 srcmini
srcmini本文概述
假设你需要数字化书本或印刷文档的页面, 你将使用扫描仪创建真实页面的图像。但是, 尽管你有权编辑扫描书的内容, 但是由于它是图像, 因此无法在计算机中对其进行编辑, 并且不能像将其视为数字文档一样简单地对其进行编辑。是的, 用户可以使用创建带有可选文本的PDF的程序, 然后他们可以执行所需的操作, 但是作为开发人员, 你可以为用户提供使用光学字符识别技术从图像中提取文本的可能性。为了实现将图像转换为文本的目标, 我们将使用用C ++编写的Tesseract, 将其安装在系统中, 然后将命令行与PHP包装器一起使用。
在本文中, 你将学习如何在Tesseract的帮助下从Symfony项目中的图像中提取文本。
1.在你的系统中安装Tesseract
如本文所述, 为了使用光学字符识别API, 我们将使用Tesseract。 Tesseract是一个开放源代码的光学字符识别(OCR)引擎, 可以通过Apache 2.0许可获得。它可以直接通过API使用, 以从图像中提取打字, 手写或打印的文本。它支持多种语言(需要安装)。 Tesseract支持多种输出格式:纯文本, hocr(html)和pdf。
根据你使用的操作系统, Tesseract在系统中的安装过程会有所不同:
视窗
Windows中Tesseract的安装非常简单, 我们建议你使用此处Wiki中提到的非官方安装程序(tesseract-ocr-setup- <version> .exe)。你可以在tesseract的官方网站上获得所有可用设置的列表(始终下载最新版本)。
安装过程非常简单, 只需遵循向导即可。但是, 我们建议你直接在安装程序中安装tesseract所需的所有语言(仅安装所需的语言, 否则下载过程将花费很长时间), 然后在PATH中注册tesseract:
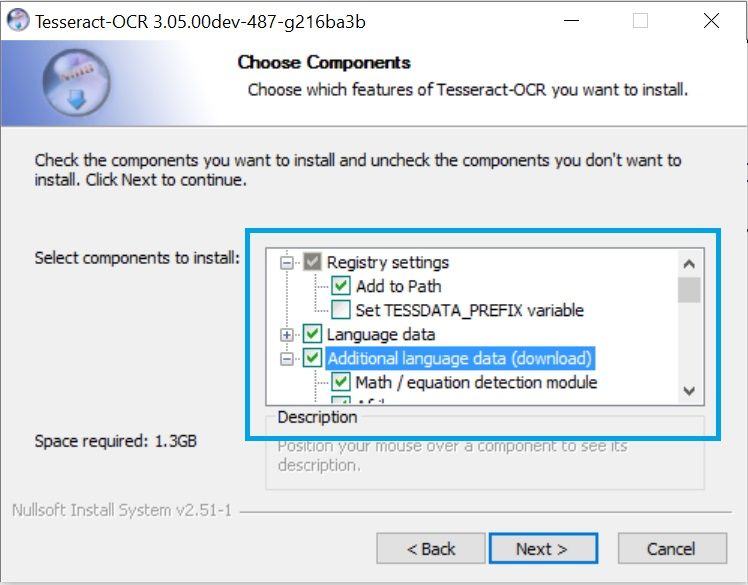
等待安装完成, 你就可以开始了。你可以在新的命令提示符窗口tesseract -v(应该输出已安装的版本)中执行测试, 以确定它是否已正确安装。
的Ubuntu
使用以下命令安装Tesseract:
sudo apt-get install tesseract-ocr然后, 安装你需要识别的语言(例如, 需要-deu, -fra, -eng和-spa english):
sudo apt-get install tesseract-ocr-eng然后tesseract应该在任何终端上都可用, 因此以后我们的PHP脚本即可使用。
苹果系统
如果你使用的是Mac OS X, 则可以使用MacPorts或Homebrew安装tesseract:
MacPorts
要安装Tesseract, 请运行以下命令:
sudo port install tesseract要安装任何语言数据, 请执行:
sudo port install tesseract-<langcode>可在MacPorts tesseract页面上找到可用语言代码的完整列表。
家酿
要安装Tesseract, 请运行以下命令:
brew install tesseract如果你需要更多信息或未列出你的操作系统, 请在此处参考Github中Tesseract信息库的Installation Wiki。
2.安装Tesseract PHP包装器
为了使用PHP处理Tesseract, 我们将使用@thiagoalessio编写的最著名的Tesseract包装器。 Tesseract OCR for PHP是PHP内Tesseract OCR命令行说明的有用且非常易于使用的包装。
首选的安装方式是通过composer, 你可以直接在终端中执行以下命令:
composer require thiagoalessio/tesseract_ocr 1.0.0-RC或者, 如果需要, 编辑composer.json文件并添加以下依赖项并执行, 然后执行composer install:
{
"require": {
"thiagoalessio/tesseract_ocr": "1.0.0-RC", }
}
安装后, 你将可以在symfony控制器中使用Wrapper。
注意:你需要按照库文档中的说明安装指定的版本, 使用Tesseract识别图像中文本的方法是$ tesseract-> run()。在旧版本中, 你需要使用$ tesseract-> recognize()。
3.控制器内的实现
该库的用法非常简单且易于理解:
<?php
// Include the Tesseract Wrapper
use TesseractOCR;
// or without using the use statement
// $tesseractInstance = new \TesseractOCR($filepath);
// Absolute or relative path to the image to recognize
$filepath = "image-to-recognize.jpeg";
// Create an instanceof tesseract with the filepath as first parameter
$tesseractInstance = new TesseractOCR($filepath);
// Execute tesseract to recognize text
$result = $tesseractInstance->run();
// Show recognized text
echo $result;下面的示例演示如何识别下图的文本:

请注意, 该文件位于/your-project/web/text.jpeg中:
<?php
namespace myBundle\Controller;
use Symfony\Bundle\FrameworkBundle\Controller\Controller;
use Symfony\Component\HttpFoundation\Response;
// Include the Tesseract Wrapper
use TesseractOCR;
class DefaultController extends Controller
{
public function indexAction()
{
// Retrieve the webpath in symfony
$webPath = $this->get('kernel')->getRootDir().'/../web/';
// The filename of the image is text.jpeg and is located inside the web folder
$filepath = $webPath.'text.jpeg';
// Is useful to verify if the file exists, because the tesseract wrapper
// will throw an error but without description
if(!file_exists($filepath)){
return new Response("Warning: the providen file [".$filepath."] doesn't exists.");
}
// Create a new instance of tesseract and provide as first parameter
// the local path of the image
$tesseractInstance = new TesseractOCR($filepath);
// Execute tesseract to recognize text
$result = $tesseractInstance->run();
// Return the recognized text as response (expected: The quick brown fox jumps over the lazy dog.)
return new Response($result);
}
}
导航到与该控制器的索引操作匹配的路由, 你将在输出中看到图像的识别文本。
4.支持语言
如你所知, 世界上还有其他使用特殊字符的语言, 这就是Tesseract提供不同语言包的原因。例如, 如果你尝试在没有德语包的情况下识别以下图像:

你将得到结果”抱怨”。根本不是真的, 这是因为这些字符是德语。要解决此问题, 你需要添加德语包(以deu标识):
<?php
// Create a new instance of tesseract and provide as first parameter
// the local path of the image
$tesseractInstance = new TesseractOCR("image.jpeg");
// Set the german language, note that it needs to be installed
$tesseractInstance->lang("deu");
// Execute tesseract to recognize text
$result = $tesseractInstance->run();
echo $result;现在, 作为结果, 你应该会按预期获得”grüßen”。你可以设置提供多种参数的多种语言同时运行:
$tesseractInstance->lang("deu", "spa", "por");注意:为了使用不同的语言, 你还需要安装相应的软件包。
5.自定义选项
如果你已经通过命令行阅读了Tesseract用法文档的某些内容, 那么你将知道可以更改许多属性。 tesseract的PHP包装器为最常用的选项提供了一些方法:
更改可执行路径
由于不同的原因, 你可能没有直接在环境变量PATH中使用tesseract, 因此, 用php包装器” tesseract imagename.jpeg outputbase”执行命令将无效。你可以使用可执行方法指定tesseract可执行文件的位置:
$tsaInstance = new TesseractOCR("image.jpeg");
// For example in Windows, you need to wrapp the path in double quotes to make it work.
$executablePath = '"C:/Program Files (x86)/Tesseract-OCR/tesseract.exe"';
$tsaInstance->executable($executablePath);
$recognized = $tsaInstance->run();页面细分
你可以使用-> psm($ mode)指令设置页面的分割模式, 该指令指示tesseract如何解释给定的图像:
$tsaInstance = new TesseractOCR("image.jpeg");
$tsaInstance->psm(1);
$recognized = $tsaInstance->run();页面细分的可能值为:
| 值 | 描述 |
| 0 | 仅方向和脚本检测(OSD)。 |
| 1 | OSD自动页面分割。 |
| 2 | 自动页面分割, 但没有OSD或OCR。 |
| 3 | 全自动页面分割, 但没有OSD。 (如果没有providen, 则默认使用此值) |
| 4 | 假设一列可变大小的文本。 |
| 5 | 假定单个统一的垂直对齐文本块。 |
| 6 | 假设一个统一的文本块。 |
| 7 | 将图像视为单个文本行。 |
| 8 | 将图像视为一个单词。 |
| 9 | 将图像视为一个圆圈中的单个单词。 |
| 10 | 将图像视为单个字符。 |
设置语言以识别
你可以使用-> lang($ lang1, $ lang2)方法定义识别期间要使用的一种或多种语言。你可以在以下文档中找到tesseract支持的所有语言的列表:
$tsaInstance = new TesseractOCR("image.jpeg");
// To provide full chinese recognition
$tsaInstance->lang('chi_sim', 'chi_tra');
$recognized = $tsaInstance->run();使用列表中的单词
你可以提供一个列表。该列表必须是纯文本文件, 其中包含你希望tesseract将其视为普通词典单词的单词列表, 例如(mywords.txt):
jargon
artyom.js
recognition并使用包装器将其添加:
$tsaInstance = new TesseractOCR("image.jpeg");
// Custom words
$tsaInstance->userWords('mywords.txt');
$recognized = $tsaInstance->run();当处理包含技术术语的内容时, 此列表非常有用。
白名单字符
你甚至可以限制tesseract可以识别的字符, 例如, 使用以下图像:
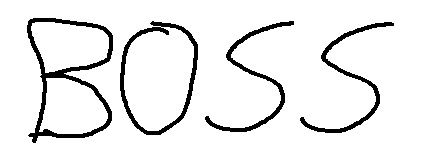
Tesseract将识别” BOSS”。太好了, 因为图像中似乎有人写了BOSS, 但是用户(可能是孩子或书法不佳的人)写了数字” 8055″?这就是白名单派上用场的地方, 在这种情况下, 我们可以限制字符以仅识别数字, 范围为0到9:
$tsaInstance = new TesseractOCR("image.jpeg");
// Recognize all in numbers
$tsaInstance->whitelist(range(0, 9));
$recognized = $tsaInstance->run();结果是期望的数字为” 8055″。
设置配置值
Tesseract提供了600多个可自定义的属性(你可以在控制台中使用tesseract –print-parameters列出它们), 可以使用-> config($ propertyName, $ value)进行修改:
$tsaInstance = new TesseractOCR("image.jpeg");
// Size of window for spline segmentation
$tsaInstance->config("textord_spline_medianwin", 6 );
// For smooth factor
$tsaInstance->config("textord_skewsmooth_offset", 3);
$recognized = $tsaInstance->run();如果你需要有关此包装器支持的方法的更多信息, 请在此处访问官方资源库。
编码愉快!
评论前必须登录!
注册