 srcmini
srcmini本文概述
免责声明
我们(我们的代码世界)或本模块的开发者在任何情况下均不对由于使用本模块或本模块下载的网页所造成的直接, 间接, 特殊或其他间接损失负责。需要你自担风险使用它。
而且, 就我们的免责声明而言, 我们不会谈论你的计算机将通过使用我们用于复制网站的模块而爆炸。我们仅警告该脚本不应用于非法活动(例如, 假冒网站并将其公开在另一个Web域中), 而应了解有关Node.js和Web开发的更多信息。
话虽这么说, 你是否曾经见过一个真棒的网站, 上面有一些你绝对想要拥有的真棒小工具或小部件, 或者你知道如何做, 但是你找不到能做到这一点的开源库?因为首先要做的是, 所以首先要寻找一个创建该超棒小工具的开源库, 如果存在, 请在你自己的项目中实现它。如果找不到, 则可以使用chrome dev工具检查该元素, 并从表面上看到它的工作方式以及如何自己创建它。但是, 如果你不太幸运, 或者你没有通过开发工具复制功能的技能, 那么你仍然可以进行更改。

这比拥有完整的代码来创建令人敬畏的窗口小部件并根据需要进行编辑更好(这将有助于你了解窗口小部件的工作方式)。这正是你将要学习的内容, 即如何使用网络抓取工具通过带有Node.js的URL通过其URL下载整个网站。 Web抓取(也称为屏幕抓取, Web数据提取, Web收集等)是一种用于从网站提取大量数据的技术, 从而可以将数据提取并保存到计算机的本地文件或表(电子表格)的数据库中)格式。
要求
要从网站下载所有资源, 我们将使用website-scraper模块。该模块允许你将整个网站(或单个网页)下载到本地目录(包括所有资源css, 图像, js, 字体等)。
在终端中执行以下命令, 将模块安装到项目中:
npm install website-scraper注意
动态网站(由js加载内容的网站)可能未正确保存, 因为website-scraper不会执行js, 它只会解析html和css文件的http响应。
在此处访问官方的Github存储库以获取更多信息。
1.下载一页
scrape函数返回一个Promise, 该Promise向所有Providen URL发出请求, 并将与源一起找到的所有文件保存到目录中。资源将根据Providen目录路径中的资源类型(css, 图像或脚本)组织到文件夹中。以下脚本将下载node.js网站的主页:
const scrape = require('website-scraper');
let options = {
urls: ['https://nodejs.org/'], directory: './node-homepage', };
scrape(options).then((result) => {
console.log("Website succesfully downloaded");
}).catch((err) => {
console.log("An error ocurred", err);
});将先前的脚本保存在js文件(script.js)中, 然后使用节点index.js在节点上执行该脚本。脚本完成后, node-homepage文件夹的内容将为:
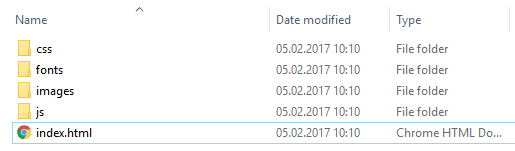
来自网络浏览器的index.html文件将如下所示:
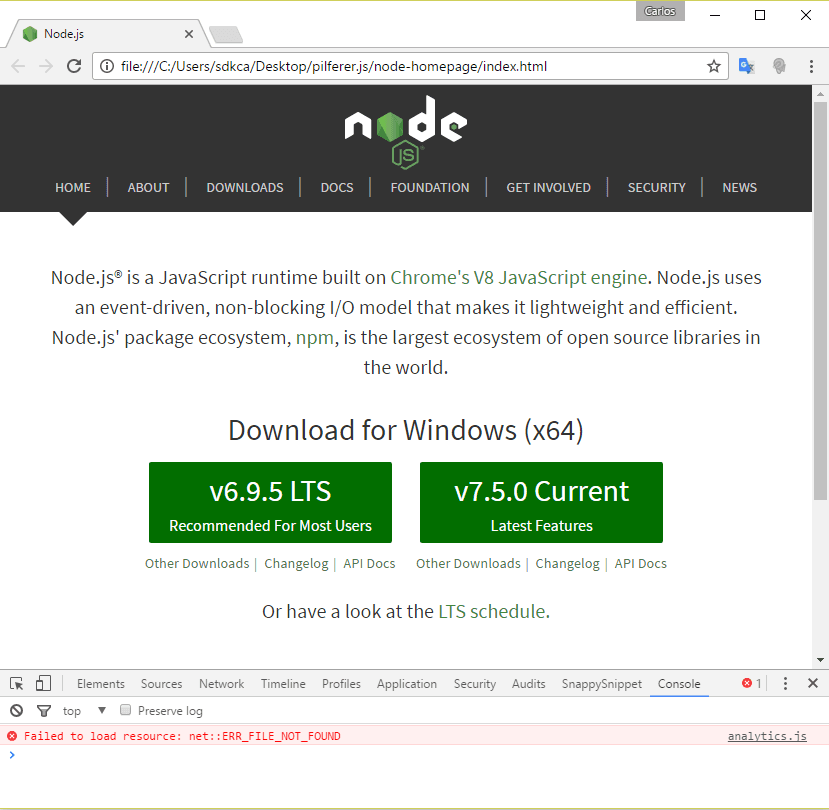
所有的脚本, 样式表均已下载, 并且网站的运作就像一个魅力。请注意, 控制台中显示的唯一错误是由于Google的分析脚本引起的, 你显然应该手动将其从代码中删除。
2.下载多个页面
如果要下载一个网站的多个页面, 则应在同一脚本中同时提供它们, scraper非常聪明, 可以知道不应两次下载资源(但前提是已经从同一网站下载了资源)在另一页中), 它将下载所有标记文件, 但不下载已存在的资源。
在此示例中, 我们将下载urls属性中指定的3页的node.js网站(索引, 关于和博客)。内容将保存在node-website文件夹(执行脚本的位置)中, 如果不存在, 则会创建该内容。为了更井井有条, 我们将分别手动将每种类型的资源分类在不同的文件夹中(图像, javascript, css和字体)。 sources属性指定要加载的对象数组, 指定选择器和属性值以选择要加载的文件。
如果你想要一些特定的网页, 此脚本很有用:
const scrape = require('website-scraper');
scrape({
urls: [
'https://nodejs.org/', // Will be saved with default filename 'index.html'
{
url: 'http://nodejs.org/about', filename: 'about.html'
}, {
url: 'http://blog.nodejs.org/', filename: 'blog.html'
}
], directory: './node-website', subdirectories: [
{
directory: 'img', extensions: ['.jpg', '.png', '.svg']
}, {
directory: 'js', extensions: ['.js']
}, {
directory: 'css', extensions: ['.css']
}, {
directory: 'fonts', extensions: ['.woff', '.ttf']
}
], sources: [
{
selector: 'img', attr: 'src'
}, {
selector: 'link[rel="stylesheet"]', attr: 'href'
}, {
selector: 'script', attr: 'src'
}
]
}).then(function (result) {
// Outputs HTML
// console.log(result);
console.log("Content succesfully downloaded");
}).catch(function (err) {
console.log(err);
});3.递归下载
想象一下, 你不需要网站中的特定网页, 而是网站中的所有页面。一种方法是使用先前的脚本并手动指定你可以下载的网站的每个URL, 但是这样做会适得其反, 因为这将花费大量时间, 并且你可能会忽略某些URL。这就是Scraper提供递归下载功能的原因, 该功能使你可以跟踪页面中的所有链接以及该页面中的链接, 等等。显然, 这将导致一个非常长(几乎是无限)的循环, 你可以使用最大允许深度(maxDepth属性)来限制该循环:
const scrape = require('website-scraper');
let options = {
urls: ['https://nodejs.org/'], directory: './node-homepage', // Enable recursive download
recursive: true, // Follow only the links from the first page (index)
// then the links from other pages won't be followed
maxDepth: 1
};
scrape(options).then((result) => {
console.log("Webpages succesfully downloaded");
}).catch((err) => {
console.log("An error ocurred", err);
});先前的脚本应下载更多页面:
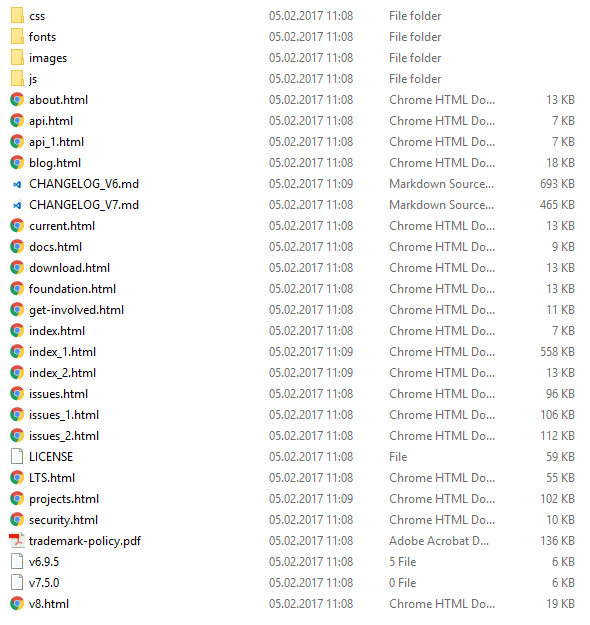
过滤外部URL
正如任何一种网站所预期的那样, 会有一些外部URL不属于你要复制的网站。为了防止那些页面也被下载, 你只能在URL与你使用的页面匹配时对其进行过滤:
const scrape = require('website-scraper');
const websiteUrl = 'https://nodejs.org';
let options = {
urls: [websiteUrl], directory: './node-homepage', // Enable recursive download
recursive: true, // Follow only the links from the first page (index)
// then the links from other pages won't be followed
maxDepth: 1, urlFilter: function(url){
// If url contains the domain of the website, then continue:
// https://nodejs.org with https://nodejs.org/en/example.html
if(url.indexOf(websiteUrl) === 0){
console.log(`URL ${url} matches ${websiteUrl}`);
return true;
}
return false;
}, };
scrape(options).then((result) => {
console.log("Webpages succesfully downloaded");
}).catch((err) => {
console.log("An error ocurred", err);
});在我们的示例中, 这应该减少下载页面的数量:
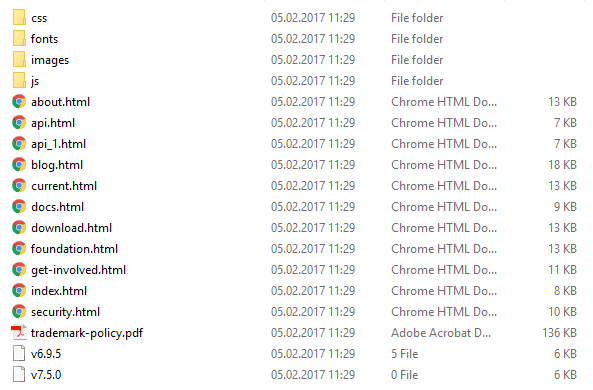
4.下载整个网站
注意
此任务需要很多时间, 因此请耐心等待。
如果要下载整个网站, 则可以使用递归下载模块并将最大允许深度增加到一个合理的数字(在此示例中, 使用50不太合理, 但是无论如何):
// Downloads all the crawlable files of example.com.
// The files are saved in the same structure as the structure of the website, by using the `bySiteStructure` filenameGenerator.
// Links to other websites are filtered out by the urlFilter
const scrape = require('website-scraper');
const websiteUrl = 'https://nodejs.org/';
scrape({
urls: [websiteUrl], urlFilter: function (url) {
return url.indexOf(websiteUrl) === 0;
}, recursive: true, maxDepth: 50, prettifyUrls: true, filenameGenerator: 'bySiteStructure', directory: './node-website'
}).then((data) => {
console.log("Entire website succesfully downloaded");
}).catch((err) => {
console.log("An error ocurred", err);
});最终建议
如果网站的CSS或JS代码已精简(可能全部都被精简了), 我们建议你对语言使用美化模式(cssbeautify用于css或js-beautify用于Javascript), 以便进行漂亮的打印和制作代码更具可读性(与原始代码的可读性不同, 但是可以接受)。
编码愉快!
评论前必须登录!
注册