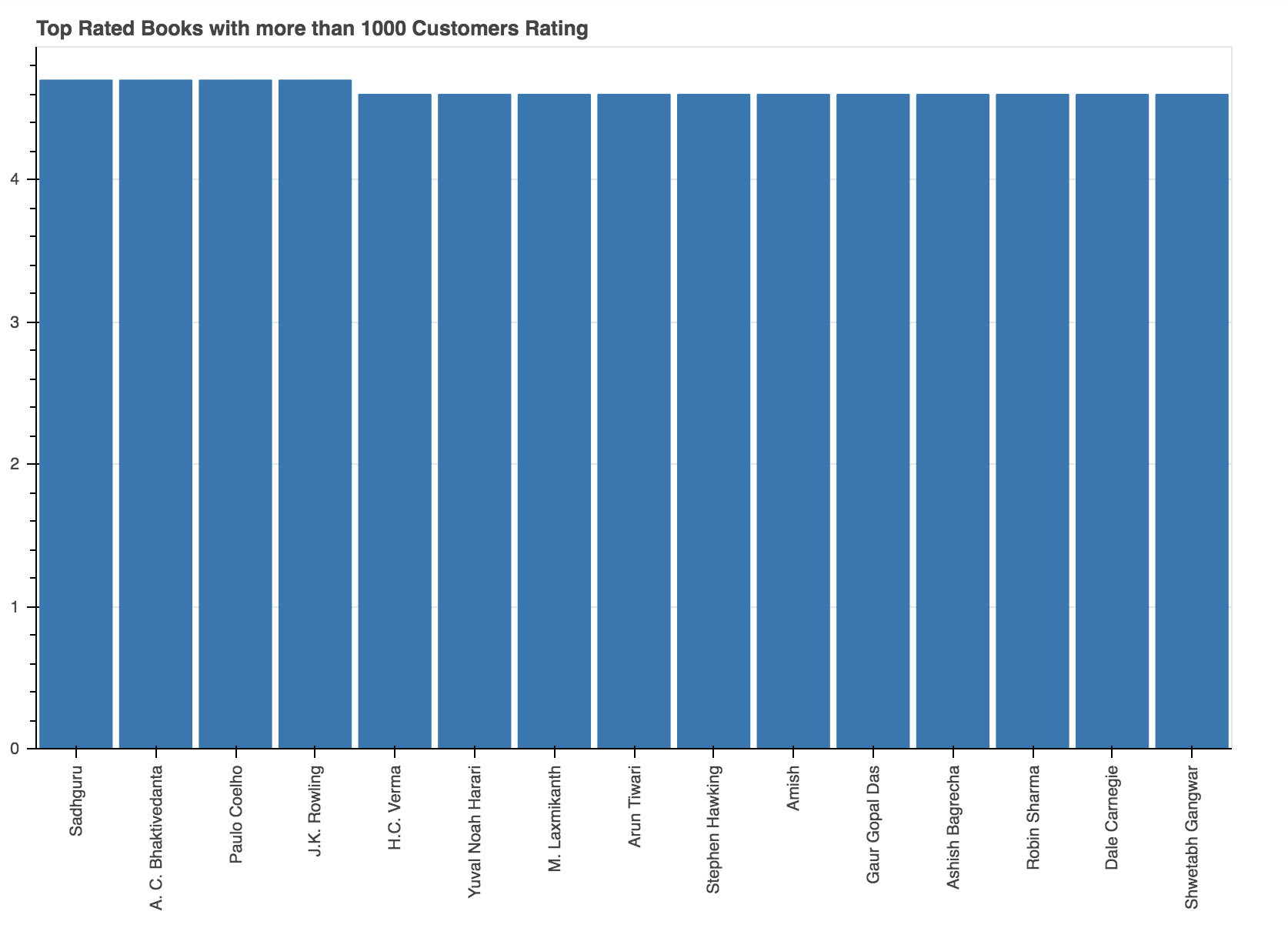
上图以降序排列显示了排名最高的前10位作者, 他们的最高评价书具有超过1000个客户评价, 它们分别是Sadhguru, A。C. Bhaktivedanta和Paulo Coelho。
多数客户评价的作者和书籍
尽管你已经看到了顶级图书和顶级作者, 但根据对这本书评价的客户数量, 得出最佳作者和该书仍然更具说服力和可信度。
因此, 让我们快速找到答案。
data = df.sort_values(["Customers_Rated"], axis=0, ascending=False)[:20]
data
| 书名 | 作者 | 评分 | 客户评分 | 价钱 | |
|---|---|---|---|---|---|
| 11 | 炼金术士 | 保罗·科埃略 | 4.7 | 22182 | 264.0 |
| 1 | 思考致富 | 拿破仑山 | 4.5 | 16670 | 99.0 |
| 13 | 如何赢得朋友并影响人 | 戴尔卡耐基 | 4.6 | 15377 | 99.0 |
| 16 | 智人:人类简史 | 尤瓦尔·诺亚·哈拉里(Yuval Noah Harari) | 4.6 | 14985 | 434.0 |
| 18 | 有钱的爸爸可怜的爸爸:有钱人教他们… | 罗伯特·清崎 | 4.5 | 14591 | 296.0 |
| 10 | 不给力的微妙艺术 | 马克·曼森 | 4.4 | 14418 | 365.0 |
| 0 | 你的潜意识的力量 | 约瑟夫·墨菲 | 4.5 | 13948 | 99.0 |
| 48 | 你的潜意识的力量 | 约瑟夫·墨菲 | 4.5 | 13948 | 99.0 |
| 72 | 秘密 | 朗达·伯恩 | 4.5 | 11220 | 556.0 |
| 41 | 1984 | 乔治·奥威尔 | 4.5 | 10829 | 95.0 |
| 2 | 字动力变得简单 | 诺曼·刘易斯 | 4.4 | 10708 | 130.0 |
| 46 | 男人的意义追求:经典致敬… | 维克多·E·弗兰克尔 | 4.4 | 8544 | 245.0 |
| 67 | 高效率人才的7种习惯 | 斯蒂芬·科维 | 4.3 | 8229 | 397.0 |
| 47 | 哈利·波特与魔法石 | J.K.罗琳 | 4.7 | 7737 | 234.0 |
| 40 | 一个印度女孩 | 切坦·巴加特 | 3.8 | 7128 | 113.0 |
| 65 | 思考, 快速和慢速(企鹅出版社非虚构类) | 丹尼尔·卡尼曼 | 4.4 | 7087 | 410.0 |
| 27 | 精明的投资者(英文)平装本-… | 本杰明·格雷厄姆(Benjamin Graham) | 4.4 | 6201 | 650.0 |
| 17 | 出售法拉利的和尚 | 罗宾·夏尔马 | 4.6 | 5877 | 137.0 |
| 53 | Ram-Ikshvaku的接穗(Ram Chandra) | 阿米什·特里帕蒂(Amish Tripathi) | 4.2 | 5766 | 262.0 |
| 93 | 巴比伦首富 | 乔治·克拉森 | 4.5 | 5694 | 129.0 |
from bokeh.transform import factor_cmap
from bokeh.models import Legend
from bokeh.palettes import Dark2_5 as palette
import itertools
from bokeh.palettes import d3
#colors has a list of colors which can be used in plots
colors = itertools.cycle(palette)
palette = d3['Category20'][20]
index_cmap = factor_cmap('Author', palette=palette, factors=data["Author"])
p = figure(plot_width=700, plot_height=700, title = "Top Authors: Rating vs. Customers Rated")
p.scatter('Rating', 'Customers_Rated', source=data, fill_alpha=0.6, fill_color=index_cmap, size=20, legend='Author')
p.xaxis.axis_label = 'RATING'
p.yaxis.axis_label = 'CUSTOMERS RATED'
p.legend.location = 'top_left'
BokehDeprecationWarning: 'legend' keyword is deprecated, use explicit 'legend_label', 'legend_field', or 'legend_group' keywords instead
show(p)
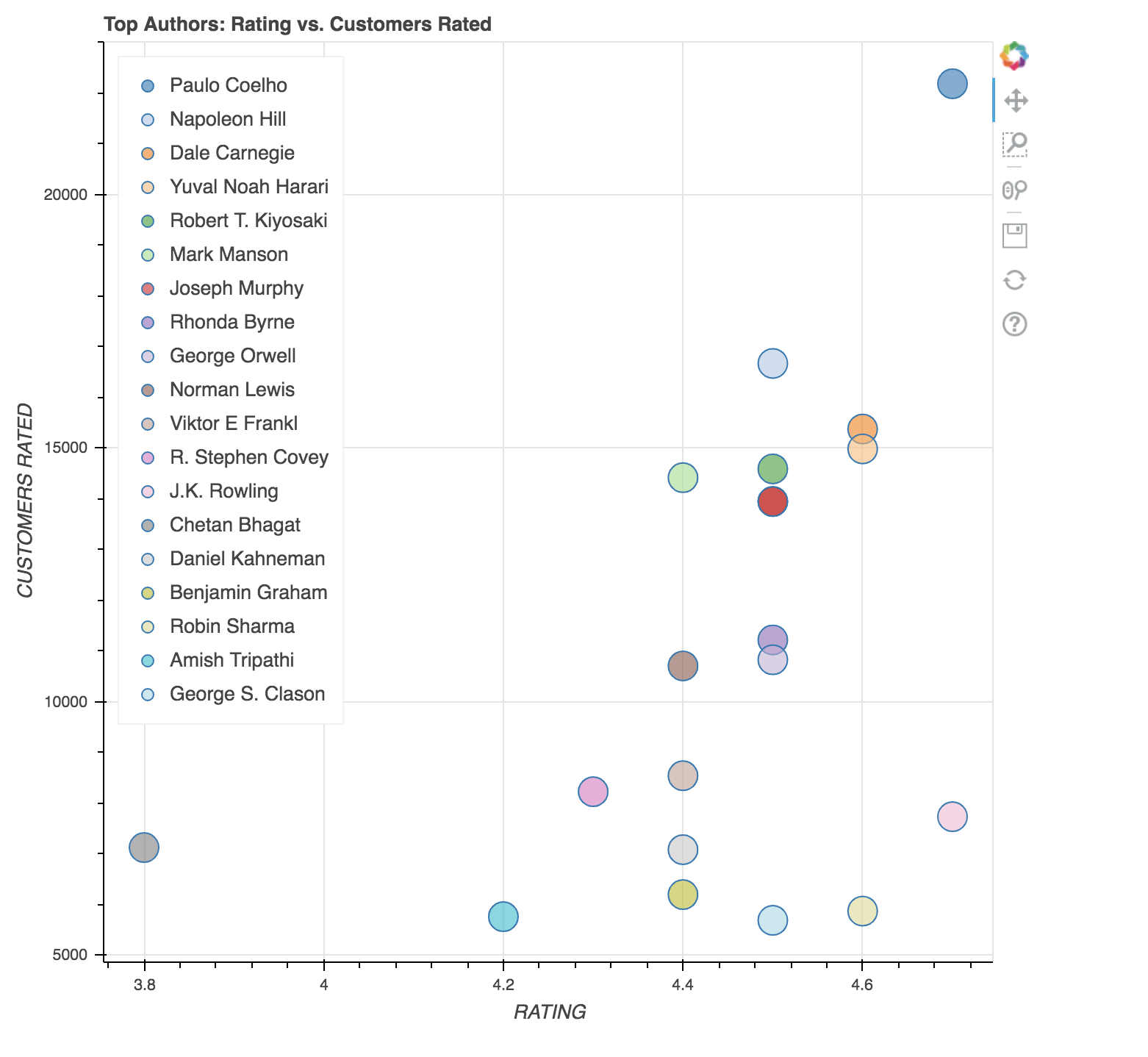
上图是散布了客户评价与实际评价的作者的散点图。查看上面的图可以得出以下结论。
- 放下Paulo Coelho的书《炼金术士》是自评级以来最畅销的书, 被评级的客户数量都保持同步。
- 作者阿米什·特里帕蒂(Amish Tripathi)的书《伊克什瓦库(Ram Chandra)的Ram-Scion》的评分为4.2, 顾客评分为5766。但是, 作者乔治·克拉森(George S. Clason)的《巴比伦首富》一书几乎获得了类似的客户评价, 但总体评价为4.5。因此, 可以得出结论, 更多的顾客对巴比伦的首富给予了很高的评价。
恭喜你完成了本教程。
本教程是对用Beautiful Soup进行网络抓取的基本介绍, 以及如何通过使用bokeh绘图库对网络中提取的信息进行可视化处理, 从而使它们有意义。在学习使用Beautiful Soup进行网页抓取方面迈出的一步, 一个很好的练习是从其他一些网站抓取数据, 看看如何从中获得见解。
如果你刚刚开始使用Python, 并且想了解更多信息, 请参加srcmini的Python数据科学入门课程。
评论前必须登录!
注册