 srcmini
srcmini
Python的多功能性是它成为最流行的编程语言之一的主要原因。它被广泛应用于各个学科,从基础物理研究到机器学习(ML)和人工智能(AI)到应用开发。
这种广泛的使用部分是由于一个广泛的标准库,该库提供了一系列旨在增强Python功能和可移植性的工具。这与通过Python Package Index (PyPI)提供的越来越多的包和项目相补充,这些包和项目不仅为更多特定领域的用例提供了Python的扩展能力,而且还提高了Python的一般可用性。从Python包索引中下载的最流行的包列表可以在这里找到。
在本文中,我将重点介绍我的前10个Python包用法示例(所有这些包都可以在PyPI上找到),并提供示例的相应解析。
十大Python包列表(流行且有用)
尽管Python编程有许多不同的用例,但还是有几个包特别有用。无论你是用Python编写ML还是web应用程序,以下10个Python包都是值得了解的,它们只能改善你使用Python的体验。我将以绝对必要的内容开始,以基本内容结束:
1. pip:正如我在前一篇文章中所讨论的,pip是用Python安装和管理包的标准方式。Pip是每个Python发行版的标准配置,允许你通过命令行完成安装、卸载、更新等操作。例如,要从PyPI使用pip安装特定的包,运行以下命令:
pip install “SomePackage”或者对于特定的包版本:
pip install “SomePackage == 1.0”pip允许从多个源进行安装,并且不限于安装在PyPI上维护的包。有关更多信息,请参阅这里的文档。
2. Six: Six是一个Python 2和3的兼容性库,考虑到由于Python 2的终结,许多组织正在进行从Python 2到Python 3的应用程序迁移,这一点尤为重要。Six调和了Python 2和Python 3之间的差异,并根据本地运行的版本进行调整。这使得Python程序员可以轻松地编写与两种Python版本兼容的代码。
例如,在Python 3中,通过以下方式迭代字典键值:
for item in dictionary.items():
#do something在Python 2中,迭代是通过以下方式完成的:
for item in dictionary.iteritems():
#do something使用Six,语法是:
import six
for item in six.iteritems(dictionary):
#do something此代码将在Python 2和3上成功运行。更多的例子可以在文档中找到。
3、python-dateutil: dateutil模块提供了许多日期和时间操作功能,例如计算两个任意日期的相对差异、解析datetime对象和处理时区信息。它构建在Python内建的datetime模块上,并且简单易用。
例如,要获取当前本地时间,Python包用法示例如下:
from datetime import *
from dateutil.relativedelta import *
now = datetime.now()任意添加月、日和小时数:
now + relativedelta(months=1, weeks=1, hour=10)或查询下星期三的时间:
now + relativedelta(weekday=WE(+1))这只是几个例子,但是一般的功能遵循这种趋势。这个包很简单,但是可以显著改善处理时间序列数据时的Python体验。更多信息,可以在这里找到文档。
4. Requests包是一个Python的HTTP库。它构建在urllib3 (Python的另一个HTTP客户端)之上,但语法更简单、更优雅。它还集成了一些其他的Python库,以便在最大化功能的同时尽量减少复杂性。单独使用urllib3(或内置的urllib和urllib2)允许更多的定制和更深入的控制,但也需要用户方面的更多工作。由于这个原因,请求是Python中几乎所有用例的首选HTTP客户端。完整的功能列表可以在这里找到。
例如,下面是如何向Spotify发出请求(不需要身份验证):
import requests
r = requests.get(‘https://api.spotify.com/’)
r.status_code以200为单位的状态码表示成功。从这里我们可以提取头部、编码和无数其他信息:
print(r.headers)
print(r.encoding)5. Docutils:文档实用程序项目的存在是为了创建一组工具,方便地将纯文本文档处理成更有用的文件格式,如HTML、XMS或LaTeX。该项目为最常见的流程开发了几个前端工具。这包括读取输入文件(读取器工具)、进行适当的解析(解析器工具)和编写新文件(写入器工具)。这些工具的命令行语法都遵循一个标准结构:
toolname [options] [<source> [<destination]]在这里可以找到前端工具的完整列表。Docutils是一个功能有限的简单实用程序包;但是这是必要的,因为标准Python库没有提供任何具有这些功能的代码。
6. Setuptools:如前所述,这个列表中的包没有包含在Python的标准发行版中。那么如何分发第三方Python包呢?实现这一功能的内置工具称为distutils,它最初建立了一种用于绑定Python代码的标准方法。
随着第三方包的成熟,就会出现偏离标准的情况,从而允许包本身具有更大的通用性和功能。官方推荐的处理此问题的工具是setuptools。它维护distutils建立的所有功能,扩展到在PyPI上维护的第三方包,甚至是那些不维护的第三方包。它可以很好地与pip和其他Python安装包一起工作。
关于如何创建自己的Python包,文档非常详尽。
一般语法如下:
from setuptools import setup
setup(name=‘package_name’,
version=‘0.1’,
description=‘an example of a package’,
url=‘http://github.com/user/example_package’,
author=‘Dante’,
author_email=‘dante@example.com’,
license=‘MIT’,
packages=[‘example’],
zip_safe=False)7. Pytest:测试代码的保真度不仅是程序员的良好实践,而且使用Pytest也很容易。pytest包提供了一个框架,可以轻松地在任何范围内发现bug。它允许并行测试、测试函数或模块的自动检测、子集测试和其他可定制特性。
一个小测试的例子:
# content of test_sample.py
definc(x):
return x + 1
def>test_answer():
assert inc(3) == 5Pytest很容易从命令行执行:
$ pytest
=========================== test session starts ============================
platform linux — Python 3.x.y, pytest-5.x.y, py-1.x.y, pluggy-0.x.y
cachedir: $PYTHON_PREFIX/.pytest_cache
rootdir: $REGENDOC_TMPDIR
collected 1 item
test_sample.py F [100%]
================================= FAILURES =================================
_______________________________ test_answer ________________________________
def test_answer():
> assert inc(3) == 5
E assert 4 == 5
E + where 4 = inc(3)
test_sample.py:6: AssertionError
============================ 1 failed in 0.12s =============================更多的例子可以在pytest网站上找到。
8. NumPy: NumPy是Python中用于科学和数学计算的基本包。它介绍了n维数组和矩阵,这在执行复杂的数学运算时是必要的。它包含对数组执行基本操作的函数,例如排序、整形和其他数学矩阵操作。
例如,创建两个2×2复杂矩阵并打印其和:
import numpy as np
a = np.array([[1+2j, 2+1j], [3, 4]])
b = np.array([[5, 6+6j], [7, 8+4j]])
print(a+b)取其中一个的共轭复数
np.conj(a)关于如何使用NumPy的更多信息可以在这里找到。
9. Pandas: Pandas包引入了一种新的数据结构,即数据帧,针对表格、多维和异构数据进行了优化。一旦你的数据被转换成这种格式,这个Python包就提供了直观和实用的方法来清理和操作它。
诸如groupby、联接、合并、连接数据或填充、替换和输入空值等操作可以在一行中执行。该程序包的开发人员的主要目标是生产世界上最强大的数据分析和操作工具,它存在于任何语言中——这是一项他们可能真正实现的艰巨任务。
Pandas Python包用法 – 首先创建一个数据帧:
import pandas as pd
df_1 = pd.DataFrame({‘col1’: [1,2], ‘col2’: [3,4]})连接两个数据帧:
df_2 = pd.DataFrame({‘col3’: [5,6], ‘col4’: [7,8]})
df = pd.concat([df_1,df_2], axis = 1)执行一个简单的过滤操作,提取满足逻辑条件的行:
df[df.col3 == 5]更多的例子可以在这里的文档中找到。
10. SciPy包建立在NumPy包的基础上,提供对技术领域的科学计算至关重要的函数和算法。这些操作比内置在NumPy中的操作稍微复杂一些,包括用于插值、优化、聚类、转换和数据集成的算法。在执行任何类型的数据分析或开发基于ml的模型时,这些操作都是必不可少的。
为了演示插值,我首先使用NumPy用任意函数创建一些数据点,然后比较不同的插值方法:
from scipy.interpolate import interp1d
import pylab
x = np.linspace(0, 5, 10)
y = np.exp(x) / np.cos(np.pi * x)
f_nearest = interp1d(x, y, kind=‘nearest’)
f_linear = interp1d(x, y)
f_cubic = interp1d(x, y, kind=‘cubic’)
x2 = np.linspace(0, 5, 100)
pylab.plot(x, y, ‘o’, label=‘data points’)
pylab.plot(x2, f_nearest(x2), label=‘nearest’)
pylab.plot(x2, f_linear(x2), label=‘linear’)
pylab.plot(x2, f_cubic(x2), label=‘cubic’)
pylab.legend()
pylab.show()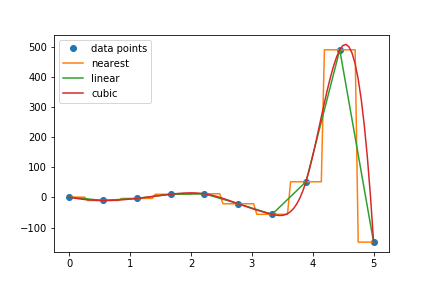
结论
如果仅通过下载统计数据来客观地衡量PyPI上最流行的包,你将得到一个功能非常多样的Python包列表。有些包的存在仅仅是为了改进Python语言本身,而另一些包只对那些为了特定目的使用Python的人有利,比如开发ML模型或与Amazon Web服务一起使用。
相反,我列出的前10个Python包都是有用的,不管用例是什么。无论你使用Python的目的是什么,这些Python包用法示例中的每一个都对改进你的Python编程体验至关重要,并将立即让你成为一名更高效的程序员。尝试一下,自己看看。
所有10个包都可以在ActiveState平台上获得,可以包含在你的运行时环境中。然而,只有少数(如NumPy和SciPy)包含C代码。ActiveState的一个关键优势是它的“按需构建环境”功能,允许你从源代码构建包含C代码的包,而不需要设置自己的环境或创建自己的编译器。如果代码来源对你的组织有价值,ActiveState平台可以帮助你减少在寻找和构建运行时上花费的时间和资源。
在Activstate的平台上Fork“十大Python包”项目。你可以在一个可下载的版本中预先编译这10个包!
评论前必须登录!
注册