 srcmini
srcmini模板匹配是一种图像处理技术, 用于查找大图像的小部分/模板的位置。此技术广泛用于对象检测项目, 例如产品质量, 车辆跟踪, 机器人等。
在本文中, 我们将学习如何使用模板匹配来检测文档图像中的相关字段。
解:
以上任务可以通过模板匹配来实现。剪切出场图像并使用剪切的场图像和文档图像应用模板匹配。该算法很简单, 但是可以复制为复杂的版本, 以解决对属于特定域的文档图像进行字段检测和本地化的问题。
方法:
- 从主文档中剪切/裁剪字段图像, 并将它们用作单独的模板。
- 定义/调整不同字段的阈值。
- 使用OpenCV功能为每个裁剪的田地模板应用模板匹配cv2.matchTemplate()
- 使用从模板匹配中获取的矩形的坐标绘制边界框。
- 可选:增强字段模板和微调阈值, 以改善不同文档图像的结果。
输入图片:

输出图像:
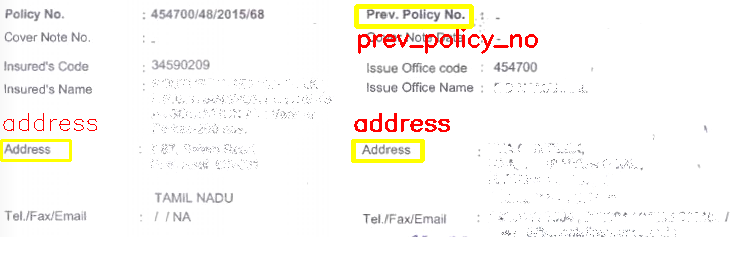
以下是Python代码:
# importing libraries
import numpy as np
import imutils
import cv2
field_threshold = { "prev_policy_no" : 0.7 , "address" : 0.6 , }
# Function to Generate bounding
# boxes around detected fields
def getBoxed(img, img_gray, template, field_name = "policy_no" ):
w, h = template.shape[:: - 1 ]
# Apply template matching
res = cv2.matchTemplate(img_gray, template, cv2.TM_CCOEFF_NORMED)
hits = np.where(res> = field_threshold[field_name])
# Draw a rectangle around the matched region.
for pt in zip ( * hits[:: - 1 ]):
cv2.rectangle(img, pt, (pt[ 0 ] + w, pt[ 1 ] + h), ( 0 , 255 , 255 ), 2 )
y = pt[ 1 ] - 10 if pt[ 1 ] - 10> 10 else pt[ 1 ] + h + 20
cv2.putText(img, field_name, (pt[ 0 ], y), cv2.FONT_HERSHEY_SIMPLEX, 0.8 , ( 0 , 0 , 255 ), 1 )
return img
# Driver Function
if __name__ = = '__main__' :
# Read the original document image
img = cv2.imread( 'doc.png' )
# 3-d to 2-d conversion
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Field templates
template_add = cv2.imread( 'doc_address.png' , 0 )
template_prev = cv2.imread( 'doc_prev_policy.png' , 0 )
img = getBoxed(img.copy(), img_gray.copy(), template_add, 'address' )
img = getBoxed(img.copy(), img_gray.copy(), template_prev, 'prev_policy_no' )
cv2.imshow( 'Detected' , img)使用模板匹配的优点
:
- 计算便宜。
- 易于使用, 并可针对不同用例进行修改。
- 在文档数据不足的情况下给出良好的结果。
缺点:
- 与使用深度学习的细分技术相比, 结果的准确性不是很高。
- 缺少重叠模式问题的解决方案。
首先, 你的面试准备可通过以下方式增强你的数据结构概念:Python DS课程。
评论前必须登录!
注册