 srcmini
srcmini本文概述
能够创建易于理解但复杂的图对于成为成功的数据科学家至关重要。创建可视化效果是在数据中讲述潜在故事的好方法。它突出显示了数据中的关系, 并揭示了人眼可见的信息, 这些信息不能仅用数字和数字来传达。但是你知道什么比可视化更好的数据分析吗?交互式可视化!
不幸的是, 作为一个新手, 这似乎是一项艰巨的任务。 Python和R都提供了广泛的工具和技巧来帮助你完成任务。在本教程中, 我们将向你介绍Altair。使用Altair, 你将能够在短时间内用几行代码来创建有意义, 优雅且有效的可视化。因此, 让我们开始吧!
- 什么是Altair?
- 还有另一个可视化库?不要想!你将在本节中学习命令式VS声明式API。
- 然后, 我们将安装Altair并加载Movies数据集
- 然后, 你将了解Altair中的一些基本概念, 例如图表, 标记和编码, 以进行一些很酷的可视化。
什么是Altair?
Altair是专为统计可视化设计的Python库。它本质上是声明性的(稍后我们将介绍该定义)。它基于Vega和Vega-Lite, 它们都是可视化语法, 可让你以JSON格式描述可视化的外观和交互行为。
命令式与声明式API
如前所述, Python已经为你提供了一系列出色的工具和库, 可用于数据可视化, 甚至还支持交互式可视化。但是, 什么使Altair脱颖而出?
答案在于与其他命令性API相比, 其声明性。
使用命令式API, 你需要将注意力集中在”如何做某事”而不是”你想做什么”上。你将不得不更多地考虑创建可视化所需的代码, 并手动指定绘图步骤-轴限制, 大小, 旋转, 图例等。
作为数据科学家, Altair可以让你将时间集中在精力上, 并把更多的精力放在数据上-了解, 分析和可视化数据, 而不是执行此操作所需的代码。这意味着你可以定义你希望看到的数据和输出(最终可视化效果如何), Altair会为你自动进行必要的操作。
安装
在本教程中, 我们将使用Vega数据集中的示例数据集。要安装Altier以及Vega数据集, 请在控制台窗口中键入以下内容:
$ pip install altair vega_datasets
如果你使用的是conda软件包管理器, 则等效为:
$ conda install -c conda-forge altair vega_datasets
之后, 你可以继续使用Jupyter Notebook, 然后导入Altair以开始使用。要了解有关Jupyter Notebook的更多信息, 请务必查看srcmini的Jupyter Notebook权威指南。
数据
现在, 我们已经将Altair和Vega数据集一起安装, 是时候加载一些数据了。从以下导入开始:
import pandas as pd
import altair as alt
为什么要导入Pandas?
因为Altair中的数据是围绕Pandas DataFrame构建的, 所以这意味着你可以像处理Pandas DataFrame一样处理Altair中的数据。
尽管Altair在内部以Pandas DataFrame的格式存储数据, 但是有多种输入数据的方式:
- 作为Pandas数据框
- 作为数据或相关对象(即UrlData, InlineData, NamedData)
- 作为指向JSON或CSV格式的文本文件的URL字符串
- 作为支持geo_interface的对象(例如Geopandas GeoDataFrame, Shapely Geometries, GeoJSON对象)
电影数据集
在本教程中, 我们将使用Vega数据集中的Movies数据集。与电影相关的此数据集或类似数据集在数据科学界非常有名, 特别是在”推荐引擎”的背景下。但是, 我们将仅使用Altair可视化对其执行数据分析。
数据集包含与电影有关的信息, 例如电影的标题, 电影在美国和全球的总收入, 制作预算, 体裁, IMDB和烂番茄的收视率。我们不会处理所有的列, 而只会使用其中的一些来了解有关Altair作为可视化工具的功能的更多信息。
让我们继续前进, 获取数据集并执行一些简单的分析以更好地理解它。
# Importing the Vega Dataset
from vega_datasets import data as vega_data
movies_df = pd.read_json(vega_data.movies.url)
# Checking the type of data that we get
print("movies_df is of the type: ", type(movies_df))
print("movies_df: ", movies_df.shape)
movies_df is of the type: <class 'pandas.core.frame.DataFrame'>
movies_df: (3201, 16)
如你所见, movies_df实际上是一个PandasDataFrame, 具有3201个电影(行), 每个电影有16个功能信息(列)。让我们检查一下数据框中的数据。
movies_df.head(5)
| Title | US_Gross | Worldwide_Gross | US_DVD_Sales | Production_Budget | Release_Date | MPAA_Rating | Running_Time_min | Distributor | Source | Major_Genre | Creative_Type | Director | Rotten_Tomatoes_Rating | IMDB_Rating | IMDB_Votes | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 土地女孩 | 146083.0 | 146083.0 | NaN | 8000000.0 | 1998年6月12日 | R | NaN | Gramercy | None | None | None | None | NaN | 6.1 | 1071.0 |
| 1 | 初恋, 最后礼仪 | 10876.0 | 10876.0 | NaN | 300000.0 | 1998年8月7日 | R | NaN | Strand | None | Drama | None | None | NaN | 6.9 | 207.0 |
| 2 | 我嫁给一个陌生人 | 203134.0 | 203134.0 | NaN | 250000.0 | 1998年8月28日 | None | NaN | Lionsgate | None | Comedy | None | None | NaN | 6.8 | 865.0 |
| 3 | 让我们谈谈性 | 373615.0 | 373615.0 | NaN | 300000.0 | 1998年9月11日 | None | NaN | Fine Line | None | Comedy | None | None | 13.0 | NaN | NaN |
| 4 | 大满贯 | 1009819.0 | 1087521.0 | NaN | 1000000.0 | 1998年10月9日 | R | NaN | Trimark | 原创剧本 | Drama | 当代小说 | None | 62.0 | 3.4 | 165.0 |
列值是:
movies_df.columns
Index(['Title', 'US_Gross', 'Worldwide_Gross', 'US_DVD_Sales', 'Production_Budget', 'Release_Date', 'MPAA_Rating', 'Running_Time_min', 'Distributor', 'Source', 'Major_Genre', 'Creative_Type', 'Director', 'Rotten_Tomatoes_Rating', 'IMDB_Rating', 'IMDB_Votes'], dtype='object')
现在, 我们将在pandas中使用to_datetime函数将Release_Date列转换为真实日期, 然后从中提取” year”值。稍后, 我们将在可视化中使用这个新创建的列。
def extract_year(value):
return pd.to_datetime(value, format='%b %d %Y').year
movies_df["Year"] = movies_df["Release_Date"].apply(extract_year)
如果现在检查列值, 你将看到一个名为Year的新列, 其中包含相应电影的年份值。
movies_df.columns
Index(['Title', 'US_Gross', 'Worldwide_Gross', 'US_DVD_Sales', 'Production_Budget', 'Release_Date', 'MPAA_Rating', 'Running_Time_min', 'Distributor', 'Source', 'Major_Genre', 'Creative_Type', 'Director', 'Rotten_Tomatoes_Rating', 'IMDB_Rating', 'IMDB_Votes', 'Year'], dtype='object')
现在, 我们将继续创建一些图。但是在执行此操作之前, 请运行以下代码:
alt.renderers.enable('notebook')
RendererRegistry.enable('notebook')
上面的代码所做的是, 它允许Altair在Jupyter笔记本中内联渲染, 因此我们可以看到我们开发的图形。如果遇到更多问题, 请查看Altair的故障排除页面。
首先查看数据, 很有趣的是看电影制作多少钱(Production_Budget)和电影实际赚多少钱(Worldwide_Gross)之间的关系。我们将在X和Y轴上绘制这些值。
但是, 数据集相对较大-鉴于我们的重点是与Altair一起玩。因此, 目前, 我们将仅处理几个数据点。让我们在数据集中检查给定年份的电影数量, 然后选择我们要关注的年份。
movies_df["Year"].value_counts()
2006 220
2005 210
2002 208
2004 192
2000 188
...
1943 1
2015 1
2027 1
2037 1
1928 1
Name: Year, Length: 91, dtype: int64
让我们将重点放在2000年, 并制作一个仅包含今年数据的新数据帧movie_2000。它应该包含188行(电影)。
movies_2000 = movies_df[movies_df["Year"] == 2000]
movies_2000.shape
(188, 17)
现在, 我们将朝着第一个可视化方向努力。让我们更深入地了解Altair的格式。
图表
图表是Altair中的基本对象, 它接受一个参数-数据框。我们定义图表的方式如下:
alt.Chart(DataFrame)
但就其本身而言, 该图表除了指定你要使用的数据然后在你需要提供该数据下一步要做什么之后, 不会做很多事情。这是我们使用标记的地方。
分数
通过mark属性, 可以指定如何在绘图上表示数据。以下是Altair提供的基本标记属性:

对于mark属性, 我们希望将dataFrame中的每个值标记为绘图中的一个点(圆)。因此, 我们将编写:
alt.Chart(DataFrame).mark_point()
编码方式
有了数据及其表示方式后, 我们想指定表示位置。也就是说, 设置位置, 大小, 颜色等。这是我们使用编码的地方。因此, 我们有:
alt.Chart(DataFrame).mark_point().encode()
将所有这些放在一起并添加细节以进行我们的第一个可视化:
alt.Chart(movies_2000).mark_point().encode(
alt.X('Production_Budget'), alt.Y('Worldwide_Gross')
)
<vega.vegalite.VegaLite at 0x11709a1d0>

那不是很好吗?我们不必做太多的事情-我们熟悉一些术语并将它们放在一起。现在, 我们有了一个图, 可以看到数据集中花费的金额与2000年电影的总收入的比值。
让我们使该图更有趣。与其将所有点都标记为相同的圆大小, 不如让它们的指针与相应的US_Gross一样大(或小)。为此, 我们引入了大小功能。因此, 圆圈指针的大小越大, 他们在美国的票房收入就越大。让我们也给圆圈指针上色, 而不仅仅是画轮廓。为此, 我们将在mark_point()属性中添加一个参数。
alt.Chart(movies_2000).mark_point(filled=True).encode(
alt.X('Production_Budget'), alt.Y('Worldwide_Gross'), alt.Size('US_Gross')
)
<vega.vegalite.VegaLite at 0x117cce790>

现在, 我们有一个图, 仅用四行来描述每部电影的预算。少了什么东西?颜色!
但是, 我们不只是为了添加随机颜色!通过引入关于数据集Major_Genre的另一条信息, 我们将使图保持有趣。我们将使用”颜色”功能为电影的每种流派赋予自己的颜色, 并使用OpacityValue为该颜色添加一些透明度。
alt.Chart(movies_2000).mark_point(filled=True).encode(
alt.X('Production_Budget'), alt.Y('Worldwide_Gross'), alt.Size('US_Gross'), alt.Color('Major_Genre'), alt.OpacityValue(0.7)
)
<vega.vegalite.VegaLite at 0x118e3ff50>

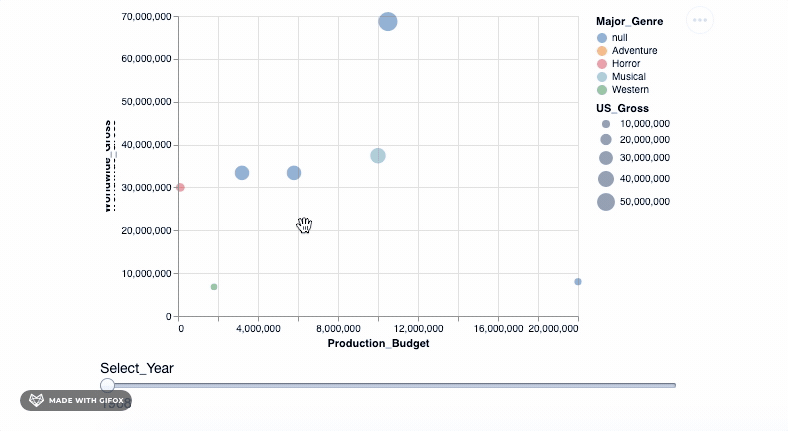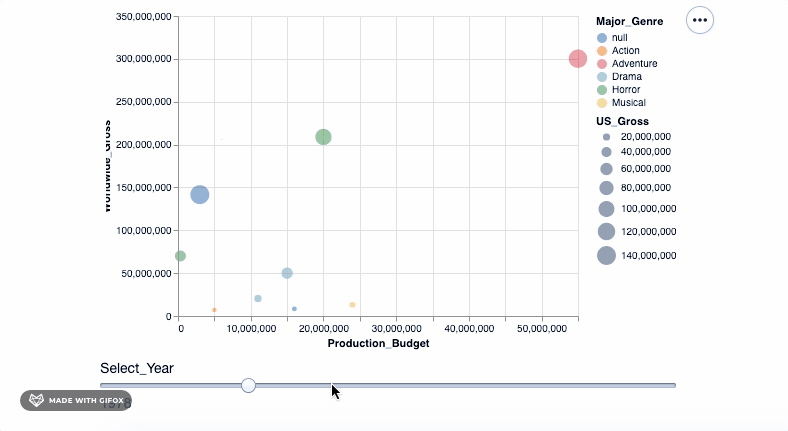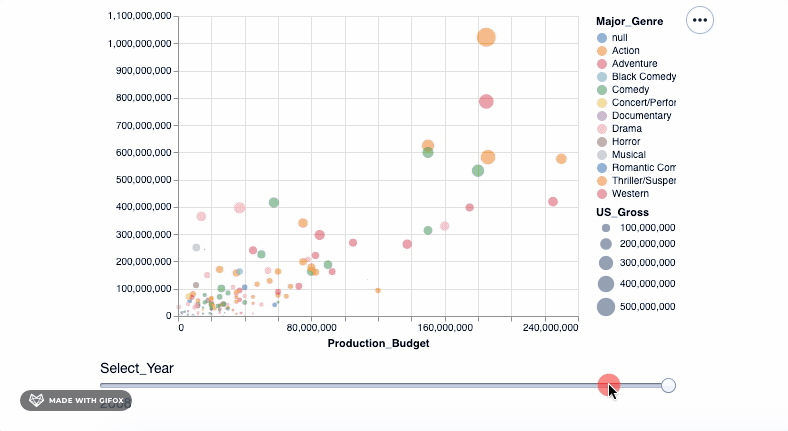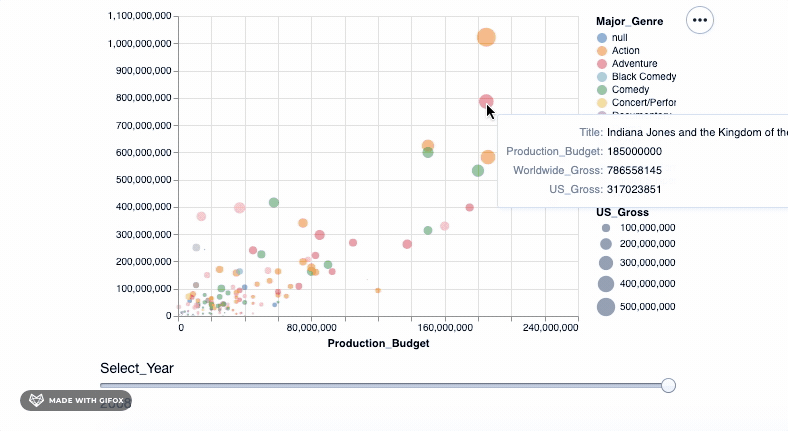
这已经很好, 但还不够好!如果我们可以在情节中移动并查看数据点所代表的电影的详细信息, 那就太好了。工具提示可让我们做到这一点…
alt.Chart(movies_2000).mark_point(filled=True).encode(
alt.X('Production_Budget'), alt.Y('Worldwide_Gross'), alt.Size('US_Gross'), alt.Color('Major_Genre'), alt.OpacityValue(0.7), tooltip = [alt.Tooltip('Title'), alt.Tooltip('Production_Budget'), alt.Tooltip('Worldwide_Gross'), alt.Tooltip('US_Gross')
]
)
<vega.vegalite.VegaLite at 0x118e3ff90>
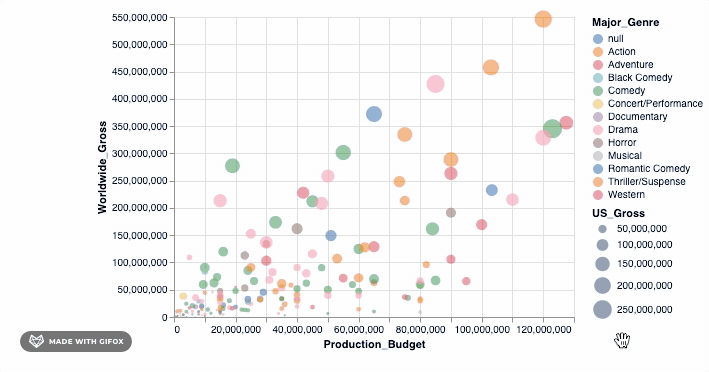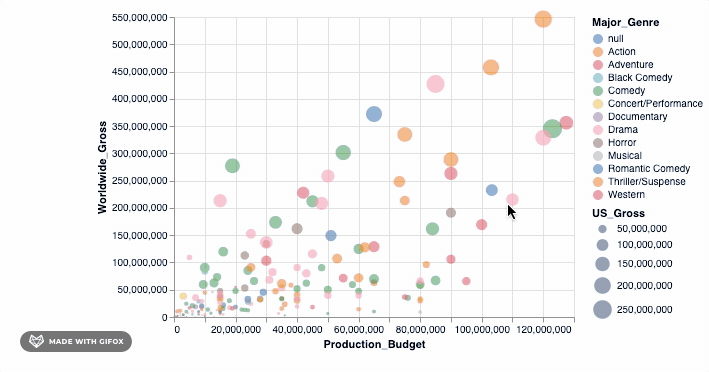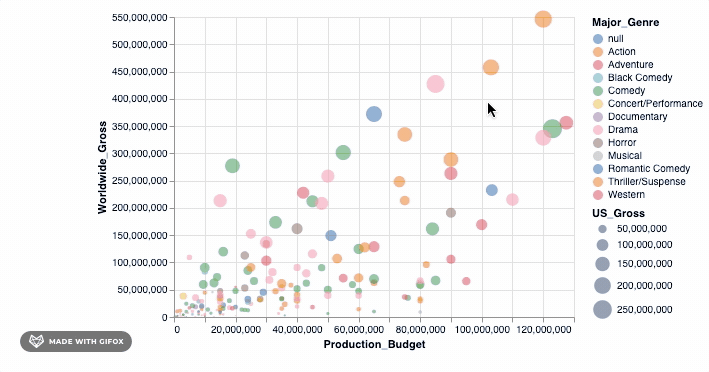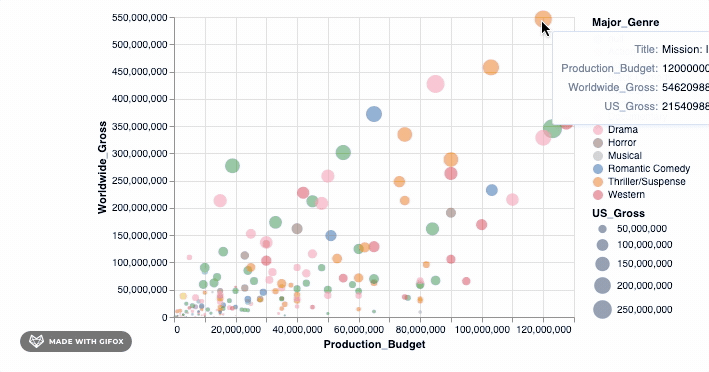
那不是很酷吗?但是, 等等, 让我们做更多。还记得为什么我们要首先使用Altair吗?这样我们就可以进行交互式可视化。当你在数据点上悬停时, 工具提示已经引入了一些交互。但是, 让我们向已经拥有的功能中添加一个简单的interact()功能。
alt.Chart(movies_2000).mark_point(filled=True).encode(
alt.X('Production_Budget'), alt.Y('Worldwide_Gross'), alt.Size('US_Gross'), alt.Color('Major_Genre'), alt.OpacityValue(0.7), tooltip = [alt.Tooltip('Title'), alt.Tooltip('Production_Budget'), alt.Tooltip('Worldwide_Gross'), alt.Tooltip('US_Gross')
]
).interactive()
<vega.vegalite.VegaLite at 0x118e3c750>
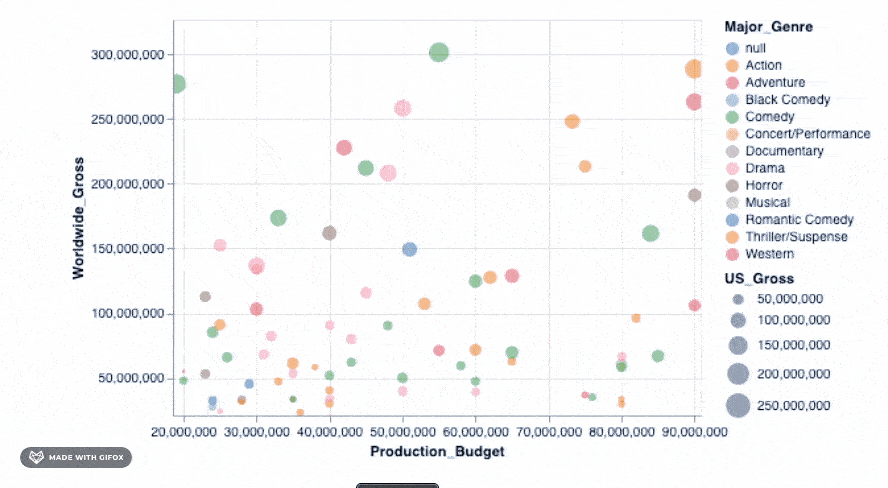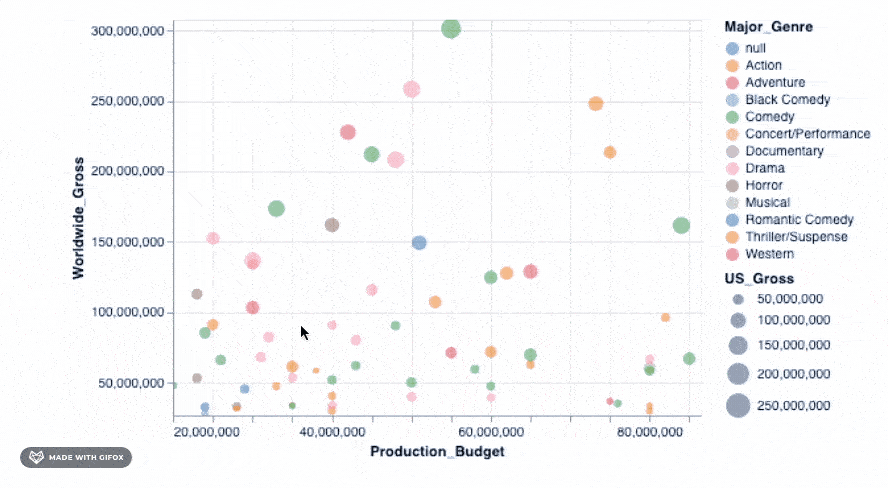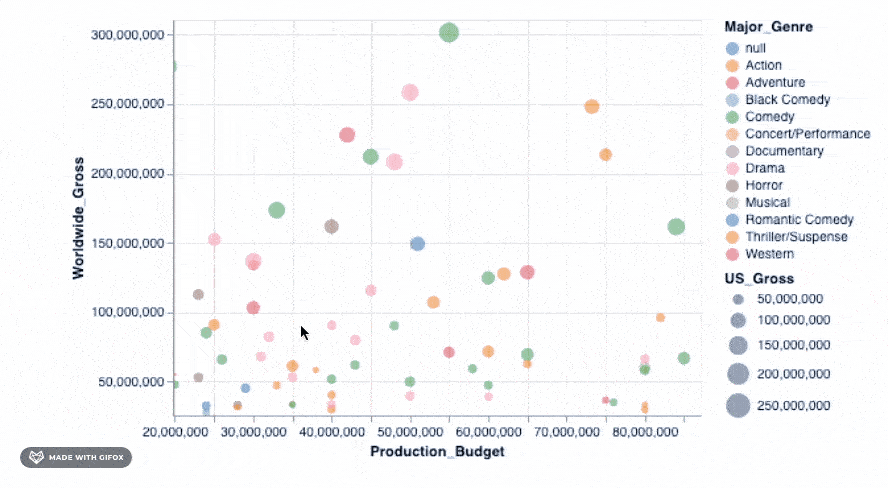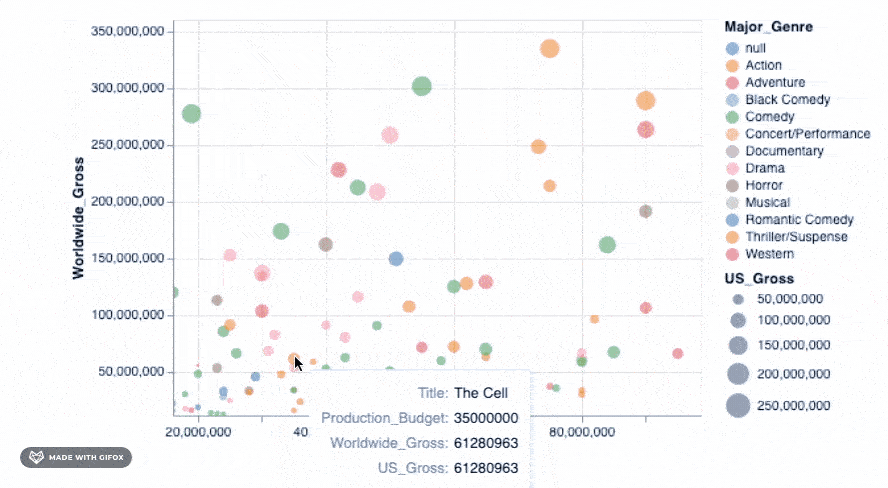
添加该简单的代码段即可使你放大到特定区域-自动固定轴值, 以便你可以专注于感兴趣的特定区域。但是, 你可以将许多更高级的交互式功能添加到图形中。我们可以检查其中之一…
我们终于有了一个不错的阴谋来展示我们的数据。让我们引入所有数据点并将它们放入我们的图形中。但是, 等等, 你是否认为将所有数据点放在一个可视化文件中太多了。另外, 我们绝对希望根据之前创建的Year值将它们分开。为此, 我们将使用高级选择属性。
select_year = alt.selection_single(
name='Select', fields=['Year'], init={'Year': 1928}, bind=alt.binding_range(min=1928, max=2046, step=10)
)
alt.Chart(movies_df).mark_point(filled=True).encode(
alt.X('Production_Budget'), alt.Y('Worldwide_Gross'), alt.Size('US_Gross'), alt.Color('Major_Genre'), alt.OpacityValue(0.7), tooltip = [alt.Tooltip('Title:N'), alt.Tooltip('Production_Budget:Q'), alt.Tooltip('Worldwide_Gross:Q'), alt.Tooltip('US_Gross:Q')
]
).add_selection(select_year).transform_filter(select_year)
<vega.vegalite.VegaLite at 0x117cd4cd0>
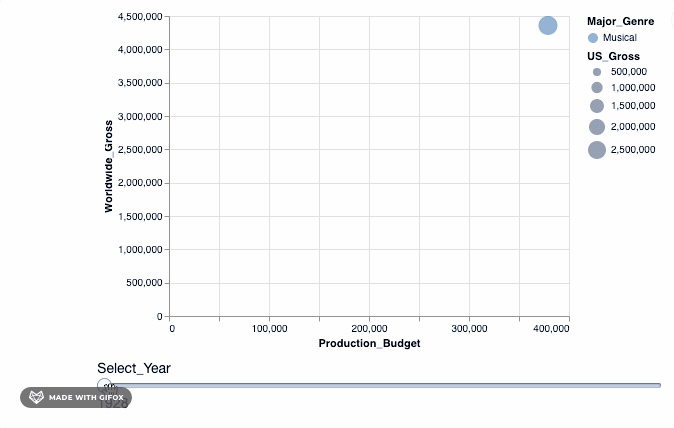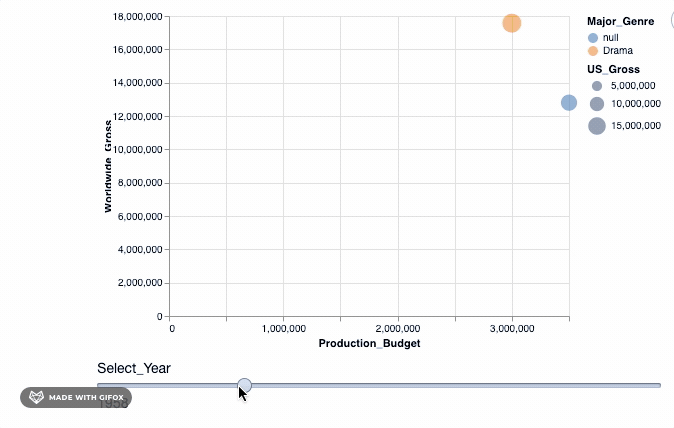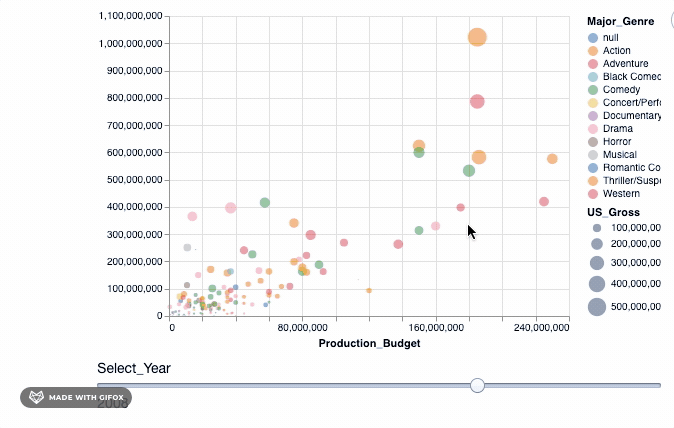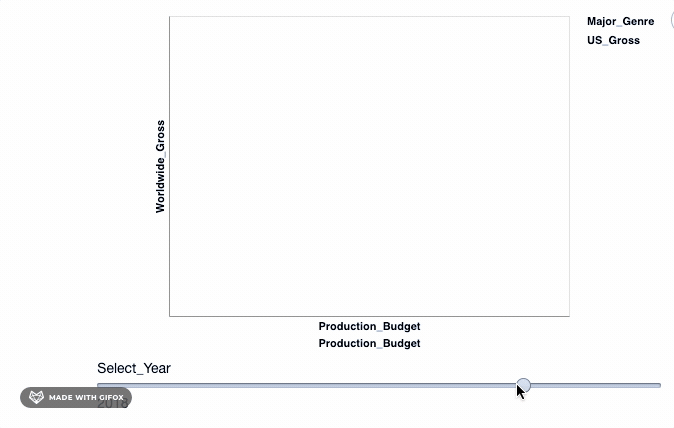
因此, 我们使用add_selection属性将select_year作为单一选择功能引入到绘图中, 然后再应用transform_filter()将转换实际应用于绘图中。
你是否注意到了代码的另一个新增加?工具提示中的” Q”和” N”。这是为了指定数据类型:N-名义(类别数据), Q-定量(数值数据), O-有序(有序数据)或T时态(时间点或间隔)。
在数据集中检查最旧和最新的年份。
print("The oldest year is: ", movies_df["Year"].min())
print("The latest year is: ", movies_df["Year"].max())
The oldest year is: 1928
The latest year is: 2046
如你所见, 当你拖动” Select_Year”栏时, 在1928年至1967年之间放映的电影并不多。而且在2018年以后(当然直到2046年)都没有记录任何电影数据。我们可以使用binding_range( )属性, 以指定年份范围以及年份步长。
在现实生活的项目中, 这样的发现很重要, 并且可能指向数据收集阶段或过程中某处的错误。你将需要有效地处理错误。这是数据预处理期间的重要步骤。查看Pandas数据准备, 以获取这些重要步骤的介绍。
让我们调整年份, 并以此完成最终的可视化…
select_year = alt.selection_single(
name='Select', fields=['Year'], init={'Year': 1968}, bind=alt.binding_range(min=1968, max=2008, step=10)
)
alt.Chart(movies_df).mark_point(filled=True).encode(
alt.X('Production_Budget'), alt.Y('Worldwide_Gross'), alt.Size('US_Gross'), alt.Color('Major_Genre'), alt.OpacityValue(0.7), tooltip = [alt.Tooltip('Title:N'), alt.Tooltip('Production_Budget:Q'), alt.Tooltip('Worldwide_Gross:Q'), alt.Tooltip('US_Gross:Q')
]
).add_selection(select_year).transform_filter(select_year)
<vega.vegalite.VegaLite at 0x1180cda10>
在本教程中, 向你介绍了Altair。你了解了如何用几行代码来创建漂亮的交互式图表, 以帮助你更有效地在数据中讲述故事。本教程希望展示Altair的力量和潜力。要了解有关Altair的更多信息, 请访问其官方网站。
评论前必须登录!
注册