 srcmini
srcmini毋庸置疑, 一般而言, 搜索引擎会使用相关文档的排名列表来响应给定查询。本文的目的是描述一种针对给定查询查找相关文档的第一种方法。在向量空间模型(VSM)中, 每个文档或查询都是一个N维向量, 其中N是所有文档和查询中不同术语的数量。向量的第i个索引包含第i个分该向量的术语。
主要得分函数基于:术语频率(tf)和文档反向频率(idf)。
术语频率和文档反转频率–
术语频率(
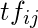
)是针对第i个术语和第j个文档计算的:
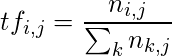
其中
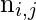
是第j个文档中第i个项的出现。
想法是, 如果文档具有给定术语的多个接收, 则可能会处理该参数。
逆文档频率(
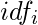
)考虑了第i项和馆藏中的所有文件:
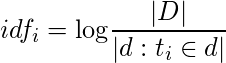
直觉是稀有术语比普通术语更重要:如果某个术语仅存在于文档中, 则可能意味着该术语表征了该文档。
最终成绩
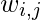
第j个文档中的第i个术语包含一个简单的乘法:
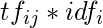
。由于文档/查询仅包含集合中所有不同术语的子集, 因此对于大量术语, 术语频率可以为零:这意味着需要稀疏矢量表示来优化空间需求。
余弦相似度–
为了计算两个向量a, b(文档/查询, 还有文档/文档)之间的相似度, 使用了余弦相似度:
(1)
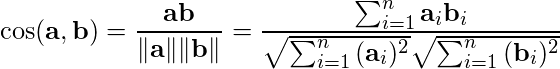
此公式计算两个归一化向量描述的角度的余弦值:如果向量接近, 则角度较小, 相关性较高。
可以证明, 在向量归一化假设下, 余弦相似度与欧几里得距离相同。
改进–
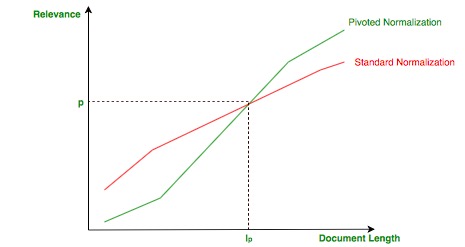
向量规范化存在一个细微的问题:谈论单个主题的简短文档可能会以处理更多主题的长文档为代价而受到青睐, 因为规范化没有考虑文档的长度。
透视归一化的想法是使文档比经验值短(透视长度:
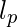
)相关性较低, 而文档较长的相关性更高, 如下图所示:透视归一化
在VSM中没有考虑的一个大问题是同义词:术语之间没有语义相关性, 因为它既没有被术语频率也没有被逆文档频率捕获。为了解决这个问题, 引入了广义矢量空间模型(GVSM)。
评论前必须登录!
注册