 srcmini
srcmini为了实现动态多级索引, B树通常使用B+树。但是, 用于索引的B树的缺点是, 它将与特定键值相对应的数据指针(指向包含键值的磁盘文件块的指针)与该键值一起存储在B的节点中-树。该技术极大地减少了可以打包到B树的节点中的条目数, 从而有助于增加B树中的级别数, 从而增加了记录的搜索时间。
B+树通过仅在树的叶节点处存储数据指针来消除上述缺点。因此, B+树的叶节点的结构与B树的内部节点的结构完全不同。在这里应该注意, 由于数据指针仅存在于叶节点, 因此叶节点必须必须将所有键值及其对应的数据指针存储到磁盘文件块, 以便访问它们。此外, 叶节点被链接以提供对记录的有序访问。因此, 叶节点形成第一级索引, 而内部节点形成多级索引的其他层。叶子节点的某些关键值也出现在内部节点中, 以简单地充当控制记录搜索的媒介。
从以上讨论可以明显看出, 与B树不同, B+树具有两个顺序:” a”和” b”, 一个用于内部节点, 另一个用于外部(或叶)节点。
顺序为” a”的B+树的内部节点的结构如下:
每个内部节点的格式为:
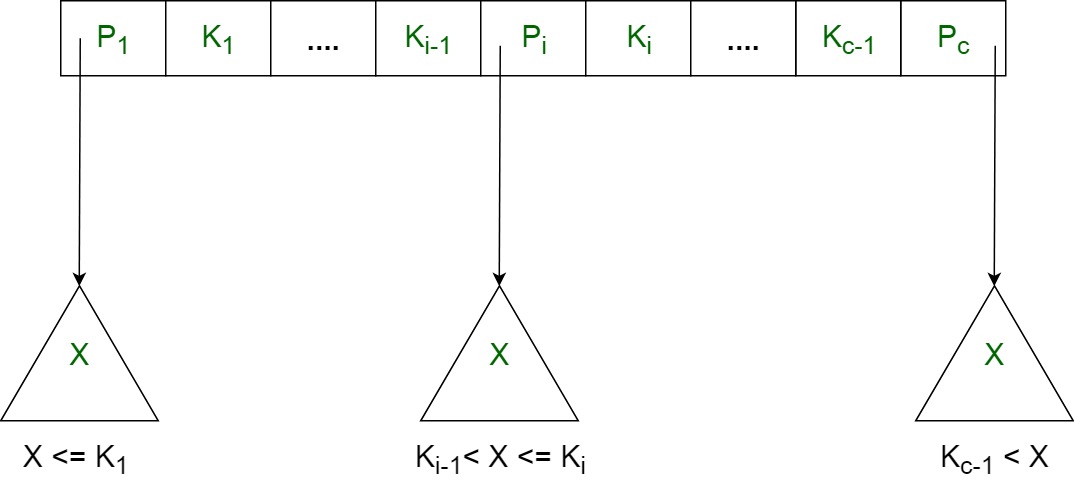
<P1, K1, P2, K2, ….., Pc-1, Kc-1, Pc>
其中c <= a并且每个Pi是一个树指针(即指向树的另一个节点),每个Ki是一个键值(参考图i)。
每个内部节点都具有: K1 < K2 < …. < Kc-1
对于Pi指向的子树中的每个搜索字段值’ X ‘,以下条件成立:
Ki-1 < X <= Ki,对于1 < i < c,
i = c时,Ki-1 < X
(参考图一)
每个内部节点最多具有一个” a”树指针。
根节点至少具有两个树指针, 而其他内部节点每个都至少具有\ ceil(a/2)树指针。
如果任何内部节点具有” c”个指针, c <= a, 则其具有” c – 1″个键值。
图一
顺序为” b”的B+树的叶节点的结构如下:
- 每个叶节点的形式为:
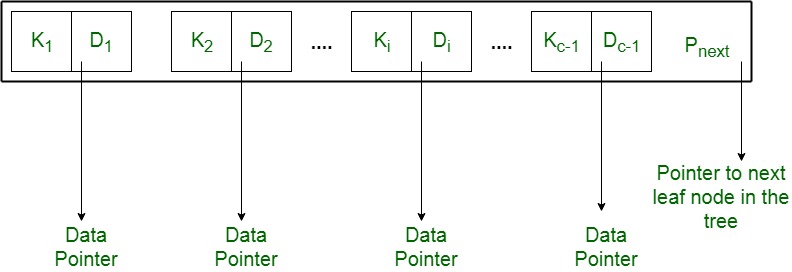
<< K1, D1>, <K2, D2>, ….., <K1一, D1一>, P下一个>
其中c <= b且每个d一世是数据指针(即指向磁盘中键值为K的实际记录一世或包含该记录的磁盘文件块)并且, 每个ķ一世是关键价值和, P下一个指向B+树中的下一个叶子节点(参考图二)。 - 每个叶节点都具有:K1<K2<…。 <K1一, c <= b
- 每个叶节点至少具有\ ceil(b / 2)值。
- 所有叶节点处于同一级别。
图二
使用P下一个指针, 遍历所有叶节点(就像链表一样)是可行的, 从而实现对存储在磁盘中的记录的有序访问。
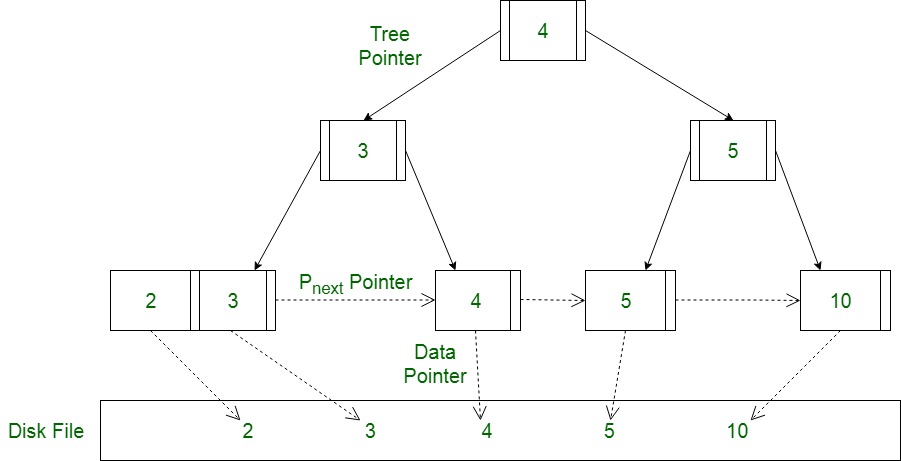
B+树图–
优势–
与具有相同” l”级的B树相比, 具有” l”级的B+树可以在其内部节点中存储更多条目。这突出了对任何给定关键字的搜索时间的显着改进。较低的水平和P的存在
下一个
指针暗示B+树从磁盘访问记录非常快速有效。
评论前必须登录!
注册