 srcmini
srcminiPandas是一个Python软件包, 提供了各种数据结构和操作, 用于处理数字数据和时间序列。它主要是很容易导入和分析数据的流行。这是一个在NumPy库之上构建的开源库。
groupby()
Pandas dataframe.groupby()函数用于根据给定条件将数据帧中的数据分为几组。
范例1:
# import library
import pandas as pd
# import csv file
df = pd.read_csv( "https://bit.ly/drinksbycountry" )
df.head()输出如下:
范例2:
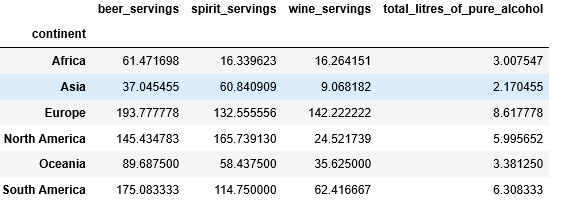
# Find the average of each continent
# by grouping the data
# based on the "continent".
df.groupby([ "continent" ]).mean()输出如下:
agg()
Pandas dataframe.agg()函数用于基于指定的轴对数据执行一项或多项操作
例子:
# here sum, minimum and maximum of column
# beer_servings is calculatad
df.beer_servings.agg([ "sum" , "min" , "max" ])输出如下:

一起使用这两个功能:我们可以找到特定列的另一列的多个聚合函数。
例子:
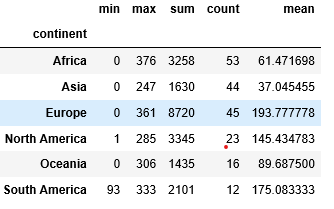
# find an aggregation of column "beer_servings"
# by grouping the "continent" column.
df.groupby(df[ "continent" ]).beer_servings.agg([ "min" , "max" , "sum" , "count" , "mean" ])输出如下:
首先, 你的面试准备可通过以下方式增强你的数据结构概念:Python DS课程。
评论前必须登录!
注册