 srcmini
srcmini到现在为止,我们学习了如何在Apache Kafka上读写数据。在本节中,我们将学习将真实数据源放入Kafka。
在这里,我们将讨论一个实时应用程序,即Twitter。用户将了解有关创建Twitter生产者以及如何产生Tweet的知识。
Twitter是一项社交网络服务,允许用户进行交互并发布消息。这些消息称为推文。 Twitter用户通过发帖和通过推文对不同帖子进行评论来进行交互。
要处理Twitter,我们需要获取Twitter应用程序的凭据。可以通过创建Twitter开发人员帐户来完成。这样做,请按照以下步骤操作:
步骤1:创建一个Twitter帐户(如果该帐户不存在)。
步骤2:在网络浏览器中打开“ developer.twitter.com”,如下所示:
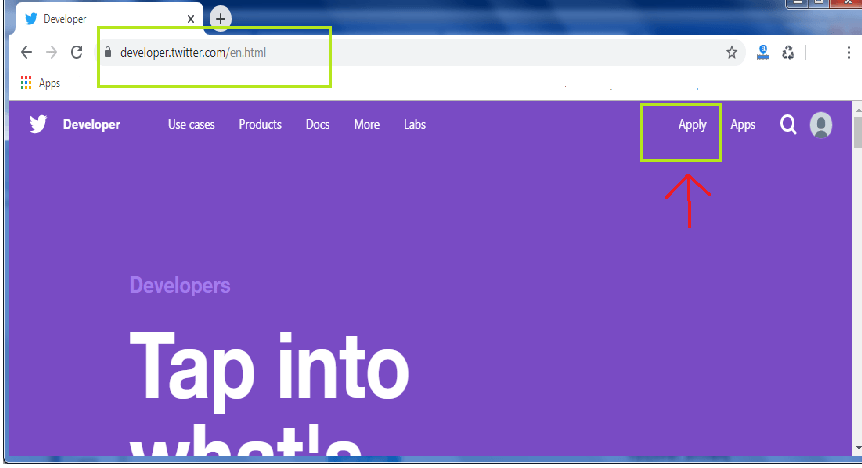
单击“应用”选项。
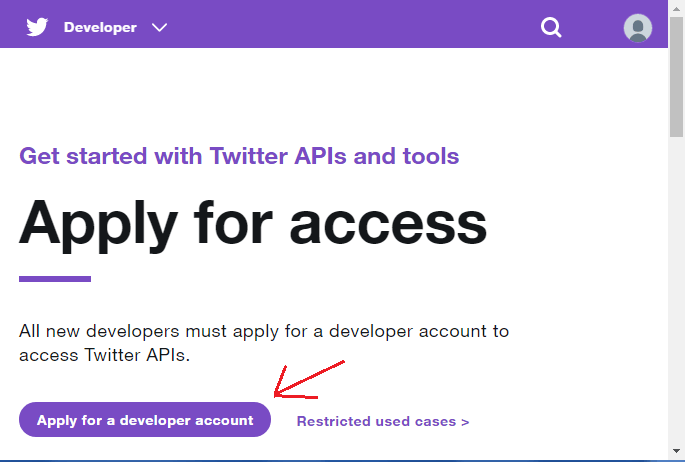
步骤3:将打开一个新页面。点击“申请开发者帐户”
步骤4:将打开一个新页面,询问预定用途,例如“如何使用Twitter数据?”,依此类推。快照如下所示:
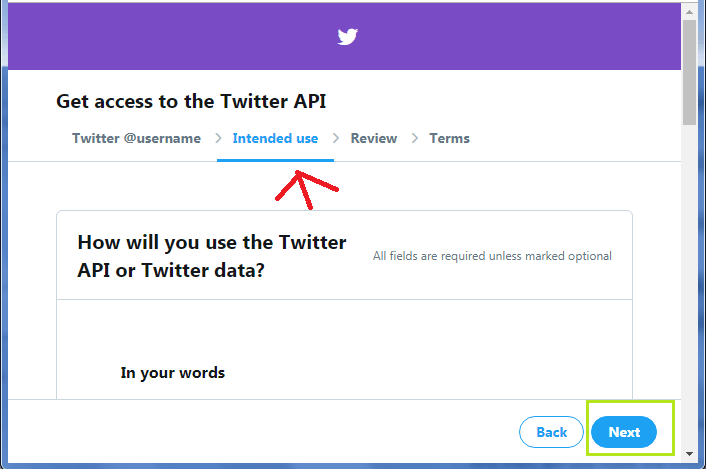
提供适当的答案后,单击“下一步”。
步骤5:下一部分是“评论”部分。在这里,用户说明将由Twitter查看,如下所示:

如果twitter找到合适的答案,将启用“看起来不错”选项。然后,移至下一部分。
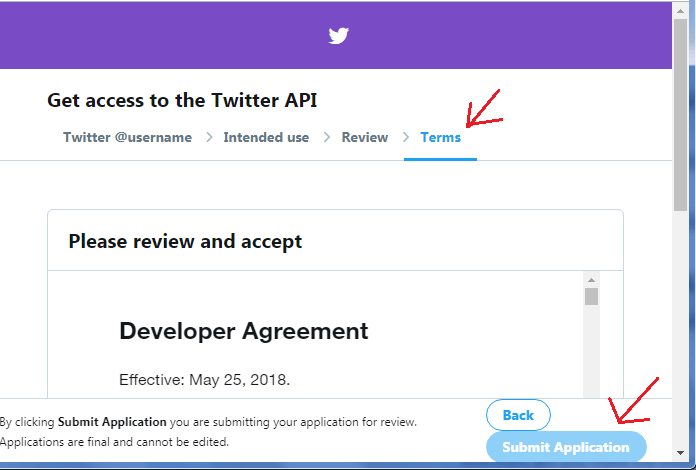
第6步:最后,将要求用户查看并接受开发者协议。通过单击复选框接受协议。通过单击“提交申请”提交申请。
步骤7:成功完成后,将打开一个电子邮件确认页面。使用提供的电子邮件ID进行确认,然后继续进行操作。
步骤8:确认后,将打开一个新网页。点击“创建应用”,如下所示:
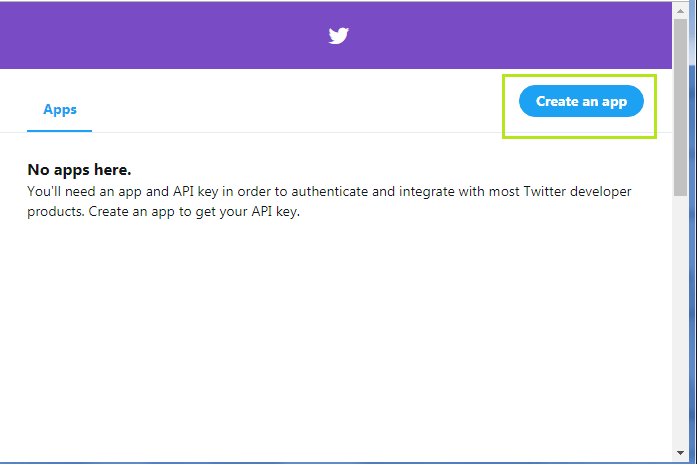
步骤9:提供应用程序详细信息,如以下快照所示:
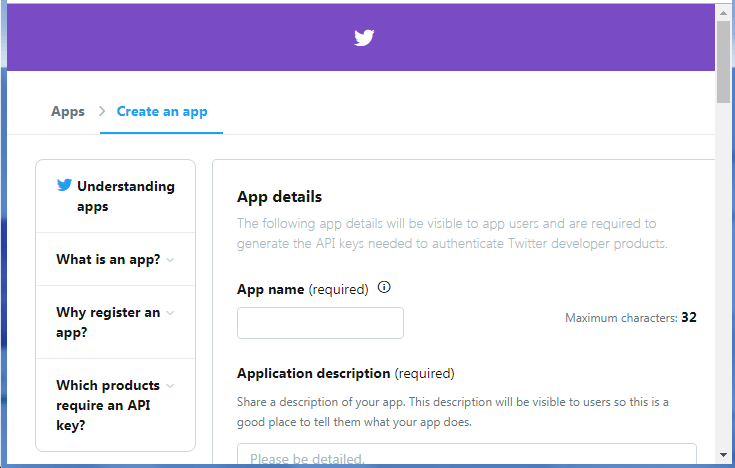
步骤10:在提供应用程序详细信息后,点击“创建”选项。对话框将打开“查看我们的开发人员条款”。点击“创建”选项。快照如下所示:
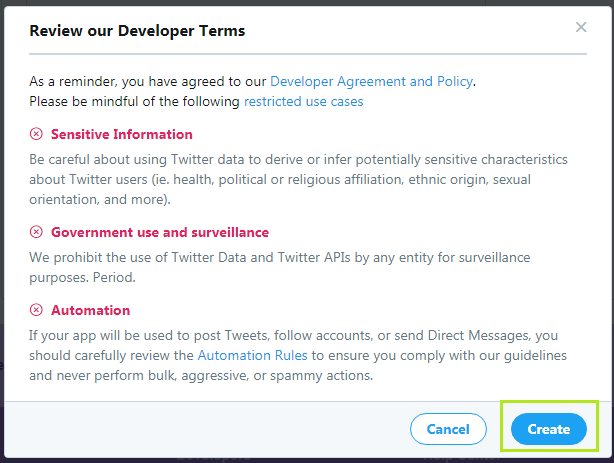
最后,将通过以下方式创建该应用程序:

注意:将在何时创建应用程序。它将生成密钥和令牌。不要泄露它们,因为它们是机密或敏感信息。如果这样做,用户可以出于安全目的对其进行再生。
步骤11:创建应用后,我们需要在’pom.xml’文件中添加twitter依赖项。为此,请在网络浏览器上打开“ github twitter java”。快照如下所示:
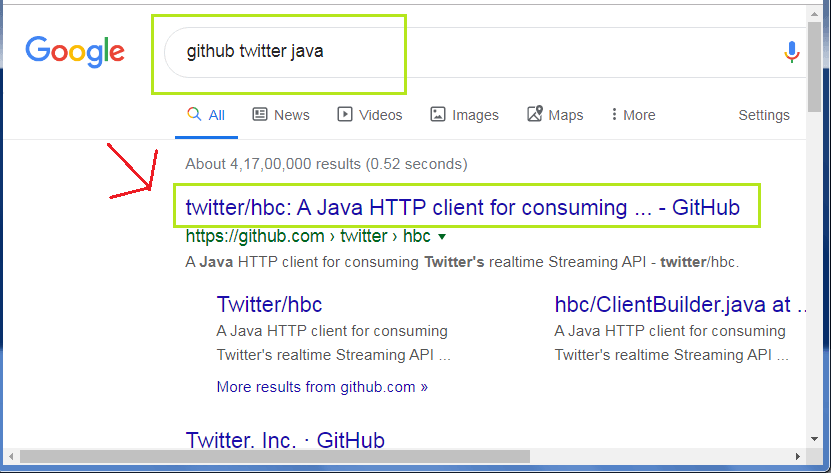
打开突出显示的链接,或访问:’https://github.com/twitter/hbc’直接打开。
步骤12:在那里,用户将找到twitter依赖项代码。复制代码并将其粘贴到maven依赖代码下面的’pom.xml’文件中。
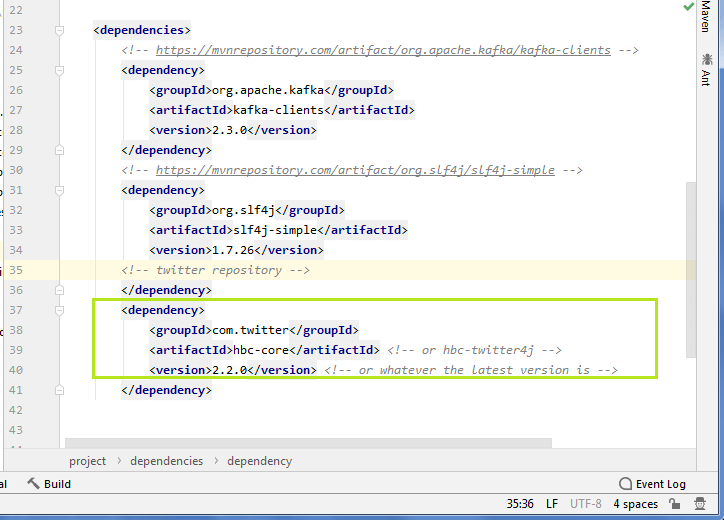
依赖性代码中使用了术语“ hbc”。它代表Java客户端“ Hosebird Client”。它用于使用Twitter的标准流API。 Hosebird客户端分为两个模块:
- hbc-core:它使用消息队列。使用者进一步使用此消息队列来轮询原始字符串消息。
- hbc-twitter4j:这与hbc-core不同,因为它使用了twitter4j侦听器。 Twitter4j是一个非官方的Java库,通过它我们可以轻松地将Java构建应用程序与各种twitter服务集成在一起。
在twitter相关代码中,使用了hbc-core。用户也可以改用twitter4j。
这样,就完成了实时示例的第一阶段。
评论前必须登录!
注册